









Large-Scale Few-Shot Learning via Multi-Modal Knowledge Discovery(解决大类别下的小样本学习)
关键点:视觉特征分块;语义弱监督的引入
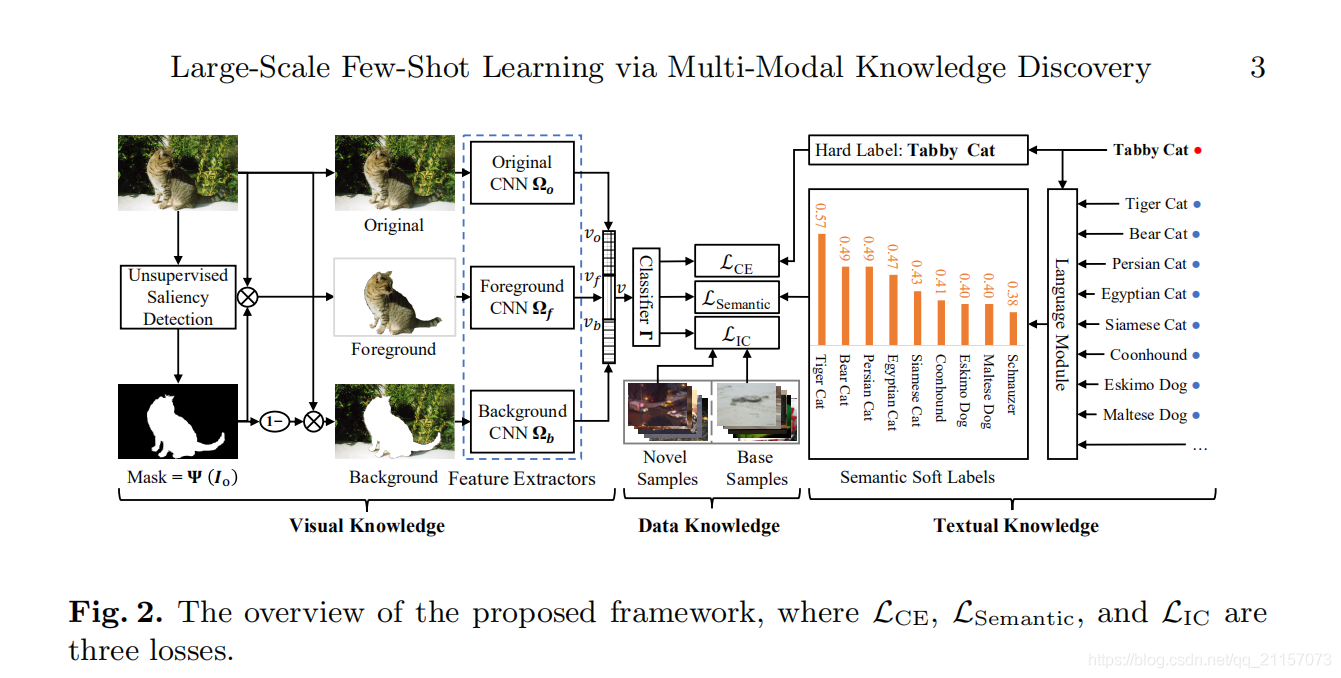
- 在视觉空间中,将图片分为三种,原始图片+前景图片+背景图片。其中前景背景是通过显著性检测得到。

- 分别正对原始图片,前景图片,背景图片输入到对应网络中提取特征,将三个得到的特征拼接为一个视觉特征。
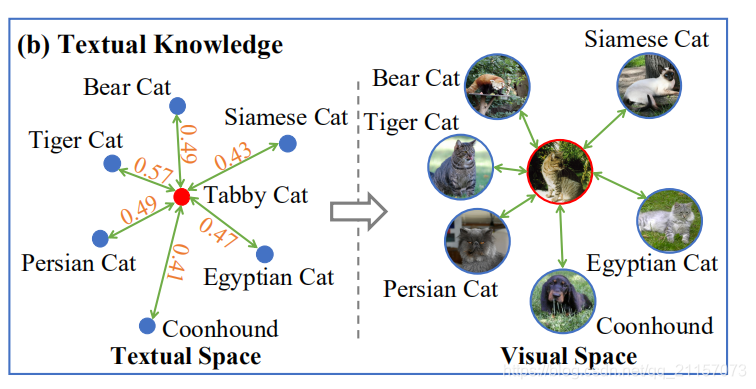
- 构建每个类的语义弱监督。计算novel类与base类的相似性,选取最大的几个。
- 损失函数:
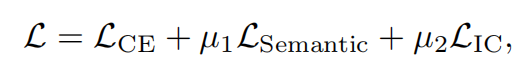

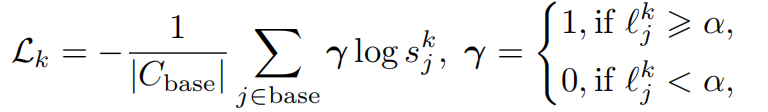
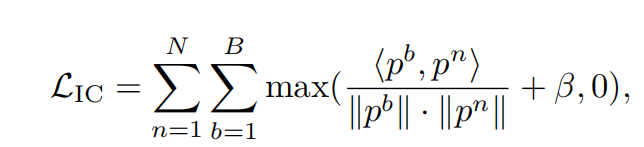
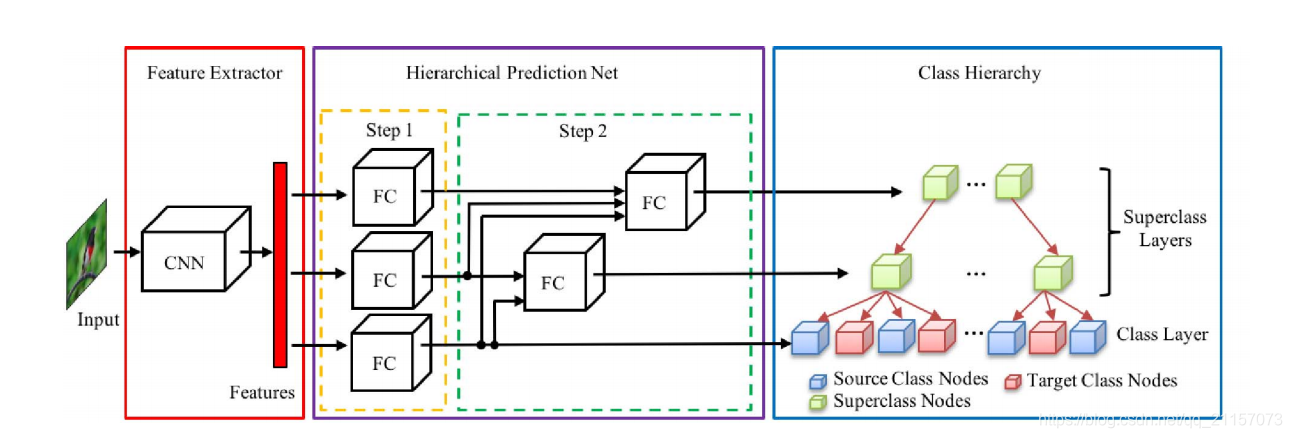
Large-Scale Few-Shot Learning: Knowledge Transfer With Class Hierarchy
关键点:使用语义信息将类别建模为层级结构;测试阶段使用最近临
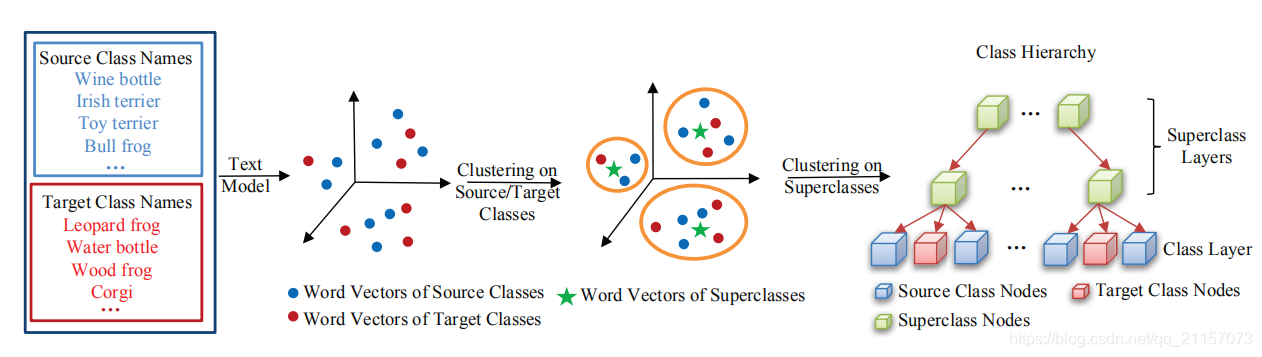
- 使用聚类方法,建立语义信息建立base类与novel类的树结构。
- 使用CNN提取图片的视觉特征。
- 视觉特征输入Hierarchical Prediction Net中,分两阶段预测层级结构
(1)step1:直接输入FC中预测每层的类别
(2)step2:融合不同层的信息预测类别 - 完成训练后,在测试阶段,使用KNN获得对novel类最近的样本完成分类。
Baby Steps Towards Few-Shot Learning with Multiple Semantics
关键点:原型网络;引入多层语义信息
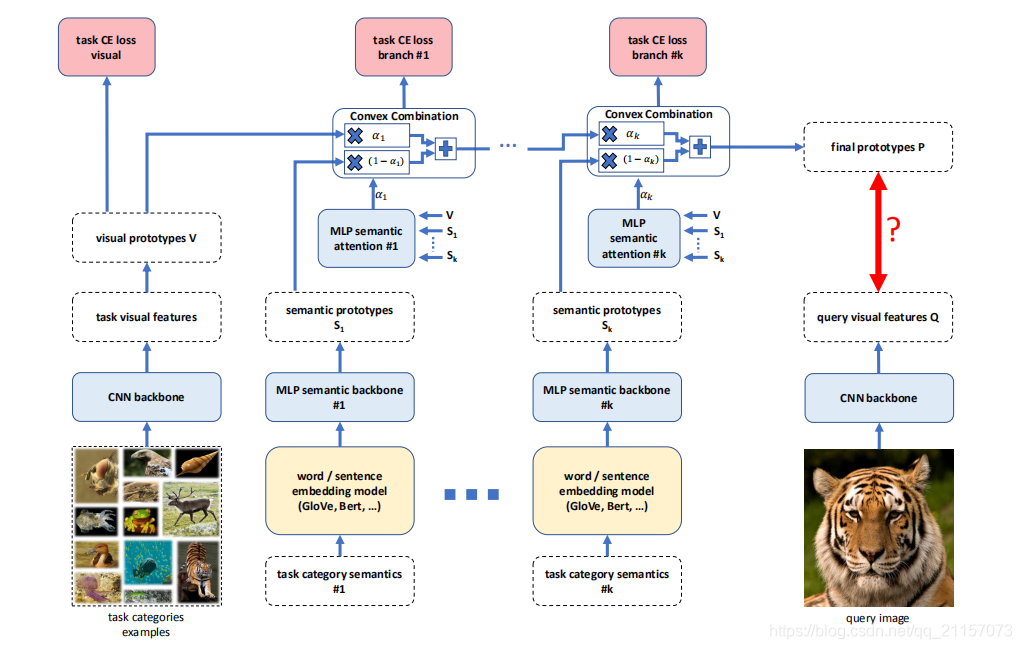
- 使用CNN提取视觉空间原型 V V V
- 多次提取语义原型 S 1 , S 2 . . . . . S k {S_1,S_2.....S_k} S1,S2.....Sk
- 针对每个语义信息,使用“Semantic attention”模块得到权重,得到多个原型:
P i = V i ⋅ α i + S i ⋅ ( 1 − α i ) P_i = V_i\cdot\alpha_i + S_i\cdot(1-\alpha_i) Pi=Vi⋅αi+Si⋅(1−αi)
其中 S i S_i Si是上一层传递过来的 - 最后得到原型
P
P
P:
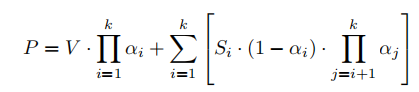
- 在计算损失过程中,与每层得到的原型 P i P_i Pi计算损失
Few-Shot Image Recognition with Knowledge Transfer
关键点:计算视觉特征与分类权重的余弦相似性;使用语义信息生成新类的分类权重
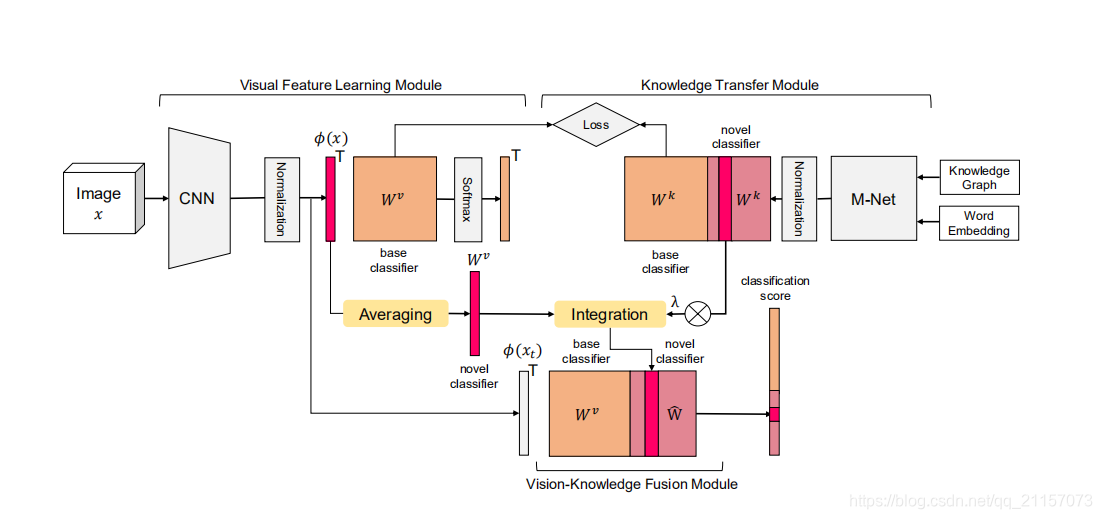
- 使用大量的数据训练
b
a
s
e
base
base类的分类权重:
W
v
W^v
Wv。其中的损失函数使用余弦相似,目标函数:
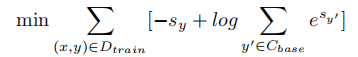
- 使用GCN将类别的语义信息映射为类别的分类权重 W k W^k Wk
- 计算 W k W^k Wk与 W v W^v Wv中的base类分类权重的相似度损失,以此来调整网络,相当于一个半监督学习。
- 最后的分类,使用视觉分类权重与语义生成权重配合完成,达到双空间互补分类的效果。
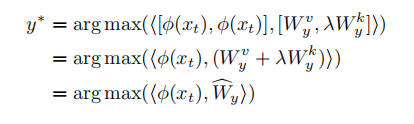
补充(参考文章,参考视频):
(1)使用Cosine similarity + softmax 完成分类

(2)使用Entropy 正则化,是使得预测更加合理
(3)使用好的初始化。
Adaptive Cross-Modal Few-shot Learning
关键:将语义原型加入prototype networks中,配合原有的视觉原型,完成自适应的分类,其中转换映射,自适应系数都是通过神经网络学习得来。
使用语义原型来补充视觉原型

Multimodal Prototypical Networks for Few-shot Learning(2021 wacv)
出发点:和上面一篇类似,也是使用语义信息调整视觉原型。相比于上篇,主要通过生成方式来解决
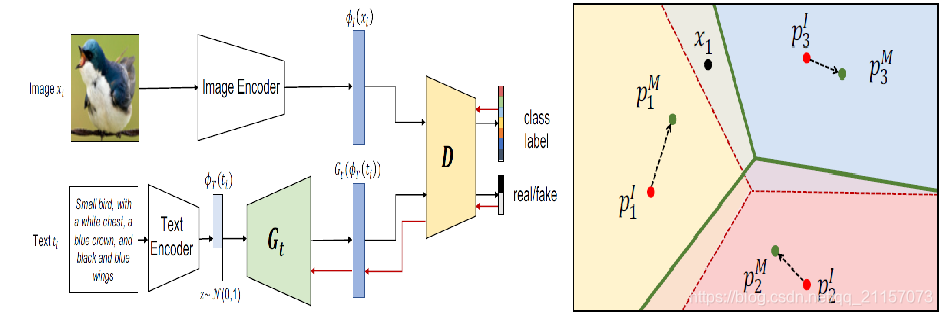
使用生成对抗网络训练模型,使得模型能够根据语义信息生成视觉特征,然后将每个类别生成的“视觉特征”与原始特征进行综合得到增强特征。
Towards Contextual Learning in Few-shot Object Classification(2021 WACV)
出发点:编码类别周围的上下文;引入语义信息
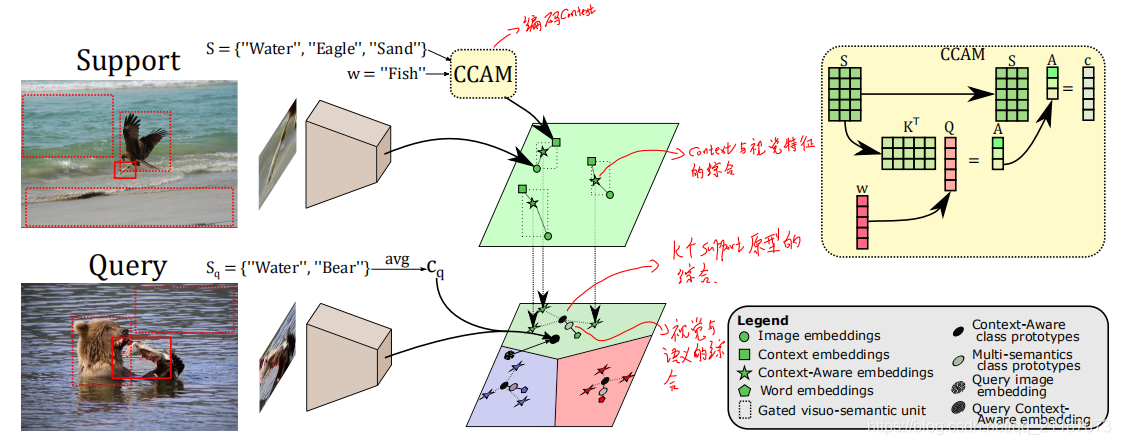
- 对于一个类别样本,首先使用语义空间编码其周围的的上下文环境,得到“上下文原型”,在编码过程中会使用到注意力:

- 将k-shot的“上下文原型”与“视觉特征原型”通过门单元综合为增强特征,也就是图中下方的黑点。
- 将综合特征与语义特征进行融合,得到最后的原型——灰点
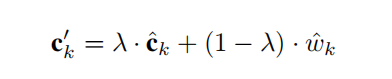

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









