







系列文章:
【AI Infra】【RLHF框架】一、VeRL中基于Ray的执行流程源码解析
【AI Infra】【RLHF框架】二、VeRL中colocate实现解析
【AI Infra】【RLHF框架】三、VeRL中的Rollout实现源码解析
【AI Infra】【RLHF框架】四、VeRL中PPO、GRPO、REINFORCE++、RLOO实现源码解析
VeRL是字节开源的用于LLM RL后训练的框架,完整的设计思路见Paper 《HybridFlow: A Flexible and Efficient RLHF Framework》。相比于原始论文,这篇博客的侧重点则是从源码的角度来深入理解其基于Ray的执行流程,并不涉及具体的RL算法。
一、Overview
1. 一个例子
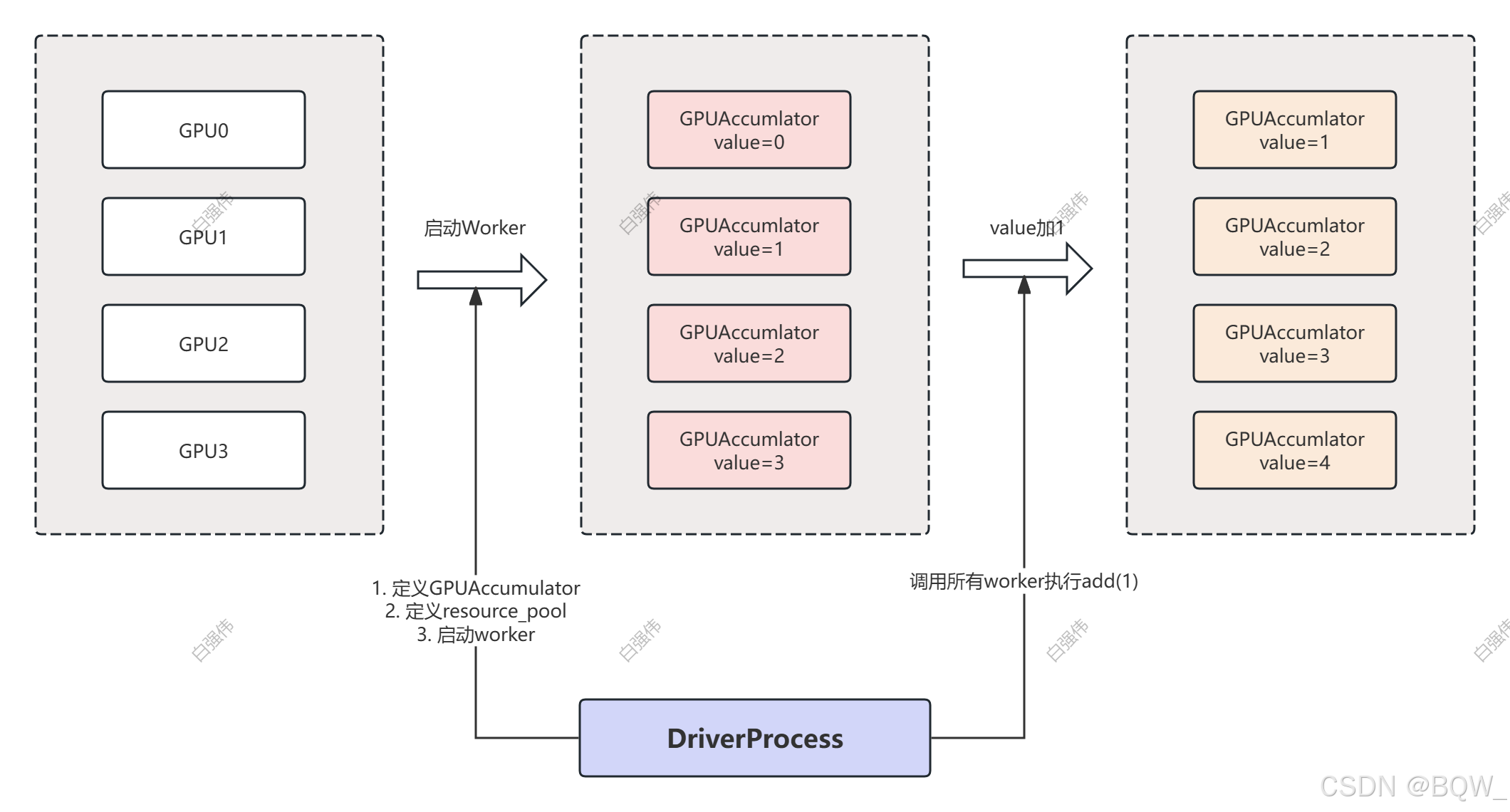
先通过一个具体的例子来感知下:假设有4个GPU,则每个GPU实例化一个GPUAccumlator,其成员变量value初始化为GPU rank,然后对所有value执行加1操作。
import ray
import torch
from verl.single_controller.base import Worker
from verl.single_controller.ray.base import RayWorkerGroup, RayResourcePool, RayClassWithInitArgs
from verl.single_controller.base.decorator import register, Dispatch
@ray.remote
class GPUAccumulator(Worker):
def __init__(self):
super().__init__()
self.value = torch.zeros(size=(1,), device="cuda") + self.rank
@register(Dispatch.ONE_TO_ALL)
def add(self, x):
self.value += x
print(f'rank {self.rank}, value: {self.value}')
return self.value.cpu()
class_with_args = RayClassWithInitArgs(GPUAccumulator)
resource_pool = RayResourcePool([4], use_gpu=True)
workergroup = RayWorkerGroup(resource_pool, class_with_args)
print(workergroup.add(x=1)) # 输出:[tensor([1.]), tensor([2.]), tensor([3.]), tensor([4.])]
2. 整体设计
为了实现上面的功能,VeRL中抽象出了Worker、WorkerGroup、ResourcePool、DriverProcess的概念。下面是官方文档中这些概念的示例图。
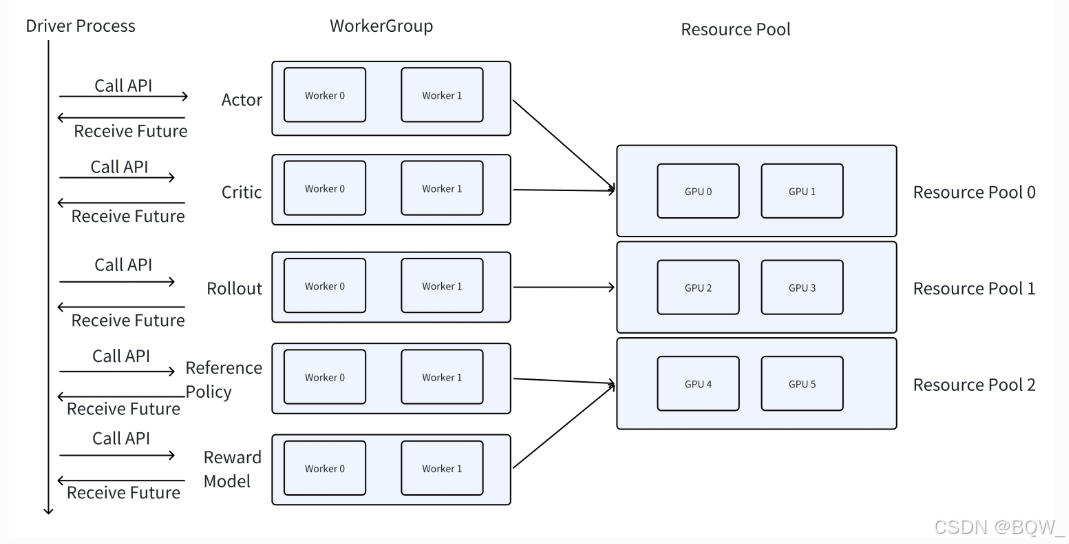
后面的章节会通过源码的方式来深入理解这些概念。
二、数据交换协议:DataProto
DataProto是veRL中各种功能之间用于数据交换的标准协议。
1. 基础结构
# 原始代码位于verl/protocol.py
@dataclass
class DataProto:
batch: TensorDict = None
non_tensor_batch: Dict = field(default_factory=dict)
meta_info: Dict = field(default_factory=dict)
...
DataProto持有三种类型的数据,分别是batch、non_tensor_batch和meta_info。通过命名也可以看出,DataProto是以batch的方式来组织数据的。
2. 使用示例
更多的使用示例见tests/utility/test_tensor_dict_utilities.py。这里给出基本的示例,便于直观理解DataProto的作用。
# 构造
obs = torch.randn(100, 10) # batch_size为100的tensor
labels = [random.choice(['abc', 'cde']) for _ in range(100)] # 随机挑选‘abc’和‘cde’来构造大小为100的list
dataset = DataProto.from_dict(tensors={'obs': obs}, non_tensors={'labels': labels}) # 实例化
# pop
poped_dataset = dataset.pop(batch_keys=['obs']) # 将batch总的"obs"弹出,poped_dataset为弹出数据,仍然为DataProto
3. DataProtoFuture
在verl/protocol.py中除了DataProto外,还定义了Future版本的DataProtoFuture。其保存了ray.ObjectRef对象列表futures以及两个函数collect_fn和dispatch_fn。
@dataclass
class DataProtoFuture:
collect_fn: Callable # 用于将future对象列表简化为一个DataProto
futures: List[ray.ObjectRef]
dispatch_fn: Callable = None # 用于将DataProto划分为大小为 world_size的多个DataProto列表
def get(self):
output = ray.get(self.futures)
for o in output:
assert isinstance(o, DataProto)
output = self.collect_fn(output)
if self.dispatch_fn is not None:
output = self.dispatch_fn(output)
return output
三、基础执行单元:Worker
Worker是负责执行具体任务的基础执行单元,其保存了分布式执行时必要的信息。具体的执行任务,需要用户基础Worker类来实现。
1. 代码解析
在verl中,通过WorkerGoup来统一实例化并调度Worker,并且在概念上存在master worker。现在先来看看单个Worker。
简单来说,Worker类负责存储world_size、rank等分布式计算的相关信息并配置环境变量,Master Worker相对于其他Worker需要额外保存MASTER_ADDR和MASTER_PORT的信息。下面是简化后的Worker代码:
# 简化后代码,原始代码位于verl/single_controller/base/worker.py
class Worker(WorkerHelper):
def __new__(cls, *args, **kwargs):
instance = super().__new__(cls)
rank = os.environ.get("RANK", None)
worker_group_prefix = os.environ.get("WG_PREFIX", None)
if None not in [rank, worker_group_prefix] and 'ActorClass(' not in cls.__name__:
instance._configure_before_init(f"{worker_group_prefix}_register_center", int(rank))
return instance
def _configure_before_init(self, register_center_name: str, rank: int):
# rank=0时,配置MASTER_ADDR和MASTER_PORT环境变量,并将该信息存储在self.register_center中
if rank == 0:
master_addr, master_port = self.get_availale_master_addr_port()
rank_zero_info = {
"MASTER_ADDR": master_addr,
"MASTER_PORT": master_port,
}
if os.getenv("WG_BACKEND", None) == "ray":
from verl.single_controller.base.register_center.ray import create_worker_group_register_center
self.register_center = create_worker_group_register_center(name=register_center_name,info=rank_zero_info)
os.environ.update(rank_zero_info)
def __init__(self, cuda_visible_devices=None) -> None:
world_size = int(os.environ['WORLD_SIZE'])
rank = int(os.environ['RANK'])
self._rank = rank
self._world_size = world_size
master_addr = os.environ["MASTER_ADDR"]
master_port = os.environ["MASTER_PORT"]
local_world_size = int(os.getenv("LOCAL_WORLD_SIZE", "1"))
local_rank = int(os.getenv("LOCAL_RANK", "0"))
store = {
'_world_size': world_size,
'_rank': rank,
'_local_world_size': local_world_size,
'_local_rank': local_rank,
'_master_addr': master_addr,
'_master_port': master_port
}
# WorkerMeta仅是包store信息存储在实例对象中
meta = WorkerMeta(store=store)
# 将meta(store)信息更新到当前实例的__dict__中并配置环境变量
self._configure_with_meta(meta=meta)
类Worker继承自WorkerHelper,其基类WorkerHelper提供唯一的功能就是获得当前节点的IP地址和可用端口号。Worker中核心方法包括__new__和__init__,其中__new__的作用针对rank0配置MASTER_ADDR和MASTER_PORT,__init__则是将world_size、rank保存在当前实例中。
2. 一个自定义Worker的例子
Worker并不执行具体的计算任务,因此需要用户继承该类来实现自定义的计算任务。这里展示一个模拟"数据并行(DP)"前向的例子,来更好的理解Ray和Worker如何实现分布式计算。
import os
import ray
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
from verl.single_controller.base import Worker
class MyNet(nn.Module):
def __init__(self):
super(MyNet, self).__init__()
self.linear = nn.Linear(100, 1)
def compute_loss(self, x, y):
pred = self.linear(x)
loss = F.mse_loss(pred, y)
return loss
@ray.remote(num_gpus=1)
class MyNetWorker(Worker):
def __init__(self):
super().__init__()
self.network = MyNet()
self.device = torch.device(f"cuda")
self.network.to(self.device)
def compute_network_loss(self, inputs, targets):
inputs = inputs.to(self.device)
targets = targets.to(self.device)
return self.network.compute_loss(inputs, targets).item()
if __name__ == "__main__":
ray.init()
options0 = {'runtime_env': {'env_vars': {'LOCAL_WORLD_SIZE': '2', 'LOCAL_RANK': '0', 'WORLD_SIZE': '2', 'RANK': '0', 'WG_PREFIX': 'test', 'WG_BACKEND': 'ray'}}}
options1 = {'runtime_env': {'env_vars': {'LOCAL_WORLD_SIZE': '2', 'LOCAL_RANK': '1', 'WORLD_SIZE': '2', 'RANK': '1', 'WG_PREFIX': 'test', 'WG_BACKEND': 'ray'}}}
# 初始化Master Worker
worker0 = MyNetWorker.options(**options0).remote()
time.sleep(10) # 等待register_center_actor创建
register_center_actor = ray.get_actor("test_register_center")
rank_zero_info = ray.get(register_center_actor.get_rank_zero_info.remote())
print(f"rank_zero_info: {rank_zero_info}")
# 更新MASTER_ADDR和MASTER_PORT至options1,并创建worker1
options1['runtime_env']['env_vars'].update(rank_zero_info)
worker1 = MyNetWorker.options(**options1).remote()
# 生成测试数据
batch_size = 16
inputs = torch.randn(batch_size, 100)
targets = torch.randn(batch_size, 1)
# 分割数据为两份
split_size = batch_size // 2
inputs_split = torch.chunk(inputs, 2)
targets_split = torch.chunk(targets, 2)
# 并行计算
future0 = worker0.compute_network_loss.remote(inputs_split[0], targets_split[0])
future1 = worker1.compute_network_loss.remote(inputs_split[1], targets_split[1])
# 获取结果并平均
loss0 = ray.get(future0)
loss1 = ray.get(future1)
avg_loss = (loss0 + loss1) / 2
print(f"Worker 0 Loss: {loss0:.4f}")
print(f"Worker 1 Loss: {loss1:.4f}")
print(f"Averaged Loss: {avg_loss:.4f}")
# 关闭Ray
ray.shutdown()
3. 装饰器
在自定义Worker时,还可以使用装饰器register来扩展函数的功能。至于为什么要使用这个装饰器,在RayWorkerGroup小节会详细介绍。
3.1 一个示例
import os
import torch
from verl.single_controller.base import Worker
from verl.single_controller.base.decorator import register, Dispatch, Execute
os.environ['LOCAL_WORLD_SIZE'] = '2'
os.environ['LOCAL_RANK'] = '0'
os.environ['WORLD_SIZE'] = '2'
os.environ['RANK'] = '0'
os.environ['WG_PREFIX'] = 'test'
os.environ['WG_BACKEND'] = 'ray'
class GPUAccumulatorDecorator(Worker):
def __init__(self):
super().__init__()
self.value = torch.zeros(size=(1,), device="cuda") + self.rank
@register(dispatch_mode=Dispatch.ONE_TO_ALL, execute_mode=Execute.RANK_ZERO)
def add(self, x):
self.value += x
return self.value.cpu()
worker = GPUAccumulatorDecorator()
print(worker.add.attrs_3141562937)
这段代码的输出是{'dispatch_mode': <Dispatch.ONE_TO_ALL: 1>, 'execute_mode': <Execute.RANK_ZERO: 1>, 'blocking': True}。所以,装饰器register的核心功能就是给函数添加了一个新的属性attrs_attrs_3141562937,该属性保存了dispatch_mode等信息。
3.2 源码解析
def register(dispatch_mode=Dispatch.ALL_TO_ALL, execute_mode=Execute.ALL, blocking=True, materialize_futures=True):
_check_dispatch_mode(dispatch_mode=dispatch_mode)
_check_execute_mode(execute_mode=execute_mode)
# func是被装饰的函数
def decorator(func):
@wraps(func)
def inner(*args, **kwargs):
if materialize_futures:
# _materialize_futures将future转换为实际的数据
args, kwargs = _materialize_futures(*args, **kwargs)
return func(*args, **kwargs)
# 为被装饰函数新增一个MAGIC_ATTR属性
attrs = {'dispatch_mode': dispatch_mode, 'execute_mode': execute_mode, 'blocking': blocking}
setattr(inner, MAGIC_ATTR, attrs)
return inner
return decorator
所以,register仅包含两个功能:(1) 若参数是future,则获得实际的值;(2) 为被装饰函数添加MAGIC_ATTR属性。
四、RayClassWithInitArgs
RayClassWithInitArgs保存了通过@ray.remote定义的Actor类,以及一些用于异步调用该Actor时所需要的参数。总的来说,RayClassWithInitArgs更像是工厂类,在调用__call__时再启动Actor。
# 简化后代码,原始代码位于verl/single_controller/ray/base.py
class RayClassWithInitArgs(ClassWithInitArgs):
def __init__(self, cls, *args, **kwargs) -> None:
super().__init__(cls, *args, **kwargs) # 保存Actor
self._options = {}
self._additional_resource = {}
def __call__(self,
placement_group,
placement_group_bundle_idx,
use_gpu: bool = True,
num_gpus=1,
sharing_with=None) -> Any:
# 调度策略
options = {
"scheduling_strategy": PlacementGroupSchedulingStrategy(placement_group=placement_group,
placement_group_bundle_index=placement_group_bundle_idx)}
# 更新actor启动的一些参数
options.update(self._options)
if len(self._additional_resource) > 1:
for k, v in self._additional_resource.items():
options[k] = v
# Ray中异步启动Actor
return self.cls.options(**options).remote(*self.args, **self.kwargs)
五、资源池:RayResourcePool
1. Ray中的Placement Group
Placement Group是Ray中的资源组概念,其作用是允许用户跨多个节点来原子性地保留一组资源。在创建Placement Group时需要指定bundles,单个bundle是一个“资源”的集合,也是Placement Group的资源预留单位。
为了便于理解,还是来看例子吧。假设你有一个包含8GPU、16CPU的节点,现在想用一半的资源构成资源组进程任务的调度。
import ray
from ray.util.placement_group
# 创建包含8GPU、16CPU的Ray集群
ray.init(num_cpus=16, num_gpus=8)
# 创建包含4个bundle的placement group,共计使用一半的资源
pg = placement_group(bundles=[{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1}])
# 等待资源组创建完成
ray.get(pg.ready(), timeout=10)
2. RayResourcePool
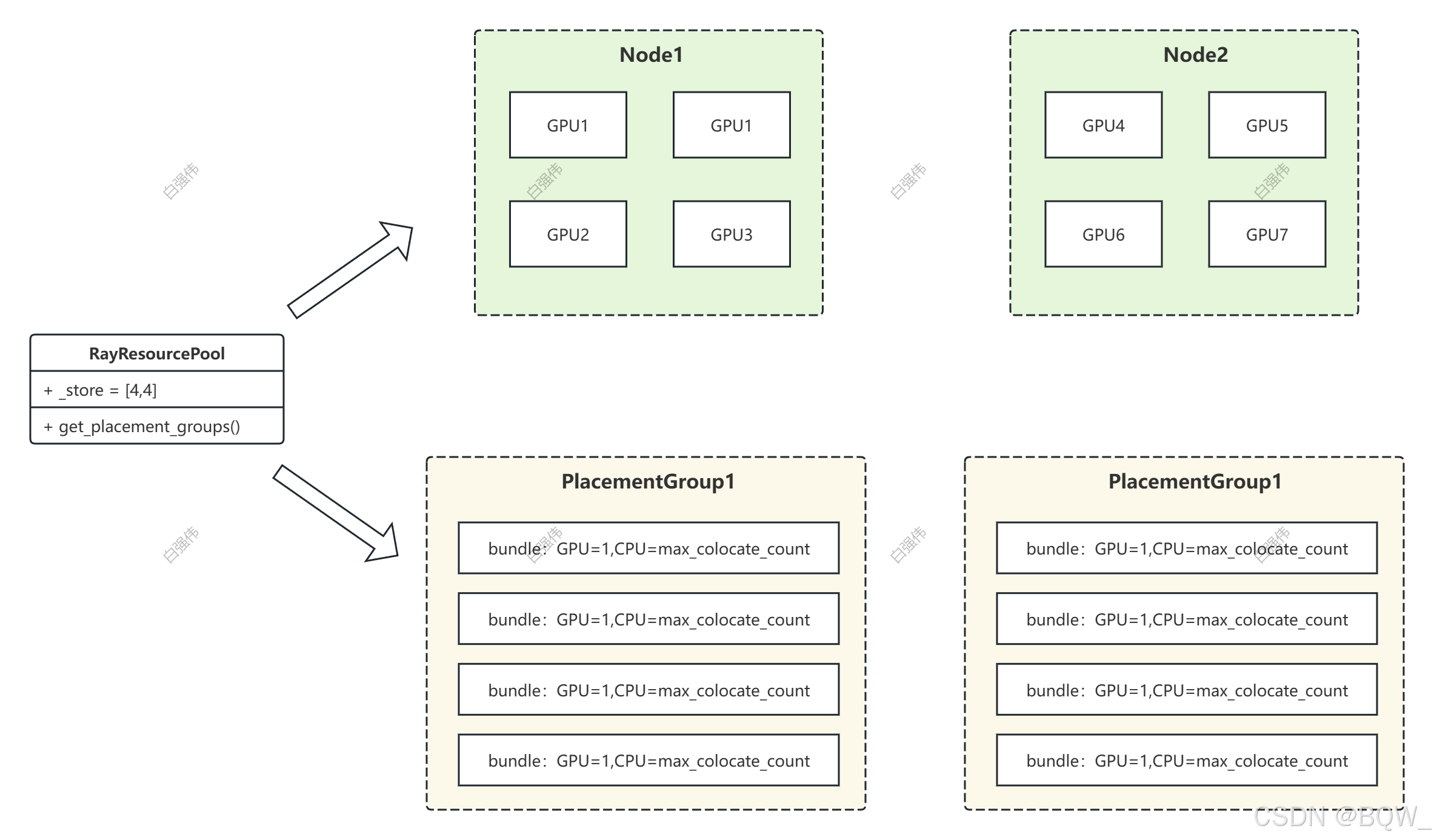
RayResourcePool继承自ResourcePool,ResourcePool负责存储资源相关的信息,而RayResourcePool则是通过Ray的Placement Group实现资源池的分配。例如:
resource_pool = RayResourcePool(process_on_nodes=[4,4], max_colocate_count=2, use_gpu=True) # 创建资源池
pgs = resource_pool.get_placement_groups() # 创建placement group的列表
该段代码会创建两个Placement Group,每个Placement Group包含4个GPU和8个CPU。单个Placement Group创建为
pg = placement_group(bundles=[{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1},
{"CPU": 2, "GPU": 1}])
即process_on_nodes指定要创建几个Placement Group以及每个包含多少GPU,max_colocate_count是则bundle中单个GPU对应多少个CPU,因此colocate的actor至少要有1个CPU。
六、RayWorkerGroup
RayWorkerGroup扮演着资源分配和调度Worker的协调器角色,其核心方法包括:_init_with_resource_pool、_bind_worker_method和execute_all_async。在初始化__init__中核心两个事情:(1) 在指定的资源池上启动worker;(2) 将worker的某些方法绑定到workergroup上,方便直接通过workergroup进行调用,简化代码。
# 简化后代码,原始代码位于verl/single_controller/ray/base.py
class RayWorkerGroup(WorkerGroup):
def __init__(self,
resource_pool: RayResourcePool = None,
ray_cls_with_init: RayClassWithInitArgs = None,
bin_pack: bool = True,
name_prefix: str = None,
detached=False,
worker_names=None,
**kwargs) -> None:
super().__init__(resource_pool=resource_pool, **kwargs)
self.ray_cls_with_init = ray_cls_with_init
...
# 基于resource_pool的信息,启动worker
self._init_with_resource_pool(resource_pool=resource_pool,
ray_cls_with_init=ray_cls_with_init,
bin_pack=bin_pack,
detached=detached)
# ray_cls_with_init.clsz中的某些方法绑定到RayWorkerGroup上
self._bind_worker_method(self.ray_cls_with_init.cls, func_generator)
1. 启动Workers:_init_with_resource_pool
# 简化后代码,原始代码位于verl/single_controller/ray/base.py
def _init_with_resource_pool(self, resource_pool, ray_cls_with_init):
# max_collocate_count意味着单个GPU上至多有几个worker
num_gpus = 1 / resource_pool.max_collocate_count
# resouce_pool.store: [4,4]
for pg_idx, local_world_size in enumerate(resource_pool.store):
pg = pgs[pg_idx] # 当前的PlacementGroup
for local_rank in range(local_world_size):
# 1. 构造worker需要的配置信息,包括环境变量等;
# 2. 通过ray_cls_with_init.update_options更新这些配置信息
# 启动worker
worker = ray_cls_with_init(placement_group=pg,
placement_group_bundle_idx=local_rank,
num_gpus=num_gpus)
self._workers.append(worker)
self._worker_names.append(name)
2. 异步执行:execute_all_async
在_init_with_resource_pool后,self._workers中保存着所有的worker。显然,当需要调用所有worker某个方法时,可以很方便的实现,这个方法就是execute_all_async。
假设已经有4个worker,需要每个worker都执行方法add,参数为10。那么可以
workergroup.execute_all_async("add", x=10)
或者
workergroup.execute_all_async("add", x=[10,10,10,10])
但是,利用execute_all_async来调用worker的方法并不是一个很自然的方式。所以,利用装饰器register和_bind_worker_method来令调用更加自然。
3. worker方法绑定至workergroup:_bind_worker_method
_bind_worker_method来自基类WorkerGroup,参数包含user_defined_cls和func_generator。其中user_defined_cls就是用户自定义的worker类。
3.1 func_genenrator
# 原始代码位于verl/single_controller/ray/base.py
def func_generator(self, method_name, dispatch_fn, collect_fn, execute_fn, blocking):
def func(*args, **kwargs):
args, kwargs = dispatch_fn(self, *args, **kwargs)
output = execute_fn(method_name, *args, **kwargs)
if blocking:
output = ray.get(output)
output = collect_fn(self, output)
return output
return func
func_generator是功能是构造一个函数。在整个项目的实际调用中,method_name其是就是自定义worker中使用了装饰器registor的函数。通过func_generator构造的新函数,先会对参数调用dispath_fn,然后执行method_name方法,最后利用collect_fn产生最终输出。
3.2 _bind_worker_method源码
# 简化代码,原始代码位于verl/single_controller/base/worker_group.py
def _bind_worker_method(self, user_defined_cls, func_generator):
for method_name in dir(user_defined_cls): # 遍历类的所有方法
if hasattr(method, MAGIC_ATTR): # 寻找使用了装饰器`register`的方法
# 获取dispath_fn、collect_fn和execut_fn
dispatch_mode = attribute['dispatch_mode']
execute_mode = attribute['execute_mode']
blocking = attribute['blocking']
fn = get_predefined_dispatch_fn(dispatch_mode=dispatch_mode)
dispatch_fn = fn['dispatch_fn']
collect_fn = fn['collect_fn']
execute_mode = get_predefined_execute_fn(execute_mode=execute_mode)
wg_execute_fn_name = execute_mode['execute_fn_name']
execute_fn = getattr(self, wg_execute_fn_name)
# 利用func_generator将dispatch_fn、collect_fn组装到method_name上
func = func_generator(self,
method_name,
dispatch_fn=dispatch_fn,
collect_fn=collect_fn,
execute_fn=execute_fn,
blocking=blocking)
# func绑定到workgroup上,func的名字仍然保持为mehtod_name
setattr(self, method_name, func)
参考资料
- https://verl.readthedocs.io/en/latest/hybrid_flow.html
- HybridFlow: A Flexible and Efficient RLHF Framework
- https://github.com/volcengine/verl


















 159
159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











