







前言
本文提出了一种利用跨模式(cross-modal)信息(视觉特征和语义特征)来增强基于度量的小样本学习的方法。
一般来说,当来自视觉模式的数据有限时,利用辅助模式的数据(属性,未被标记的文本语料库等)也可以帮助进行图像分类,这种方法在零样本学习中使用的特别多。在训练时,会通过模式对齐(modality-alignment)将视觉模式与辅助模式的数据映射到一块儿,从而迫使它们具有相同的语义结构。这样,辅助模式的数据就可以在测试时转移到视觉方面,从而能够识别新类。
但是,视觉和语义特征空间的结构是不同的,比如,对于某些物体来说,视觉特征可能会更加丰富,并且与文本相比更具有辨识性。如Figure 1所示,在分界线左边的图中,一些类可能在视觉上是相似的,但它们的语义特征是完全不同的;在右边的图中,具有相同语义特征的物体在视觉上却相差很大:

而且,当来自视觉模式的图像样本很少时,它提供的信息可能很片面并且含有噪声;而语义表示可以作为一种通用的先验知识来帮助网络进行学习。因此,在小样本学习中,与其将两种模式的数据进行对齐(将语义信息转换为视觉方面的数据),不如将两者看成是两种独立的知识,并且根据不同的场景自适应地对它们进行混合,以达到最优效果。由此,本文提出AM3(Adaptive Modality Mixture Mechanism),它能够自适应并且有选择地结合两种模式(视觉和语义)的信息,来进行小样本学习。
AM3是建立在基于度量的元学习之上的方法。在基于度量的元学习方法中,通过从视觉数据中学习得到一个度量空间,然后在该空间中通过比较距离来进行分类。而AM3在此基础之上,利用文本信息来进一步提升分类准确度。AM3能够利用视觉空间和语义空间中的优点,并根据场景的不同对两者的侧重程度进行调整。 比如在Figure 1左边的图中,AM3会更关注语义模式以得到通用上下文信息;在右边的图中,AM3会更关注视觉模式以获取局部视觉特征。
方法实现

上图是AM3模型的整体结构。在AM3中,通过扩展基于度量的小样本学习方法来整合语义结构,该语义结构是通过word-embedding模型 W W W得到的,它包括 D t r a i n ⋃ D t e s t D_{train} \bigcup D_{test} Dtrain⋃Dtest中所有类别的label embedding。在AM3中采用了一种新的原型表示,即视觉和语义特征表示的凸组合(convex combination),也就是说,在计算类原型时,除了考虑视觉特征,还要将语义特征也融合进来。对于类 c c c,新的原型可以被计算为:
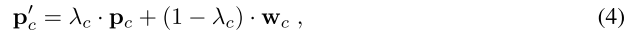
其中 λ c \lambda_c λc是自适应混合系数(adaptive mixture coefficien), w c = g ( e c ) w_c=g(e_c) w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









