






目录
一、任务说明
数据集来源于百度飞桨AI Studio中的公开数据集。宝石分类数据集共有25种宝石类别,每种类别的图片数目在30~40张左右,共有811张训练图片和4张测试图片(测试图片少的可怜)。
数据集链接:https://aistudio.baidu.com/datasetdetail/162243
本次任务的实践环境是:Windows11 (RTX 3050显卡)+ PyCharm 2023.2.3 + PyTorch 2.0.1+cu117 + Python3.8
本次任务适合有一点儿深度学习、pytorch和python基础的同学,还涉及tensorboard的简单使用。主要目的是学会用CNN进行图像分类有哪些步骤,每一步要怎么做,不涉及调参、优化网络等知识。
二、任务准备
没有安装tensorboard的同学需要在终端运行“pip install tensorboard”安装一下,在PyCharm里新建项目文件,在项目目录里新建一个jupyter notebook文件,然后将解压好的数据集以下面的文件夹结构添加进项目目录。
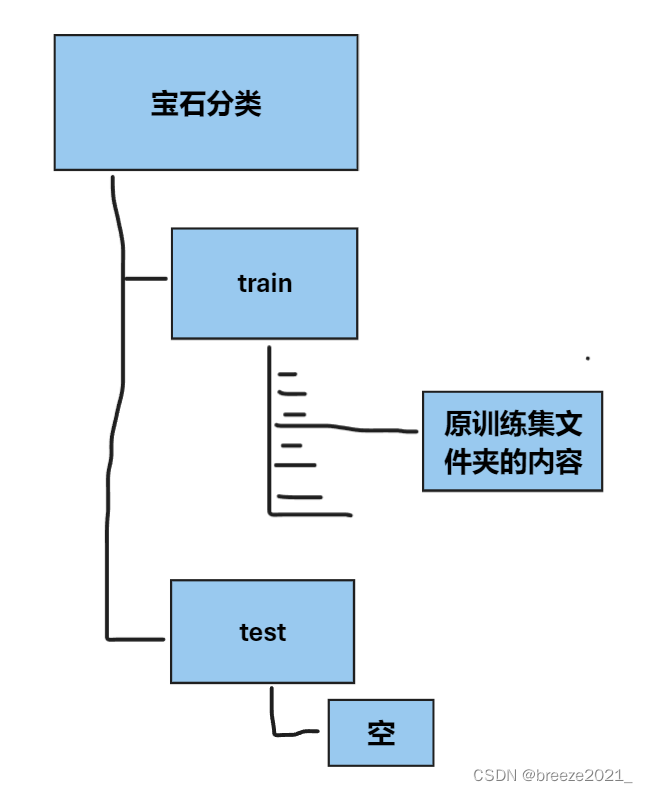
三、任务内容
该任务包含的有分割数据集、定义CNN、加载数据集、训练模型、测试模型五个步骤 。
四、任务过程
1.分割数据集
解压数据集文件后发现,原始的测试集图片数量太少(而且是同一类的), 因此我将测试集的4张图片塞进训练对应的类别里去了,这样就需要重新划分训练集测试集。本次任务的划分方式是每一类每有15张图片就把该张图片作为测试图片,最终得到了46张不同类别的测试图片,代码如下:
import os
import random
def split_dataset(path):
#先判断存储图像路径和标签的文件是否存在,存在的话就删掉,以免重复录入。
if os.path.isfile('train.txt') and os.path.isfile('test.txt'):
os.remove('./train.txt')
os.remove('./test.txt')
else:
pass
#存储训练图片的路径和标签
train_split = []
#存储测试图片的路径和标签
test_split = []
#图像标签
target = 0
#存储标签对应类别名称的字典
dataset_details = {}
for class_num in os.listdir(path):
count = 0
dataset_details[target] = class_num
class_path = os.path.join(path, class_num)
for img_name in os.listdir(class_path):
count += 1
img_path = os.path.join(class_path, img_name)
#每遍历十五张图片就把这张图作为测试图片
if count % 15 == 0:
test_split.append(img_path + '\t%d' % target + '\n')
else:
train_split.append(img_path + '\t%d' % target + '\n')
target += 1
#打乱数据集
random.shuffle(train_split)
random.shuffle(test_split)
#将存储列表的内容录入文件里,方便后边加载数据
with open('./train.txt', mode='a') as f1:
for train_data in train_split:
f1.write(train_data)
f1.close()
with open('./test.txt', mode='a') as f2:
for test_data in test_split:
f2.write(test_data)
f2.close()
print(f'训练集图片总数:{len(train_split)}')
print(f'测试集图片总数:{len(test_split)}')
return dataset_details
dataset_details = split_dataset(r"D:\machine learning datasets\宝石分类\train") #在windows里直接复制路径的话需要在路径前加r
print(f'标签与类别对照:{dataset_details}')调用split_dataset()函数时需要传入自己电脑上的数据集路径,需要注意的是在Windows下直接复制文件路径需要在路径前加r(若是在pycharm里面复制则不需要),运行结果如下:
训练集图片总数:769
测试集图片总数:46
标签与类别对照:{0: 'Alexandrite', 1: 'Almandine', 2: 'Benitoite', 3: 'Beryl Golden', 4: 'Carnelian', 5: 'Cats Eye', 6: 'Danburite', 7: 'Diamond', 8: 'Emerald', 9: 'Fluorite', 10: 'Garnet Red', 11: 'Hessonite', 12: 'Iolite', 13: 'Jade', 14: 'Kunzite', 15: 'Labradorite', 16: 'Malachite', 17: 'Onyx Black', 18: 'Pearl', 19: 'Quartz Beer', 20: 'Rhodochrosite', 21: 'Sapphire Blue', 22: 'Tanzanite', 23: 'Variscite', 24: 'Zircon'}
2.定义CNN
这个网络是自己随便写的,简单的网络架构写法就像我写的一样,复杂一点的比如VGGNet,GoogleNet、ResNet还需要同学们自己探索 。该网络共有六层,三个卷积层和三个全连接层,激活函数是ReLU,图片输入尺寸为(B,3,224,224),B为batch_size大小。
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(16, 32, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 32, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(32, 64, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 64, 5, 1, 2),
nn.ReLU(),
nn.Conv2d(64, 64, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv = nn.Sequential(
self.conv1,
self.conv2,
self.conv3
)
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(64*28*28, 4096),
nn.ReLU(),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Linear(4096, 25)
)
def forward(self, x):
x = self.conv(x)
y = self.fc(x)
return y3.加载数据集
加载数据集需要自建一个dataset类,该类继承自torch.utils.data.Dataset 。我写了一个名叫mean_std()的函数,这个函数可以计算整个训练集的均值和方差,便于进行训练集的标准化。因为我的数据集路径有中文,所有在读取文件时需要将编码类型写成'gbk',如果是纯英文路径写'utf-8'就行。
import torch.utils.data as data
import torchvision.transforms as transforms
from PIL import Image
import numpy as np
import os
#计算数据集的均值和标准差
def mean_std():
c_mean = np.zeros(3)
c_std = np.zeros(3)
count = 0
with open('./train.txt', mode='r', encoding='gbk') as f1: #此处编码类型为'gbk'是因为我的路径里有中文,正常应使用'utf-8'
for a in f1.readlines():
img_path = a.strip().split('\t')[0]
img = Image.open(img_path).convert('RGB')#最好加上.convert('RGB')保证输入的图片都是三通道
img = np.asarray(img) / 255
count += 1
for d in range(3):#计算每一个通道的均值和标准差
c_mean[d] = img[:, :, d].mean()
c_std[d] = img[:, :, d].std()
f1.close()
mean = c_mean / count
std = c_std / count
return mean, std
#定义图像转换关系
def transform(mean, std):
transform_tran = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
return transform_tran
class My_Dataset(data.Dataset):
def __init__(self, mode, mean, std):
super(My_Dataset, self).__init__()
self.images = []
self.targets = []
self.transform = transform(mean, std)
self.mode = mode
with open(f'./{self.mode}.txt', mode='r', encoding='gbk') as f1:#此处编码类型为'gbk'是因为我的路径里有中文,正常应使用'utf-8'
for a in f1.readlines():
img_path, target = a.strip().split('\t')[0], a.strip().split('\t')[1]
self.images.append(img_path)
self.targets.append(int(target))
def __getitem__(self, item):
img = Image.open(self.images[item]).convert('RGB')#最好加上.convert('RGB')保证输入的图片都是三通道
target = self.targets[item]
return self.transform(img), np.asarray(target) #此处注意只能这样写,如果使用torch.longtensor()那么就和后边训练的写法不一致了
def __len__(self):
return len(self.images)
mean, std = mean_std()
train_dataset = My_Dataset('train', mean, std)4.训练模型
训练模型使用了tensorboard实现训练损失率的可视化 。
import torch
from torch.utils.tensorboard import SummaryWriter #画出训练损失图像
#加载训练数据,实例化SummaryWriter,将日志文件存放到log文件夹,该文件夹会自动创建在项目目录
data_load = torch.utils.data.DataLoader(train_dataset, batch_size=8, shuffle=True)
writer = SummaryWriter('log')
#实例化网络、设置损失函数和优化器
model = Net()
model.to('cuda') #如果没有gpu则写cpu
model.train()
loss_function = torch.nn.CrossEntropyLoss()
optim = torch.optim.SGD(model.parameters(), lr=1e-3)
for epoch in range(20):
step = 0
losses = []
for img, target in data_load:
img, target = img.to('cuda'), target.to('cuda')
pred = model(img)
loss = loss_function(pred, target.long()) #这里要注意target要使用长整型。
optim.zero_grad()
loss.backward()
optim.step()
step += 1
print(f'epoch:{epoch + 1} [{step * 8}/{len(data_load) * 8}] loss:{loss / 8}')
losses.append(loss)
mean_loss = sum(losses) / step * 8
writer.add_scalar('training loss', mean_loss, epoch) #每个epoch计算平均损失,然后画图,在终端里输入tensorboard --logdir=log后点击网址即可查看图像
#保存模型
torch.save(model.state_dict(), 'Net.pth')运行结果如下:
epoch:1 [8/776] loss:0.46452921628952026
epoch:1 [16/776] loss:0.46871498227119446
epoch:1 [24/776] loss:0.4274523854255676
epoch:1 [32/776] loss:0.415669322013855
epoch:1 [40/776] loss:0.3547031879425049
·····
epoch:20 [760/776] loss:5.814544783788733e-05
epoch:20 [768/776] loss:0.00017624814063310623
epoch:20 [776/776] loss:3.8036876503610983e-05
运行完成后需要在pycharm里打开终端,输入tensorboard --logdir=log,回车后会返回一个网址,点击即可跳转浏览器查看图像,如下图所示:
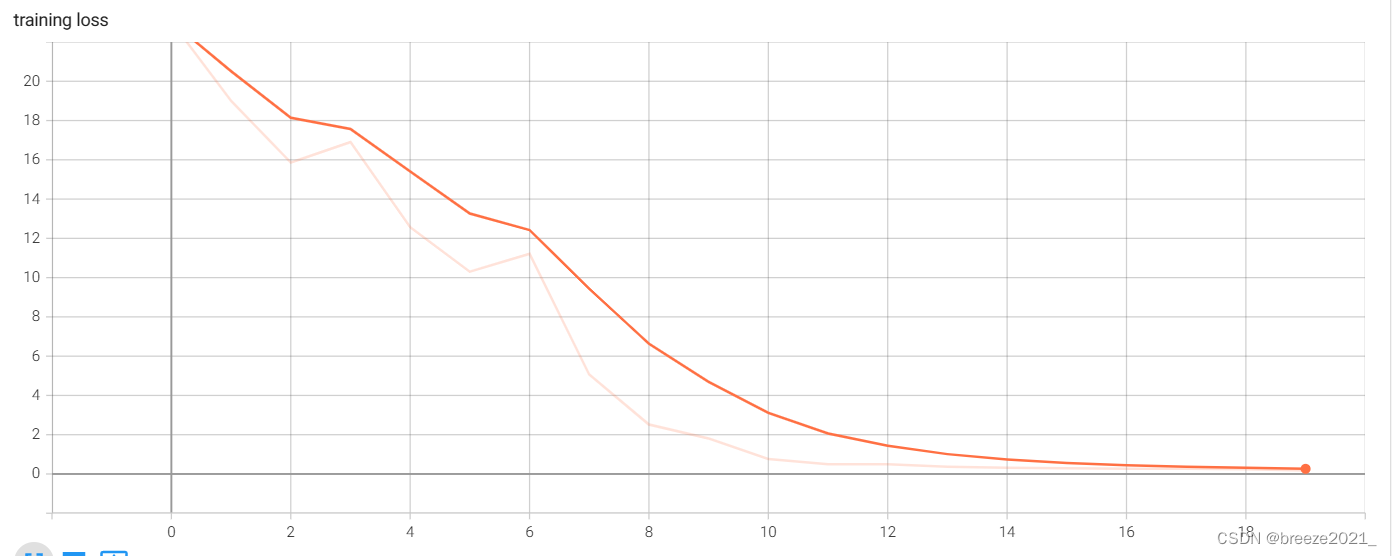
训练的损失率图像如下:
5.测试模型
测试模型我用了两种方法,分别写成test_1()和test_2()两个函数。第一种从测试集里随机抽10张图片进行预测,然后把图片展示出来,标题设为预测结果和正确结果,同时计算准确率;第二种是对测试集全部图片预测,输出一个准确率。
from torch.nn import functional as F
import matplotlib.pyplot as plt
from PIL import Image
import random
import torch
model = Net()
model.load_state_dict(torch.load('Net.pth'))
model.to('cuda')
model.eval()
#提供了两种测试方法,第一种是从测试集随机取10张进行预测,可视化输出
def test_1():
with open('test.txt', mode='r', encoding='gbk') as f1:
image_list = random.sample(f1.readlines(), 10)
f1.close()
r = 0
plt.figure(figsize=(20, 20))
transform_ = transform(mean ,std)
for _, i in enumerate(image_list):
img_path, target_ = i.strip().split('\t')[0], i.strip().split('\t')[1]
img = Image.open(img_path).convert('RGB')
img_ = transform_(img).to('cuda')
out = model(img_.unsqueeze(0))
pred = torch.argmax(F.softmax(out, dim=1)).to('cpu')
if pred == int(target_):
r += 1
else:
pass
plt.subplot(2, 5, _ + 1)
plt.title(f'pred:{dataset_details[int(pred)]}, acc:{dataset_details[int(target_)]}', fontsize=15)
plt.imshow(img)
plt.xticks([])
plt.yticks([])
print(f'抽测样本的准确率为:{(r / 10) * 100}%')
plt.tight_layout()
plt.show()
def test_2():
with open('test.txt', mode='r', encoding='gbk') as f1:
image_list = f1.readlines()
f1.close()
r = 0
transform_ = transform(mean ,std)
for _, i in enumerate(image_list):
img_path, target_ = i.strip().split('\t')[0], i.strip().split('\t')[1]
img = Image.open(img_path).convert('RGB')
img_ = transform_(img).to('cuda')
out = model(img_.unsqueeze(0))
pred = torch.argmax(F.softmax(out, dim=1)).to('cpu')
if pred == int(target_):
r += 1
else:
pass
print(f'测试集准确率为:{(r / len(image_list)) * 100}%')
test_1()
test_2()运行结果如下:
抽测样本的准确率为:50.0%

测试集准确率为:69.56521739130434%
运行提示:将上述每一步骤的代码分别放入五个代码框内,替换数据集路径,从上到下运行即可。另外tensorboard是需要额外安装的(终端运行pip install tensorboard)即可,如果报错欢迎评论区留言,我们一起进步!















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









