






本文利用PyTorch建立一个多层感知模型, 来分类iris数据集。
目录
导入数据
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
X = iris['data']
y = iris['target']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 1./3, random_state=1)三分之二的数据用于训练, 三分之一的用于test.
建立PyTorch DataSet:
import numpy as np
import torch
from torch.utils.data import TensorDataset, DataLoader
X_train_norm = (X_train - np.mean(X_train)) / np.std(X_train)
X_train_norm = torch.from_numpy(X_train_norm).float()
y_train = torch.from_numpy(y_train)
train_ds = TensorDataset(X_train_norm, y_train)
batch_size = 2
train_dl = DataLoader(train_ds, batch_size, shuffle=True)建立模型: 模型有两层NN
import torch.nn as nn
class Model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.layer1 = nn.Linear(input_size, hidden_size)
self.layer2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.layer1(x)
x = nn.Sigmoid()(x)
x = self.layer2(x)
x = nn.Softmax(dim=1)(x)
return x
input_size = X_train_norm.shape[1]
hidden_size = 16
output_size = 3
model = Model(input_size, hidden_size, output_size)iris 数据集 有三种花, 所以output_size = 3,
隐藏层 定义了16个 节点。
第一层后 用sigmoid函数激活。
第二层后 用softmax函数 分类。
定义损失函数, 以及optimizer
learning_rate = 0.001
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)训练模型
num_epochs = 100
loss_hist = [0] * num_epochs
accuracy_hist = [0] * num_epochs
for epoch in range(num_epochs):
for x_batch, y_batch in train_dl:
#预测 output
pred = model(x_batch)
#计算损失
loss = loss_fn(pred, y_batch)
#计算梯度
loss.backward()
#更新权重
optimizer.step()
#梯度归0
optimizer.zero_grad()
loss_hist[epoch] += loss.item() * y_batch.size(0)
is_correct = (torch.argmax(pred, dim=1) == y_batch).float()
accuracy_hist[epoch] += is_correct.sum()
loss_hist[epoch] /= len(train_dl.dataset)
accuracy_hist[epoch] /= len(train_dl.dataset)loss_hist 与 accuracy_hist中储存了每个epoch的 loss 与 accuracy
X_test_norm = (X_test - np.mean(X_train)) / np.std(X_train)
X_test_norm = torch.from_numpy(X_test_norm).float()
y_test = torch.from_numpy(y_test)
pred_test = model(X_test_norm)
correct = (torch.argmax(pred_test, dim=1) ==y_test).float()
accuracy = correct.mean()
print(f'Test ACC: {accuracy:.4f}')
Test ACC: 0.9800画出loss 与 accuracy
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(12, 5))
ax = fig.add_subplot(1, 2, 1)
ax.plot(loss_hist, lw=3)
ax.set_xlabel('epoch', size=15)
ax.tick_params(axis='both', which='major', labelsize=15)
ax = fig.add_subplot(1, 2, 2)
ax.plot(accuracy_hist, lw=3)
ax.set_title('Training accuracy', size=15)
ax.set_xlabel('Epoch', size=15)
ax.tick_params(axis='both', which='major', labelsize=15)
plt.show()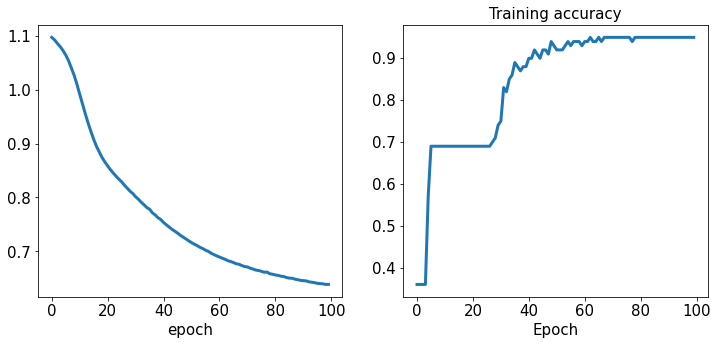
在test 数据集上检测:
X_test_norm = (X_test - np.mean(X_train)) / np.std(X_train)
X_test_norm = torch.from_numpy(X_test_norm).float()
y_test = torch.from_numpy(y_test)
pred_test = model(X_test_norm)
correct = (torch.argmax(pred_test, dim=1) ==y_test).float()
accuracy = correct.mean()
print(f'Test ACC: {accuracy:.4f}')
Test ACC: 0.9800保存训练的模型
save_path = 'iris_classifier.pt'
torch.save(model, save_path)载入保存的模型
model_new = torch.load(save_path)来看看模型的结构:
model_new.eval()
Model(
(layer1): Linear(in_features=4, out_features=16, bias=True)
(layer2): Linear(in_features=16, out_features=3, bias=True)
)利用载入的模型 预测:
pred_test = model_new(X_test_norm)
correct = (torch.argmax(pred_test, dim=1) == y_test).float()
accuracy = correct.mean()
print(f"Test accuracy: {accuracy:.4f}")
Test accuracy: 0.9800只保存 训练得到的参数:
path = 'iris_classifier_state.pt'
torch.save(model.state_dict(), path)在模型中载入保存的参数:
model_new = Model(input_size, hidden_size, output_size)
model_new.load_state_dict(torch.load(path))
<All keys matched successfully>参考自: Machine Learning with PyTorch and Scikit-Learn Book by Sebastian Raschka

















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









