







1. GPU 架构

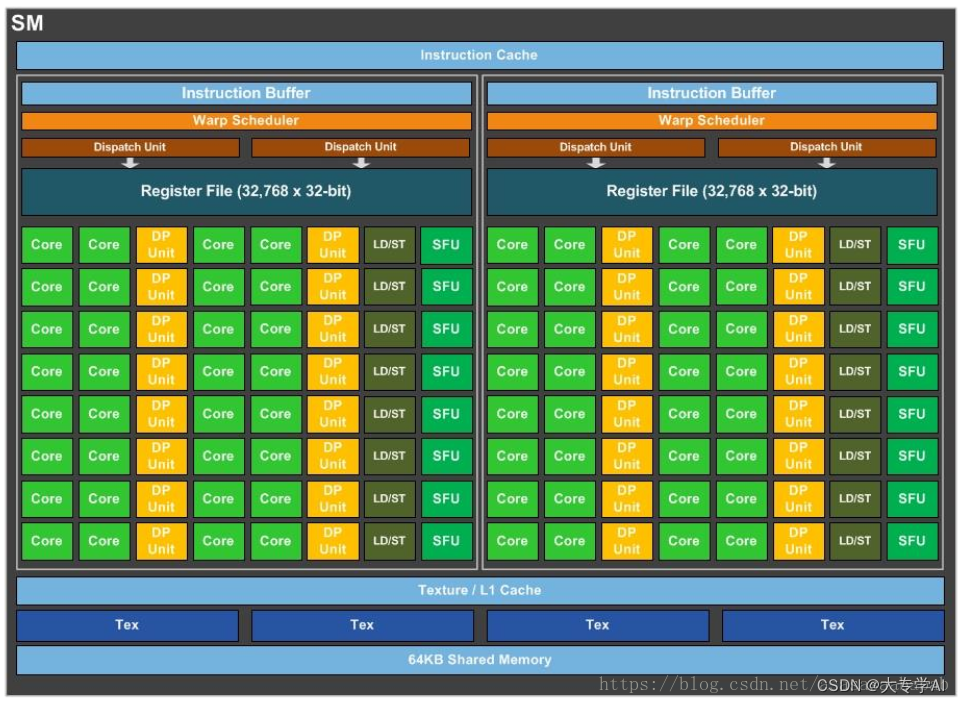
- 这篇博客讲的很好了
https://blog.csdn.net/asasasaababab/article/details/80447254 - CUDA Core: 表示在GPU设备上执行的核心数量,表示在GPU设备上执行的核心数量
- CUDA SM: Streaming Multiprocessor, SM是一个独立的处理器单元,具有自己的流处理器和寄存器文件,可以同时执行多个线程。在一个GPU中可能会有多个SM,每个SM可以同时执行许多线程。
- CUDA SMP: SMP是一种硬件特性,允许在同一时刻在一个SM上执行多个并发内核。SMP的存在可以提高GPU的并行处理能力,使得GPU能够处理更多的任务。
- 博主以GP 100为案例这个GPU上有68块SM 每个SM有2个SMP,每个SMP有32个CUDA core(一个warp size), 也是最小的的调度单位是32core一起调度
- 每个SMP有16个DP Unit (Double Precision) 双精度的
- 双精度(double-precision)是一种数据类型,它使用64位(8字节)来存储一个数值。它可以表示比单精度(float)类型更大的数值范围和更高的精度。在CUDA中,DP通常指的是双精度浮点数运算,即使用64位浮点数进行计算。由于双精度浮点数需要更多的存储空间和更复杂的运算过程,因此在计算密集型的任务中可能会对性能造成一定的影响。
- SM的单精度处理能力与双精度处理能力的比例通常在2:1到4:1之间。
2. GPU内存架构
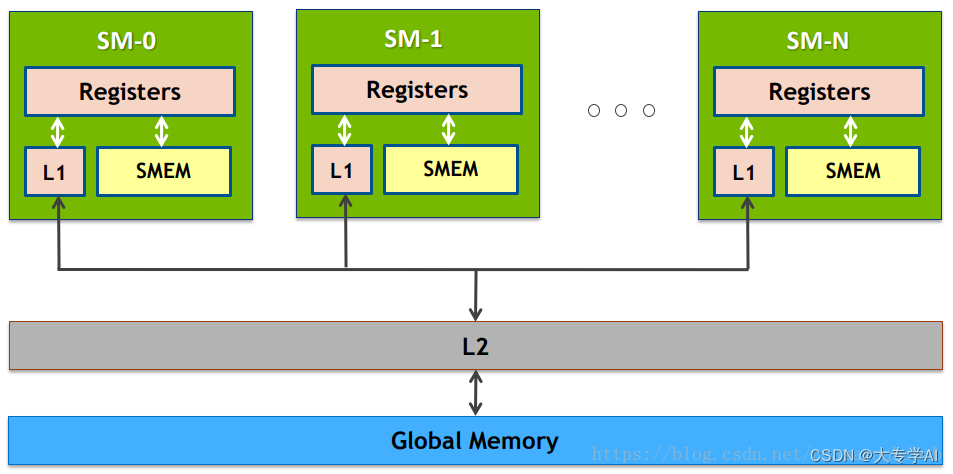
- 寄存器(Register)是计算机内部一种非常快速的存储设备,它通常用来暂时存放计算机正在运算的数据和指令,以及存储函数调用时需要保存的状态信息。寄存器是计算机体系结构中最快的存储设备,由于它们位于CPU内部,因此可以在一个CPU周期内完成数据的读写操作,因此被广泛应用于CPU的优化和加速。速度快但是内存小,CPU直接在寄存器上面跑
- L1缓存是位于每个流多处理器(SM)内部的缓存,它存储了最近使用的内存数据和指令,以供下一次访问时快速获取。L1缓存速度非常快,但它的大小通常较小。
- L2缓存是位于整个GPU芯片上的缓存,它存储了未被L1缓存所缓存的数据。L2缓存的速度比L1慢,但它的大小通常比L1大很多。L2缓存对于一些大型内存操作比如矩阵乘法和卷积操作是非常有用的,可以显著提高内存访问的效率。
- SMEM指的是Shared Memory,也叫做共享内存。Shared Memory是一种高速的、低延迟的内存,位于GPU的每个Streaming Multiprocessor(SM)内部,是一个供多个线程共享的内存空间。相比于全局内存,Shared Memory的读写速度更快,因为它在同一个SM内部,可以直接通过寄存器和数据缓存访问。
- 简单点理解: 离SM越近越快,不同的缓存速度不一样
3. CPU对比GPU
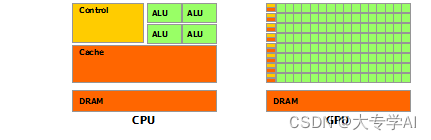
- GPU控制单元很少,GPU该干计算的活,不是拿来干逻辑的活(if else)
- 比较适合拿来搞并行比较高的东西
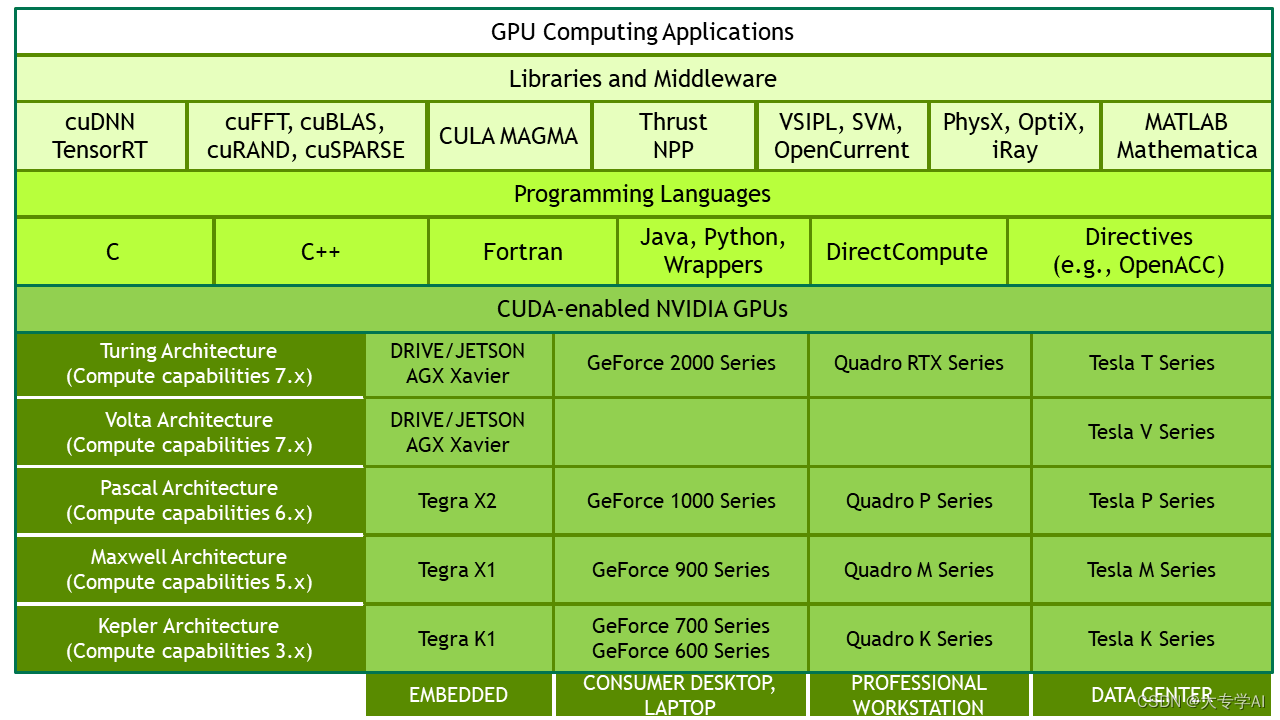
4. NVIDIA 不同结构
5. 写第一个CUDA小程序
- 装CUDA
- 把我自己写好的模板下载下来git clone https://github.com/PredyDaddy/Makefile_Template.git
- 安装vscode-cudacpp插件
- vscode把makefile的头文件加进去
#include <iostream>
#include <cuda_runtime.h>
#include <device_launch_parameters.h>
__global__ void compute(float* a, float* b, float* c)
{
int position = threadIdx.x;
c[position] = a[position] * b[position];
}
__device__ float sigmoid(float sigmoid)
{
return 1 / (1 + exp(-value));
}
int main()
{
// 定义3个数组
const int num = 3;
float a[num] = {1, 2, 3};
float b[num] = {5 ,7 ,9};
float c[num] = {0};
// 定义三个设备指针,device指针
size_t size_array = sizeof(c);
float* device_a = nullptr;
float* device_b = nullptr;
float* device_c = nullptr;
// 分配设备空间,大小是size_array, 单位是byte
cudaMalloc(&device_a, size_array);
cudaMalloc(&device_b, size_array);
cudaMalloc(&device_c, size_array);
// 把数据冲host复制到device,其实就是主机复制到显卡
// 复制的是a, b
cudaMemcpy(device_a, a, size_array, cudaMemcpyHostToDevice);
cudaMemcpy(device_b, b, size_array, cudaMemcpyHostToDevice);
// 执行核函数,把结果放在c上
compute<<<1, 3>>>(device_a, device_b, device_c);
// 把计算后的结果c复制回主机上
cudaMemcpy(c, device_c, size_array, cudaMemcpyDeviceToHost);
// 查看主机上的c内容是多少
for (int i = 0; i < num; ++i)
printf("c[%d] = %f\n", i, c[i]);
return 0;
}
6. CUDA核函数
- __global__核函数
- 使用__global__修饰函数而且必须是void无返回值的才行
- 必须是nvcc编译才有效,否则无效
__global__函数执行在主机启动设备上执行__global__修饰的函数,使用name<<<grid, block, memory>>>(params)启动核函数
__device__修饰的是设备可见,host不可见
- 不能够使用func<<<1, 3>>>, sigmoid(0.5) 这种方式启动
- 只能够在核函数内调用
- nvidia提供了很多内置设备函数,例如cos, sin
- 不同内置函数的api接口版本号,被称之为计算能力
__host__函数执行调用都在Host上
7. grid和block初探
- 定义在#include <device_launch_parameters.h>这个头文件里面包含好了
- vscode中cpp文件才有语法解析,才能点进去看,头文件没加进json文件也看不到
- 不用删除原有的头文件路径,是可以多加的
- block跟Dim都是uint 3,记住是有x , y, z就可以了
uint3 __device_builtin__ __STORAGE__ threadIdx;
uint3 __device_builtin__ __STORAGE__ blockIdx;
dim3 __device_builtin__ __STORAGE__ blockDim;
dim3 __device_builtin__ __STORAGE__ gridDim;
int __device_builtin__ __STORAGE__ warpSize;
8. layout
- Layout概念:
- 虚拟的概念,通过cuda驱动实现真实硬件映射,抽象了一个中间层(调度层,调度线程)
- 启动的线程会被设计为grid, block, 如同提供的参数一样
- 案例:
- 如果有4352个core,但是需要启动5000个线程
- 抽象的layout层/调度层会把5000个线程安排到各个core中执行,也就是说不一定是同步的可能是异步的
- 每次调度的单位仍然是WarpSize,如果线程小于core,部分core是非激活状态
- 线程数 = gridDim.x * gridDim.y * gridDim.z * blockDim.x * blockDim.y * blockDim.z
- 通过设置不同的gird和block来告诉机器我有多少个线程,我们的设计根据CUDA去设计可以获得最好的性能
- 所以设计这个不能随便乱给,grid Dim (x, y, z) : (2147483647, 65535, 65535) = 2^31
- 2147483647 有符号整数(int)的最大值
- 65535 无符号整数的最大值(int 16, short)
- blockDim (x, y, z) : (1024, 1024, 64)
compute<<<1, 3>>>
- gridDim = 1x1x1
- blockDim = 3x1x1
9. grid, block shape索引
- 获取线程ID,进行数据操作:
- 数据索引: 通过blockIdx,threadIdx计算得到
- gridDim,blockDim可知grid,block的shape
- 想象每一个gird是个三维的tensor,每个元素是一个block,而block也想象成三维度的tensor,每个元素是thread
- 想象grid, block组成了一个六维度的tensor,每个元素是一个thread
- blockIdx得到在grid内的索引,threadIdx得到在block内的索引
- gridDim.shape = gridDim.z * gridDim.y * gridDim.x (通道,行,高)
- blockDim.shape = blockDim.z * blockDim.y * blockDim.x (通道,行,高)
- 最终的shape (线程数) = gridDim.x * gridDim.y * gridDim.z * blockDim.x * blockDim.y * blockDim.z
- 如果启动的线程是6维度的tensor, 那么索引,类似:
- blockIdx.z, blockIdx.y, blockIdx.z, threadIdx.z, threadIdx.y, threadIdx.x
- 在这个场景把6个维度的索引变为连续的单元索引:
- 如果我们
有3个维度a, b, c, d, e, f
有3个位置索引u, v, w, x, y, z
position = ((((u * b + v) * c + w) * d + x) * e + y) * f + z















 5315
5315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









