



总体标准差的估算值可以通过将平均极差除以合适的常数因子d2来计算。这个估算方法是用于估算总体标准差的一种常见方法,尤其在质量控制和过程监控中经常使用。
总体标准差的估算值 = (平均极差) / d2
其中:
- "总体标准差的估算值" 表示用极差方法估算的总体标准差。
- "平均极差" 是各个子组的极差的平均值。
- "d2" 是根据采样方法和子组样本容量选择的常数因子,用于校正极差以估算总体标准差。
# 估算整体数据集的标准差
R = np.mean(range_per_group) # 极差均值
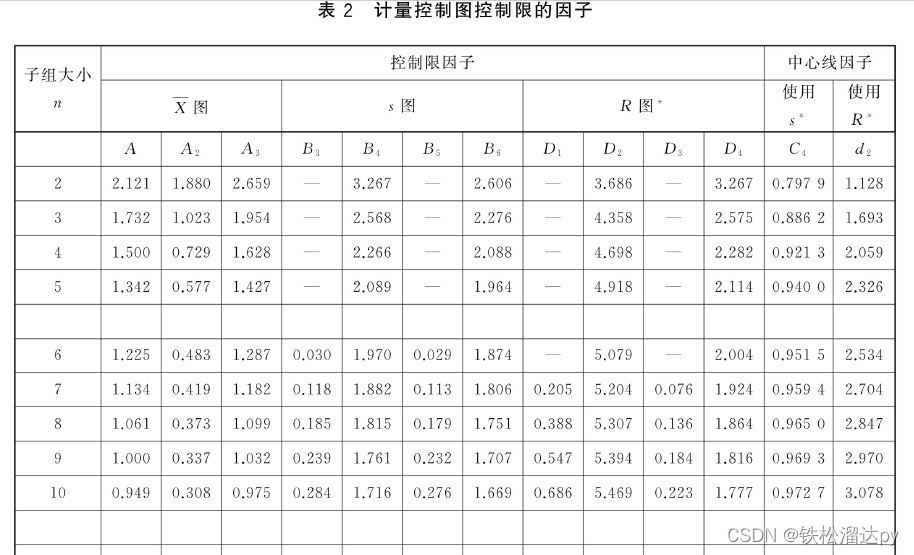
d2 = 2.847 # 根据具体的采样方法选择合适的d2值
std = R / d2

import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import norm
plt.rcParams['font.sans-serif'] = ['SimHei'] # 防止中文标签乱码
plt.rcParams['axes.unicode_minus'] = False
# 准备数据,这里使用随机数据作为示例
# data = [np.random.randn(8) for _ in range(10)]
data = np.random.randn(8, 8)
# 计算每个分组的极差
range_per_group = [np.ptp(group) for group in data]
# 扁平化数据
flat_data = np.concatenate(data)
# 计算各组均值的均值
x_bar_avg = np.mean([np.mean(group) for group in data])
# 估算整体数据集的标准差
R = np.mean(range_per_group)
d2 = 2.847 # 根据具体的采样方法选择合适的d2值
std = R / d2
# 生成正态分布的概率密度曲线,使用各组均值的均值作为中心
x = np.linspace(min(flat_data), max(flat_data), 100)
pdf = norm.pdf(x, loc=x_bar_avg, scale=std)
# 绘制直方图
plt.hist(flat_data, bins=8, density=True, alpha=0.5, color='b', label='直方图')
# 绘制概率密度曲线
plt.plot(x, pdf, color='r', label='概率密度曲线')
# 添加标签和标题
plt.xlabel('X轴标签')
plt.ylabel('Y轴标签')
plt.title('整体数据的直方图和使用各组均值的均值生成的概率密度曲线')
# 显示图形
plt.legend()
plt.show()-
X-R 控制图(Individuals and Range Control Chart):
- 通常适用于小样本容量,尤其是子组样本容量小于 10 的情况。
- X-R 控制图是用于监控过程变异性的一种方法,范围(Range,R)用于度量子组内的变异性。
- 适用于较小的子组容量,因为大样本容量的情况下,范围(R)可能会变得相对稳定,难以检测到小幅度的过程变异。
-
X-S 控制图(Individuals and Standard Deviation Control Chart):
- 通常适用于较大的样本容量,尤其是子组样本容量较大的情况。
- X-S 控制图用于监控过程的稳定性,标准差(Standard Deviation,S)用于度量子组内的变异性。
- 适用于较大的样本容量,因为在小样本容量情况下,估算标准差可能会不够稳定。
总之,X-R 控制图通常用于小样本容量,而 X-S 控制图更适用于较大的样本容量,因为它们分别适应不同的过程变异性度量方法。选择哪种控制图取决于您的具体应用和数据情况,以确保有效地监控过程的稳定性和变异性。
----------------------------------
控制图(如X-R图和X-S图)是一种用于估算总体标准差的方法,通常应用于质量控制和过程监控。这些方法利用过程中的变异性来估算总体标准差。
具体来说:
-
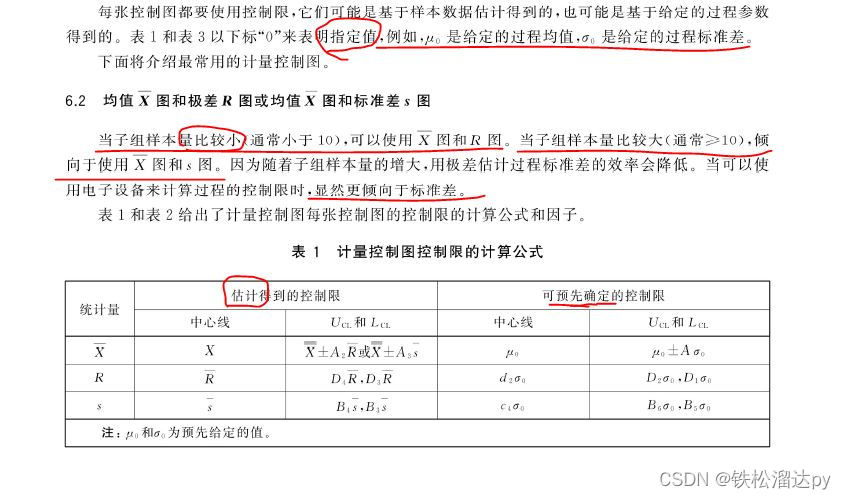
X-R 图(Individuals and Range Control Chart):在X-R图中,X图用于监测过程的平均值,而R图用于监测子组样本的极差。通过监控这两个图,您可以估算过程的总体标准差。总体标准差的估算方法如下:
总体标准差的估算值 = R图的平均极差 / d2
这里,R图的平均极差是R图中各个子组极差的平均值,d2是一个根据样本容量选择的常数因子。
-
X-S 图(Individuals and Standard Deviation Control Chart):在X-S图中,X图用于监测过程的平均值,而S图用于监测子组样本的标准差。通过监控这两个图,您可以估算过程的总体标准差。总体标准差的估算方法如下:
总体标准差的估算值 = S图的平均标准差 / c4
这里,S图的平均标准差是S图中各个子组标准差的平均值,c4是一个根据样本容量选择的常数因子。
这两种控制图方法能够提供过程的实时监测和总体标准差的估算,有助于及时发现和纠正过程中的变异性。它们在质量控制和过程改进中发挥着重要的作用。
| 1组 | 2组 | 3组 | 4组 | 5组 | 6组 | 7组 | 8组 | 9组 | 10组 | 11组 | 12组 |
| 6.4 | 6.8 | 6.3 | 6.1 | 6.4 | 6.6 | 6.3 | 6.4 | 6.3 | 6.7 | 6.6 | 6.8 |
| 7.0 | 6.4 | 7.1 | 6.8 | 6.9 | 6.0 | 6.9 | 5.6 | 6.7 | 5.9 | 7.0 | 6.2 |
| 6.4 | 6.4 | 6.5 | 5.9 | 6.8 | 6.1 | 6.6 | 6.2 | 6.6 | 5.8 | 6.5 | 6.5 |
| 6.4 | 6.3 | 6.4 | 5.8 | 6.5 | 6.2 | 6.2 | 6.0 | 6.4 | 6.3 | 6.4 | 6.2 |
| 7.1 | 6.5 | 7.0 | 6.0 | 6.9 | 5.9 | 6.8 | 5.8 | 6.3 | 6.2 | 7.1 | 5.8 |

















 410
410

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









