







Chen Xing∗
College of Computer Science,
Nankai University, Tianjin, China
Element AI, Montreal, Canada
Negar Rostamzadeh
Element AI, Montreal, Canada
Boris N. Oreshkin
Element AI, Montreal, Canada
Pedro O. Pinheiro
Element AI, Montreal, Canada
Abstract
基于度量的元学习技术已成功应用于少样本分类问题。 在本文中,我们提出利用跨模态信息来增强基于度量的少样本学习方法。 根据定义,视觉和语义特征空间具有不同的结构。 对于某些概念,视觉特征可能比文本特征更丰富、更具辨别力。 而对于其他情况来说,情况可能正好相反。此外,当图像分类中视觉信息的支持有限时,语义表示(从无监督文本语料库中学习)可以提供强大的先验知识和上下文来帮助学习。 基于这两种直觉,我们提出了一种机制,可以根据要学习的新图像类别自适应地组合来自两种模态的信息。通过一系列实验,我们表明,通过这两种模态的自适应组合,我们的模型在所有基准测试和测试场景中大大优于当前的单模态小样本学习方法和模态对齐方法。 实验还表明,我们的模型可以有效地调整其对两种模态的关注。 shot 次数非常少的时候性能提升特别大
1 Introduction
小样本图像分类的最新进展主要是在单模态学习的背景下取得的。 与此相反,当原始模态中的数据有限时,使用来自另一种模态的数据会有所帮助。 例如,强有力的证据支持语言有助于幼儿识别新视觉对象的假设 [15, 45] 。这表明来自文本的语义特征可以成为少镜头图像分类上下文中的强大信息来源。当来自视觉模态的数据有限时,利用辅助模态(例如,属性、未标记的文本语料库)来帮助图像分类,主要是由零样本学习 [24, 36] (ZSL) 驱动的。 ZSL 旨在识别在训练期间未见过实例的类别。 与小样本学习相比,原始模态中没有少量的标记样本来帮助识别新的类别。因此,大多数方法包括对齐两种模态在训练期间。 通过这种模态对齐,模态被映射在一起并强制具有相同的语义结构。 这样,来自辅助模态的知识在测试时被转移到新类别的视觉方面 [9]。 【不懂?】
然而,根据定义,视觉和语义特征空间具有异构结构。 对于某些概念,视觉特征可能比文本特征更丰富、更具辨别力。 而对于其他人来说,情况可能正好相反。 图 1 说明了这一评论。 此外,当来自视觉方面的支持图像的数量非常小时,这种模态提供的信息往往是嘈杂的和局部的。 相反,语义表示(从大型无监督文本语料库中学习)可以作为更一般的先验知识和上下文来帮助学习。 因此,取代将两者对齐模态(将知识转移到视觉模态),对于在测试期间从两种模态提供信息的小样本学习,最好将它们视为两个独立的知识源,并根据不同的场景自适应地利用这两种模态。为此,我们提出了自适应模态混合机制( Adaptive Modality Mixture Mechanism, AM3),这是一种自适应、有选择性地结合视觉和语义两种模态信息的方法,用于小样本学习。
 Figure 1: 概念具有不同的视觉和语义特征空间。 (左)某些类别可能具有相似的视觉特征和不同的语义特征。 (右)其他可以拥有相同的语义标签但非常不同的视觉特征。 我们的方法自适应地利用这两种模式来提高小样本情况下的分类性能。
Figure 1: 概念具有不同的视觉和语义特征空间。 (左)某些类别可能具有相似的视觉特征和不同的语义特征。 (右)其他可以拥有相同的语义标签但非常不同的视觉特征。 我们的方法自适应地利用这两种模式来提高小样本情况下的分类性能。
AM3 建立在基于度量的元学习方法之上。 这些方法通过比较学习到的度量空间(来自视觉数据)中的距离来执行分类。 最重要的是,我们的方法还利用文本信息来提高分类精度。 AM3 在关于图像类别的两个不同表示空间的自适应凸组合中执行分类。 通过这种机制,AM3 可以利用两个空间的优势并相应地调整其重点。 对于图 1(左)这样的情况,AM3 更侧重于语义模态以获取一般上下文信息。 而对于图 1(右)这样的案例,AM3 更侧重于视觉模式,以捕捉丰富的局部视觉细节以学习新概念。
我们的主要贡献可以总结如下:(i)我们提出了用于跨模态少样本分类的自适应模态混合机制(AM3)。 通过自适应地混合两种模态的语义结构,AM3 比模态对齐方法更适合小样本学习。 (ii) 我们表明,我们的方法在性能上比不同的基于度量的元学习方法有相当大的提升。 (iii) 在不同数据集和不同镜头数量的少镜头分类中,AM3 的性能明显优于当前(单模态和跨模态)最先进的技术。 (iv) 我们进行了定量调查,以验证我们的模型可以根据不同的场景有效地调整其对两种模态的关注。
3 Method
3.2 Adaptive Modality Mixture Mechanism
 Figure 2: (左)自适应模态混合模型。 最终的类别原型是视觉和语义特征表示的凸组合。 混合系数取决于语义标签嵌入。(右)AM3工作原理的定性例子。假设查询样本q有类别i。(a)与查询样本q最接近的视觉原型是pj。(b)语义原型。( c ) 混合机制在语义嵌入的情况下修改了原型的位置。(d)更新后,与查询样本最接近的原型现在是类别 i 中的一个,修正了分类。
Figure 2: (左)自适应模态混合模型。 最终的类别原型是视觉和语义特征表示的凸组合。 混合系数取决于语义标签嵌入。(右)AM3工作原理的定性例子。假设查询样本q有类别i。(a)与查询样本q最接近的视觉原型是pj。(b)语义原型。( c ) 混合机制在语义嵌入的情况下修改了原型的位置。(d)更新后,与查询样本最接近的原型现在是类别 i 中的一个,修正了分类。
语义概念中包含的信息可能与视觉内容有很大不同。 例如,“西伯利亚哈士奇”和“狼”,或“komondor”和“拖把”,可能很难通过视觉特征进行区分,但可能更容易通过语言语义特征进行区分。
在零样本学习中,在测试时没有给出视觉信息(即支持集是空的),算法需要完全依赖辅助(例如,文本)模态。 在另一个极端,当标记图像样本的数量很大时,神经网络模型往往会忽略辅助模态,因为它能够很好地泛化因为它存在大量的样本 [20]。
小样本学习场景介于这两个极端之间。 因此,我们假设视觉和语义信息都可以用于小样本学习。 此外,假定视觉和语义空间具有不同的结构,因此提出的模型在给定不同场景的情况下自适应地利用这两种模式是可取的。 例如,当它遇到像“乒乓球”这样具有许多视觉相似对应物的物体时,或者当从视觉方面看 shot 数量很少时,它更多地依靠文本模态来区分它们。
在 AM3 中,我们增强了基于度量的 FSL 方法,以合并由词嵌入模型 W(在无监督大型文本语料库上预训练)学习的语言结构,其中包含 Dtrain ∪ Dtest 中所有类别的标签嵌入。 在我们的模型中,我们通过考虑标签嵌入来修改每个类别的原型表示。
更具体地说,我们将新的原型表示建模为两种模式的凸组合。即,对于每一类c,新的原型计算为:
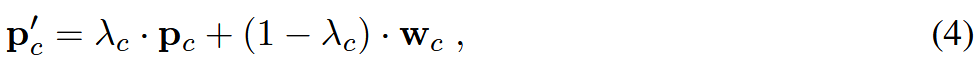 4.1 Experimental Setup
4.1 Experimental Setup
我们对该数据集进行评估,以提供与模态对齐方法的更直接比较。 这是因为大多数模态对齐方法都没有在少样本数据集上发布结果
在我们的实验中,我们使用了 [TADAM 35] 中更强的 ProtoNets 实现,我们称之为 ProtoNets++
一个可能的原因是,当对齐两种模式时,来自双方的一些信息可能会丢失,因为两个不同的结构被迫对齐。
此外,我们还进行了 ZSL 和广义 FSL ( generalized FSL )实验,以验证所提出的自适应机制的重要性。
4.3 Adaptiveness Analysis
 Figure 3: (a) 不同 shot 次数下的AM3及其对应主干的比较 (b) 考虑到两个主干,不同 shot 数量的 λ(在整个验证集上)的平均值。
Figure 3: (a) 不同 shot 次数下的AM3及其对应主干的比较 (b) 考虑到两个主干,不同 shot 数量的 λ(在整个验证集上)的平均值。
我们认为自适应机制是上一节中观察到的性能提升的主要原因。 我们设计了一个实验来定量验证 AM3 的自适应机制可以合理有效地调整其对两种模态的关注。
图 3(a) 显示了我们的模型与在 miniImageNet 上测试的两个主干(ProtoNets++ 和 TADAM)在 1-10 个镜头场景下的准确性相比。 从图中可以清楚地看出,AM3 与相应主干之间的差距随着镜头数量的增加而减小。 图 3(b) 显示了不同 shot 和骨干的混合系数 λ 的均值和标准差(在整个验证集上)。
首先,我们观察到 λ 的平均值与镜头数量相关。 这意味着随着镜头数量(因此,视觉数据点的数量)的减少,AM3 在文本模式上的权重更大(而在视觉模式上的权重更小)。 这种趋势表明,当来自视觉方面的信息非常少时,AM3 可以自动将其焦点更多地调整到文本模态以帮助分类。 其次,我们还可以观察到 λ 的方差(如图 3(b)所示)与 AM3 及其主干方法的性能差距(如图 3(a)所示)相关。 当 λ 的方差随着镜头数量的增加而减小时,性能差距也随之缩小。 这表明 AM3 在类别级别的适应性对性能提升起着非常重要的作用。
5 Conclusion
在本文中,我们提出了一种可以自适应有效地利用跨模态信息进行小样本分类的方法。 所提出的方法 AM3 提高了基于度量的方法的性能在不同的数据集和设置上大幅接近。 此外,通过利用无监督的文本数据,AM3 在小样本分类方面的表现明显优于现有技术。 文本语义特征对非常低(视觉)数据机制(例如一次性)特别有用。 我们还进行了定量实验,表明 AM3 可以合理有效地调整其对两种模态的关注。
补充:
如果 GloVe 的词汇表中没有针对某个类别的注释(tieredImageNet 中有 4 个案例),我们从范围 (-1, 1) 的均匀分布中随机采样嵌入的每个维度。
此外,在训练期间,我们添加了等式 1 和 3 中所示的额外损失,以确保在视觉方面学习的度量空间与少样本测试场景相匹配。
我们在上面提到的所有模态对齐基线和 AM3 实现(带有两个主干)中都使用了这个主干。 我们将 ProtoNets++ 称为具有这种更强大主干的原型网络 [47] 实现。
混合机制的变换 h 还包含一个具有 300 个单位的隐藏层,并为 λc 输出单个标量。















 780
780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









