









二部图及其最大匹配:
二部图:对于无向图G(V,E),若能将其顶点分成V1,V2两个不相交的非空子集,使得G中的任何一条边的两个端点一个属于V1,另一个属于V2,那么该图就称为二部图。
性质:一个无向图G(V,E)是二部图当且仅当G中不存在长度为奇数的回路。
匹配:在图论中,一个「匹配」(matching)是一个边的集合,其中任意两条边都没有公共顶点。例如,图 3、图 4 中红色的边就是图 2 的匹配。
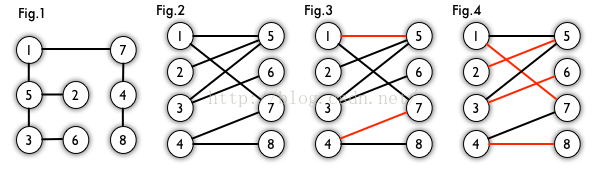
最大匹配:一个图所有匹配中,所含匹配边数最多的匹配,称为这个图的最大匹配。图 4 是一个最大匹配,它包含 4 条匹配边。
完美匹配:如果一个图的某个匹配中,所有的顶点都是匹配点,那么它就是一个完美匹配。图 4 是一个完美匹配。显然,完美匹配一定是最大匹配(完美匹配的任何一个点都已经匹配,添加一条新的匹配边一定会与已有的匹配边冲突)。但并非每个图都存在完美匹配。
匈牙利算法求解最大匹配:
思路: 算法的思路是不停的找增广路径,并增加匹配的个数,增广路径顾名思义是指一条可以使匹配数变多的路径,在匹配问题中,增广路径的表现形式是一条"交错路径",也就是说这条由图的边组成的路径,它的第一条边是目前还没有参与匹配的,第二条边参与了匹配,第三条边没有..最后一条边没有参与匹配,并且始点和终点还没有被选择过。这样交错进行,显然他有奇数条边。那么对于这样一条路径,我们可以将第一条边改为已匹配,第二条边改为未匹配...以此类推。也就是将所有的边进行"反色",容易发现这样修改以后,匹配仍然是合法的,但是匹配数增加了一对。可以知道,当图中找不到增广路时,就得到了改图的最大匹配。
交替路:从一个未匹配点出发,依次经过非匹配边、匹配边、非匹配边...形成的路径叫交替路。
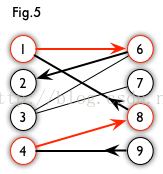
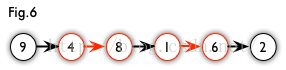
增广路:从一个未匹配点出发,走交替路,如果途径另一个未匹配点(出发的点不算),则这条交替路称为增广路(agumenting path)。例如,图 5 中的一条增广路如图 6 所示(图中的匹配点均用红色标出)
增广路的特点:在一条增广路中, 未匹配的边总是比匹配的边多一条,
所以可以通过修改边将增广路中匹配的边都换成未匹配的边,这每找到一条增广路,匹配就增加一个。如此往复,当找不到增广路,就得到了二分图的最大匹配.
匈牙利算法的模板:
/* **************************************************************************
//二分图匹配(匈牙利算法的DFS实现)
//初始化:g[][]两边顶点的划分情况
//建立g[i][j]表示i->j的有向边就可以了,是左边向右边的匹配
//g没有边相连则初始化为0
//uN是匹配左边的顶点数,vN是匹配右边的顶点数
//调用:res=hungary();输出最大匹配数
//优点:适用于稠密图,DFS找增广路,实现简洁易于理解
//时间复杂度:O(VE)
//***************************************************************************/
//顶点编号从0开始的
const int MAXN=510;
int uN,vN;//u,v数目
int g[MAXN][MAXN];
int linker[MAXN];
bool used[MAXN];
bool dfs(int u)//从左边开始找增广路径
{
int v;
for(v=0;v<vN;v++)//这个顶点编号从0开始,若要从1开始需要修改
if(g[u][v]&&!used[v])
{
used[v]=true;
if(linker[v]==-1||dfs(linker[v]))
{//找增广路,反向
linker[v]=u;
return true;
}
}
return false;//这个不要忘了。
}
int hungary()
{
int res=0;
int u;
memset(linker,-1,sizeof(linker));
for(u=0;u<uN;u++)
{
memset(used,0,sizeof(used));
if(dfs(u)) res++;
}
return res;
}<pre name="code" class="objc">模板二:邻接表实现
/以hdu1054 为例:
#include<stdio.h>
#include<iostream>
#include<algorithm>
#include<string.h>
#include<vector>
using namespace std;
//************************************************
const int MAXN=1505;//这个值要超过两边个数的较大者,因为有linker
int linker[MAXN];
bool used[MAXN];
vector<int>map[MAXN];
int uN;
bool dfs(int u)
{
for(int i=0;i<map[u].size();i++)
{
if(!used[map[u][i]])
{
used[map[u][i]]=true;
if(linker[map[u][i]]==-1||dfs(linker[map[u][i]]))
{
linker[map[u][i]]=u;
return true;
}
}
}
return false;
}
inthungary()
{
int u;
int res=0;
memset(linker,-1,sizeof(linker));
for(u=0;u<uN;u++)
{
memset(used,false,sizeof(used));
if(dfs(u)) res++;
}
return res;
}
//*****************************************************
int main()
{
int u,k,v;
int n;
while(scanf("%d",&n)!=EOF)
{
for(int i=0;i<MAXN;i++)
map[i].clear();
for(int i=0;i<n;i++)
{
scanf("%d:(%d)",&u,&k);
while(k--)
{
scanf("%d",&v);
map[u].push_back(v);
map[v].push_back(u);
}
}
uN=n;
printf("%d\n",hungary()/2);
}
return 0;
}
模板转载自http://www.cnblogs.com/kuangbin/archive/2012/08/26/2657446.html
最大匹配数:最大匹配的匹配边的数目
最小点覆盖数:选取最少的点,使任意一条边至少有一个端点被选择
最大独立数:选取最多的点,使任意所选两点均不相连
最小路径覆盖数:对于一个 DAG(有向无环图),选取最少条路径,使得每个顶点属于且仅属于一条路径。路径长可以为 0(即单个点)。定理1:最大匹配数 = 最小点覆盖数(这是 Konig 定理)
定理2:最大匹配数 = 最大独立数
定理3:最小路径覆盖数 = 顶点数 - 最大匹配数
二分图最小顶点覆盖的证明
首先,回顾一下二分图最小点覆盖的定义:
二分图中,选取最少的点数,使这些点和所有的边都有关联(把所有的边的覆盖),叫做最小点覆盖。
最少点数=最大匹配数
结合昨天看的介绍,,今天按照我的理解给出自己的证明(原创,仅作参考,欢迎讨论)
从最大匹配数到底能不能覆盖所有的边入手。
因为已知了最大匹配,所有再也不能找到增广路了,有最大匹配定义知。
现在所有的边就剩下两种情况了,一种是匹配,一种是不匹配。
假设所有的匹配边有n条,那么左右边就都有n个匹配边的顶点了,标记所有左边匹配边的顶点,则有n个。
问题就是证明n=最小点覆盖,即证明最大匹配数n到底能不能覆盖所有的边入手。
考察右边的匹配边的顶点,明显,左边都可以找到其匹配点且为n,说明所有匹配边已经被这左边的n个点关联了。
















 3578
3578

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











