







启发函数 (Heuristic Function)
盲目搜索会浪费很多时间和空间, 所以我们在路径搜索时, 会首先选择最有希望的节点, 这种搜索称之为 "启发式搜索 (Heuristic Search)"
如何来界定"最有希望"? 我们需要通过 启发函数 (Heuristic Function) 计算得到.
对于网格地图来说, 如果只能四方向(上下左右)移动, 曼哈顿距离(Manhattan distance) 是最合适的启发函数.
function Manhattan(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
// 在最简单的情况下, D 可以取 1, 返回值即 dx + dy
return D * (dx + dy)
如果网格地图可以八方向(包括斜对角)移动, 使用 切比雪夫距离(Chebyshev distance) 作为启发函数比较合适.
function Chebyshev(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
// max(dx, dy) 保证了斜对角的距离计算
return D * max(dx, dy)
如果地图中允许任意方向移动, 不太建议使用网格 (Grid) 来描述地图, 可以考虑使用 路点 (Way Points) 或者 导航网格 (Navigation Meshes) , 此时使用 欧式距离(Euclidean distance) 来作为启发函数比较合适.
function heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
// 在最简单的情况下, D 可以取 1, 返回值即 sqrt(dx * dx + dy * dy)
return D * sqrt(dx * dx + dy * dy)
欧式距离因为有一个 sqrt() 运算, 计算开销会增大, 所以可以使用 Octile 距离 来优化(不知道怎么翻译), Octile 的核心思想就是假定只能做 45 度角转弯.
function heuristic(node) =
dx = abs(node.x - goal.x)
dy = abs(node.y - goal.y)
k = sqrt(2) - 1
return max(dx, dy) + k * min(dx, dy)
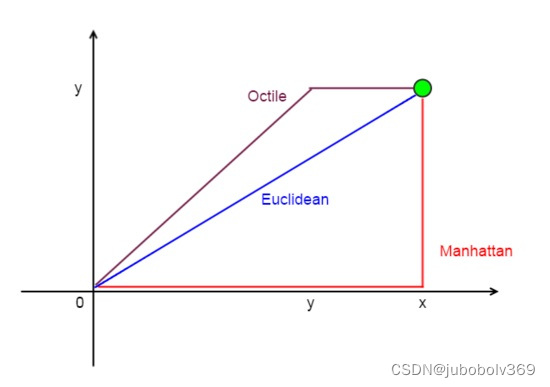
下图是一个启发函数的简单示意
Dijkstra
Dijkstra 算法 是由计算机大牛 Dijkstra 在1956年提出来的, 它是一个"精确"的寻路算法, 能保证发现节点之间的最短路径, 本质是一个 广度优先搜索 .
- g(n): 从起始点到当前点 n 的开销, 在网格地图中一般就是步长.
- 将起始点 S 加入 open-list.
- 从当前的 open-list 中选取 g(n) 最优(最小)的节点 n, 加入 closed-list
- 遍历 n 的后继节点 ns
- 如果 ns 是新节点, 加入 open-list
- 如果 ns 已经在 open-list 中, 并且当前 h(ns) 更优, 则更新 ns 并修改 parent
- 迭代, 直到找打目标节点 D, 回溯得到路径
Dijkstra 算法的效率并不高, 时间复杂度为 O(n^2), 但是它保证了寻路结果是最短距离.
Best-First-Search
Best-first Search 最佳优先搜索, 简称为 BFS.
BFS 根据启发式函数的推断, 每次迭代最优的节点, 直到寻找到目标节点. 一个简单的算法流程如下:
- h(n) 代表从当前点 n 到目标点 S 的估算开销, 即启发函数.
- 将起始点 S 加入 open-list.
- 从当前的 open-list 中选取 h(n) 最优(最小)的节点 n, 加入 closed-list
- 遍历 n 的后继节点 ns
- 如果 ns 是新节点, 加入 open-list
- 如果 ns 已经在 open-list 中, 并且当前 h(ns) 更优, 则更新 ns 并修改 parent
- 迭代, 直到找打目标节点 D, 回溯得到路径
如果不使用 open-list, 直接每次都寻找 n 的后继节点中最优的节点, BFS 则退化为贪心最佳优先搜索 (Greedy BFS).
不管是 BFS 还是 Greedy-BFS, 本质上都还是寻找 局部最优 , 虽然效率会比 Dijkstra 高很多, 但最终得到的解并不一定是全局最优(最短距离), 在地图中有障碍物时尤为明显.
A-Star
A-Star 俗称 A* , 是应用最广的寻路算法, 在很多场景下都适用. A* 兼顾了 Dijkstra 的准确度和 BFS 的效率.
- f(n) = g(n) + h(n) , g(n) 和 h(n) 的定义同上
- 当 g(n) 退化为 0, 只计算 h(n) 时, A* 即退化为 BFS.
- 当 h(n) 退化为 0, 只计算 g(n) 时, A* 即退化为 Dijkstra 算法.
- 将起始点 S 加入 open-list.
- 从当前的 open-list 中选取 f(n) 最优(最小)的节点 n, 加入 close-list
- 遍历 n 的后继节点 ns
- 如果 ns 是新节点, 加入 open-list
- 如果 ns 已经在 open-list 中, 并且当前 f(ns) 更优, 则更新 ns 并修改 parent
- 迭代, 直到找打目标节点 D.
A* 算法在从起始点到目标点的过程中, 尝试平衡 g(n) 和 h(n), 目的是找到最小(最优)的 f(n) .
A-Star 算法衍生
如果在每一步迭代扩展中, 都去除掉质量比较差的节点, 即选取 有限数量的后继节点 , 这样减少了空间开销, 并提高了时间效率. 但是缺点可能会丢弃潜在的最佳方案. 这就是 集束搜索(Beam Search) , 本质上还是局部最优的贪心算法.
当距离起点越近, 快速前行更重要; 当距离目标点越近, 到达目标更重要. 基于这个原则, 可以引入权重因子, A* 可以演进为选取 f(n) = g(n) + w(n) * h(n) 最优的点, w(n) 表示在点 n 的权重. w(n) 随着当距离目标点越近而减小. 这是 动态加权 A* (Dynamic Weighting A*) .
当从出发点和目标点同时开始做双向搜索, 可以利用并行计算能力, 更快的获得计算结果, 这是 双向搜索 (Bidirectional Search) . 此时, 向前搜索 f(n) = g(start, n) + h(n, goal), 向后搜索 f(m) = g(m, goal) + h(start, m), 所以双向搜索最终可以归结为选取 g(start, n) + h(m, n) + g(m, goal) 最优的一对点(m, n).
A* 在静态地图中表现很棒, 但是在动态环境中(例如随机的障碍物), 却不太合适, 一个基于 A* 算法的 D* 算法(D-Star, Dynamic A*) 能很好的适应这样的动态环境. D* 算法中, 没有 g(n), f(n) 退化为 h(n), 但是每一步 h(n) 的计算有所不同: h(n) = h(n-1) + h(n-1, n) , c(n-1, n) 表示节点 n-1 到节点 n 的开销.


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











