







WEI BAO 1,2, MEIYU HUANG 1, AND XUESHUANG XIANG 1
1.Qian Xuesen Laboratory of Space Technology, China Academy of Space Technology, Beijing 100094, China
2.School of Information and Electronics Engineering, Beijing Institute of Technology, Beijing 100081, China
Corresponding authors: Meiyu Huang (huangmeiyu@qxslab.cn) and Xueshuang Xiang (xiangxueshuang@qxslab.cn)
ABSTRACT
episodic 训练中常用的损失函数(例如交叉熵和均方误差)力求实现嵌入空间中不同标签样本被无限距离(an infinite distance)分隔的严格目标【无限距离怎么说?】。 然而,学习到的嵌入空间并不能保证从大量类中采样的每个 episode 都能实现这个目标【怎么说?】。 取代无限距离,LMNC 损失仅仅需要将不同标签的样本用一个大边距分开,这可以很好地减轻传统损失函数的严格约束,很容易学得有判别性的嵌入空间。此外,考虑到不同类之间的多层次的相似性( multilevel similarity ),我们减轻了固定大边距的约束,并将 LMNC 损失扩展为加权 LMNC (WLMNC) 损失,这可以有效地利用类间信息,实现具有自适应类间边距的更可分离的嵌入空间。
INDEX TERMS: Few-shot classification, metric learning, large margin nearest center loss, weighted large margin nearest center loss
I. INTRODUCTION
受益于海量数据消耗,深度学习在各种计算机视觉任务 [1]、[2] 中取得了长足的进步,但在解决数据有限的问题上一直很吃力。 另一方面,人类有能力从几个实例中快速识别新类别。 人类和深度学习之间的巨大差距促使人们对少样本学习 [3] 产生了浓厚的研究兴趣,该学习试图模仿人类从有限的监督信息中学习新概念的能力。
小样本学习的最新进展采用两种类型的方法:基于元学习的方法和基于度量学习的方法,以避免在少量标记示例上过度拟合的危险。 前一种类型在基于优化方法 [5]-[9] 和建模方法 [10]-[14] 的辅助元学习 [4] 阶段进行训练,其中从各种小样本任务中学习任务通用信息作为先验知识来处理目标任务。 后一种类型采用相对简单的架构和距离函数来学习判别嵌入空间来迁移知识。
由于简单有效,基于度量学习的方法 [16]-[25] 在少样本分类中受到了相当大的关注。 基于度量学习的方法背后的关键思想依赖于基于情节的训练框架 [17],每个情节都有一个小的有标记的支持集和相应的查询集,它们从大量可用标记数据生成。基于情节训练框架,利用度量学习的最佳性能方法采用简单的架构来学习深度嵌入空间,其中来自支持集和查询集的相同标记示例之间的距离较小,而不同标记示例之间的距离较大。 然后将来自查询集和支持集的示例嵌入之间的距离用作执行分类的相似性概念(a notion of similarity)。对于判别式嵌入学习,交叉熵 (CE) [19] 和均方误差 (MSE) [20] 等损失函数通常用于情景训练,以实现严格目标,即来自查询集和支持集的相同标记示例之间的距离为 0,来自查询集和支持集的不同标记示例之间的距离为 1(假设最大距离为 1)(详见第 III-A2 节)。然而,学习到的嵌入空间并不能保证从大量类中采样的每一 episode 都能实现这个目标。如图 1 所示,考虑在 4 个类的数据集上训练的 3-way 小样本分类问题,用于在二维空间中嵌入学习,CE 或 MSE 学习到的嵌入空间只能确保每个 episode 中查询集和支持集最多一对不同标记的示例之间的距离为 1,其中我们采样了 3 个类,每个类包含几个支持示例和查询示例。有关更详细的介绍,请参阅第 III-A1 节。因此,CE 或 MSE 不能保证最终学习到的嵌入空间的判别能力。 为了充分发挥度量学习方法的潜力,本文提出在情景训练中采用大边距最近中心 (LMNC) 损失 [15]、[26],这需要来自查询集和支持集的所有不同标记的示例通过一个大边距分离,而不是最大距离。 由于放宽约束,LMNC 损失学习到的嵌入空间保证来自查询集和支持集的所有不同标记的示例对于所有 episodes 都以很大的间隔分开,从而导致有区别的嵌入空间。
 FIGURE 1. Illustrations of the comparison between episodic training using CE or MSE and LMNC loss [15]. Considering 3-way few-shot classification on a dataset with 4 classes for embedding learning in a 2-dimensional space, CE or MSE cannot ensure that the distances between all differently labeled examples from the query set and support set are 1 (assuming that the maximum distance is 1) for every episode. However, LMNC loss guarantees that all differently labeled examples from the query set and support set are separated by a large margin for all episodes, leading to a discriminative embedding space.
FIGURE 1. Illustrations of the comparison between episodic training using CE or MSE and LMNC loss [15]. Considering 3-way few-shot classification on a dataset with 4 classes for embedding learning in a 2-dimensional space, CE or MSE cannot ensure that the distances between all differently labeled examples from the query set and support set are 1 (assuming that the maximum distance is 1) for every episode. However, LMNC loss guarantees that all differently labeled examples from the query set and support set are separated by a large margin for all episodes, leading to a discriminative embedding space.
 FIGURE 2. Comparison between LMNC loss and WLMNC loss. More attention should be paid to distinguishing a cat from a tiger than from a truck. Instead of a fixed margin, as in LMNC loss, the margin learned by WLMNC loss between a cat and a truck can be smaller than that between a cat and a tiger because they are more similar.
FIGURE 2. Comparison between LMNC loss and WLMNC loss. More attention should be paid to distinguishing a cat from a tiger than from a truck. Instead of a fixed margin, as in LMNC loss, the margin learned by WLMNC loss between a cat and a truck can be smaller than that between a cat and a tiger because they are more similar.
尽管 LMNC 损失可以很好地缓解 CE 或 MSE 损失对嵌入学习的严格约束,但对于从大量样本中采样的无限的 episodes ,仍然难以在来自查询集和支持集的所有不同标记示例之间保持较大的边距。 另一方面,类似于[27]中考虑的从多模态任务分布中采样的任务,由多模态数据分布引起的各类之间的多级相似性存在于小样本分类中是很常见的。 LMNC 损失尝试以固定形式利用较大的余量将目标类和所有不同标记的类分开,忽略这种多级相似性。 此外,人类可以自适应地学习从各种类别中识别新类别。 如图 2 所示,很自然地,比起卡车,更应该注意区分猫和老虎,因为老虎与猫的相似度比与卡车的相似度更高。 为了通过有效利用类间信息的能力来增加 LMNC 损失,本文进一步提出在情景训练中采用加权 LMNC (WLMNC) 损失,目的是增加 LMNC 损失在分类相似类中的相对作用并减少它在分类不同类中的相对作用 . 我们工作的主要贡献归纳为以下三个方面:
- First, LMNC loss is adopted in episodic training to enhance
metric-learning-based few-shot classification methods, enabling the
learning of a more dis-criminative embedding space. - A mechanism that can effectively take advantage of intraclass
information via WLMNC loss is proposed, achieving a more separable
embedding space with adaptive interclass margins. - Various experiments are conducted on four datasets [17], [23], [28],
[29] and four state-of-the-art benchmarks [19], [20], [30], [31] to
verify the effectiveness of the introduced LMNC and WLMNC loss.
II. RELATED WORK
以前的工作[17]-[23]、[30]、[32]、[33]采用各种距离作为相似性的概念来进行分类。匹配网络 [17] 和原型网络 [19]、[22] 分别计算查询集和支持集中嵌入式示例之间的余弦距离和欧氏距离。基于原型网络,自适应模态混合机制(AM3)[31]利用跨模态信息来提高分类准确性。Meta-Baseline [30] 模型计算基类预训练阶段之后样本之间的缩放余弦距离,以更好地利用具有更强可转移性的预训练表示。类似地,利用欧氏距离,元置信度归纳(MCI)[34]建议元学习每个查询样本的置信度,为未标记的查询分配最佳权重,以便它们改善模型在看不见的任务上的转导推理性能。DeepEMD [33] 使用 the Earth Mover’s Distance 来计算密集图像表示之间的结构距离。关系网络[20]设计一个关系模块来学习嵌入空间中特征图对之间的相似性,而深度比较网络[21]利用不同层次的特征图对中的多个关系模块来获得更精确的相似性。
关于度量学习中使用的损失函数的文献,通常使用 CE [19] 和 MSE [20]。 另外,对比损失经常被用来有效地处理配对数据的关系。 由于在许多任务中的出色表现,[35]-[37] 已经见证了对比损失的最新进展 。 彭等人 [35] 提出了一种聚类方法,通过最小化每个数据点的成对样本分配之间的差异,考虑到使用不同度量将图像样本分配给聚类之间的不变性。 李等人。 [36] 提出了一种对比聚类方法,通过最大化正样本对的相似性同时最小化负样本对的相似性,显式地执行实例级和聚类级对比学习。[37] 提出了一种抗噪对比损失,通过同时学习表示和对齐数据来防止假阴性(false negatives)主导网络优化。此外,大量对比损失被提出,例如三元组损失 [38] 和大边距最近邻 (LMNN) [39],以最大化正样本对之间的相似性,同时最小化负样本对之间的相似性。 受这些工作的启发,在基于度量学习的少样本分类的 episode 训练中,利用对比损失(例如 [40]、[41])来学习更具判别力的嵌入空间。 与本研究最相关的工作是 [40] 中提出的附加边距损失,它直接增加了不同类别之间距离的边距。 根据数学推导,在 原型网络 [19] 上实现的这种附加边际损失等于 CE(交叉熵) 损失,该损失仍然需要将来自不同类别的示例以无限距离 分开。【数学推导是啥?】正如 [40] 中所报告的,由原始附加边际损失训练的模型与由原始 CE 损失训练的模型相比,性能略有提高。 这证实了在基于度量的少样本分类方法中,简单地在分类损失中添加一个固定的边距是有限的。 李等人 [40] 还提出了一种与类别相关的附加边际损失,其目的是根据每对类别在语义空间中的语义相似性为每对类别生成一个自适应边际。 我们工作中采用的 WLMNC 损失与类相关的附加边际损失有相似的想法; 然而,它是通过加权铰链损失( hinge loss)实现的,并且不利用任何额外的语义信息。 另一项相关工作 [41] 是应用于原型网络的三元组损失,其中试图在从支持集的给定原型到相同标记的查询示例和不同标记的查询示例的距离之间保持较大的边距 。 这种三元组损失与我们提出的 LMNC (WLMNC) 损失不同,后者旨在保持从给定查询示例到其目标类原型和不同标签的类原型的距离之间的较大余量。 与这种三元组损失相比,我们提出的 LMNC (WLMNC) 损失更直观和合理,因为给定的查询示例根据它与原型网络支持集中所有原型的距离分类为一个类 [19]。
我们提出的 WLMNC 损失利用了由多模态数据分布引起的各种类之间的多级相似性,这与多模态模型不可知元学习 (MAML) [27] 相关,因为很难找到适合采样自复杂的任务分布的不同任务的单个初始化。为了提高 MAML 在多模态任务分布上的性能,多模态 MAML 根据不同的任务模式学习自适应元学习先验参数。 这种自适应学习过程基于概念上类似于任务相关自适应度量(TADAM)的思想,它使用任务嵌入网络学习的任务表示来调节不同任务上的嵌入函数,以学习自适应任务相关度量空间。
III. METHOD
A. PRELIMINARIES
- EPISODIC TRAINING
- P-NET AND R-NET
P-net [19]: 这些原型为任一查询示例 x∗i 的类定义了一个预测器,它根据 x∗i 和原型 ck 之间的欧几里德距离 dE(hθ (x∗i ),ck ) 为任何类 k 分配概率,如下所示 :
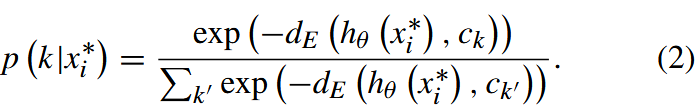
假设 q (k|x∗i) 是 x∗i 在任何类别 k 上的真实概率; 用于更新给定训练 episode 的 P-net 的损失函数是 CE: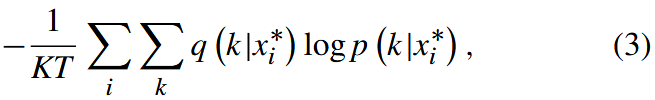
这强制要求一个查询示例与相同标记原型之间的距离变为 0,并且一个查询示例与不同标记原型之间的距离变为无穷大(如果假设最大距离为 1,则为 1)。 对于每个测试集,预测器 ˆyi = arg maxk p (k|x∗i) 用于将每个查询输入 x∗i 分类为最可能的类别。
R-net [20] 由两个模块组成:嵌入模块 fφ 和关系模块 gφ。 与 P-net 不同的是,关系模块 gφ 用于计算查询示例 x∗i 和支持集 Sk 在 0 到 1 范围内的相似度 ri,k,而不是固定距离函数,如下所示:
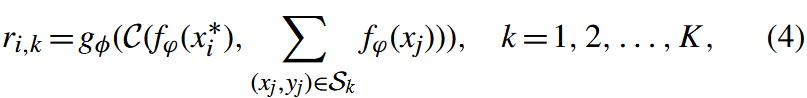
其中 C(·,·) 是特征图在深度上的拼接。 给定训练 episode 的损失函数是 MSE:
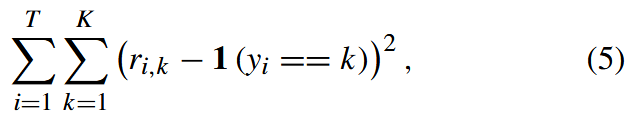
它将 ri,k 回归到基本事实( ground truth ):相同标记对的相似度为 1,不同标记对的相似度为 0。对于每个测试 episode,ri,k 用于将每个查询输入 x∗i 分类为最可能的类 ˆyi =arg maxj ri,k。
B. LMNC LOSS-AUGMENTED METRIC-BASED FEW-SHOT CLASSIFICATION
- LMNC LOSS
LMNC 损失在 [26 A semi-supervised privacy-preserving clustering algorithm for healthcare] 中首次提出,并在 [15 A lightweight neural network based human depth recovery method] 中由神经网络参数化; 它是为聚类问题而设计的,目标是缩小每个示例与其目标类中心之间的距离,同时将每个示例与其他不同标记的聚类中心分开很大。 通过分别用查询示例和支持集替换示例和类中心,episodic 训练的 LMNC 损失可以定义如下:

其中 d(·,·) 表示查询示例与支持集类别之间的距离。 δik ∈ {0,1}表示给定查询示例 x∗i 的标签 yi 是否等于 Sl 的标签(与 δil 相同)。 [χ]+ =max(χ,0) 表示铰链损失,m 是表示边距的正常量,β ≤1 是调整两项的正常量:(a) 最小化给定查询示例及其支持集的目标类之间的距离,以及 (b) 惩罚查询示例与支持集的所有其他不同标记类之间的小距离。
- IMPLEMENTATION ON P-net AND R-net
对于 P-net,等式(6)中查询示例 x∗i 和等式中的 Sk 之间的距离 d (xi,Sk)可以设置为 x∗i 和原型 ck 之间的欧几里得距离 dE (hθ(x∗i),ck) ,因为 Sk 由原型 ck 表示。 对于 R-net,d (xi,Sk) 直接替换为 1 − rik。 相应地,每个查询示例的类的预测也被细化为 ˆyi = arg mink d (xi,Sk)。 具体来说,为了强制 d (xi,Sk) 在 0 到 1 的范围内,d (xi,Sk) 被设置为维度 D 的归一化 dE(hθ(x∗i),ck)。
C. WLMNC LOSS-AUGMENTED METRIC-BASED
FEW-SHOT CLASSIFICATION
考虑到多模态数据分布导致各类之间的多级相似性,本文进一步放宽了LMNC损失对固定大边距的约束,并提出在episodic训练中采用WLMNC loss来学习具有自适应类间边距的类相关嵌入空间 . WLMNC loss 在[42]中首次引入,在[15]中也被神经网络参数化,旨在学习两个具有连续深度的相似簇之间相对较小的边距,以获得更好的深度恢复结果。 相比之下,为了获得更好的分类性能,情节训练的 WLMNC 损失基于这样一个概念,即不相似的类之间应该保持相对较小的边距,因为它们可以很容易地被区分。 具体来说,情景训练的 WLMNC 损失定义为:

其中引入了一个额外的系数 ωkl 来自适应地调整由上面定义的入侵三元组引起的铰链损失的惩罚权重。特别地,ωkl被定义为:
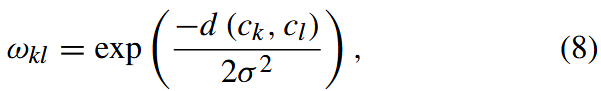
这取决于支持集的目标类k的中心ck与支撑集的另一个标记类的中心cl之间的距离d (ck,cl)。σ是一个预定义的常量。具体来说,我们用dE (ck,cl)代替P-net的d (ck,cl),用1 - gφ(C(ck,cl))代替R-net。ωkl 的上述定义表示不同的类间信息,这意味着方程(7)中的目标函数更严重地惩罚了侵入具有相似类的三元组引起的铰链损失。
由于情景训练为每个 episode 产生不平衡的类中心,直接使用 ck 和 cl 来计算类 k 和类 l 之间的距离很容易导致有偏差的 ωkl。为了减轻支持集中的类中心与 Dtrain 中的类中心之间的偏差,可以对 ck 和 cl 实施两个改变。首先,我们可以从 K 个类中的每个类中采样大量示例,以计算每个剧集的类中心。其次,考虑到类中心应该相对稳定,我们每多个 episode 而不是每个 episode 更新类中心。因此,方程(8)中的 ck 和 cl 将被替换为 ˆcj 和 ˆcl,它们分别代表最后更新的目标类中心和不同标记的类中心。算法 1 中提供了 P-net 和 R-net 的情景 WLMNC 损失计算的伪代码。此外,我们在具有 LMNC 损失的模型收敛后开始更新基准方法的 WLMNC 损失函数,以避免训练初始阶段不可靠的类中心。
Algorithm 1 P-Net 和 R-Net 的情景 WLMNC 损失计算。 M (> N) 是用于计算 ˆcv 的每个类的样本数。 s 是更新所有类中心的步长。RandomSample(C,L) 表示从集合 C 中随机均匀选择的一组 L 个元素,无需替换。


与 [15]、[42] 中提出的 WLMNC 的比较。 自适应类间边距的想法已经在 [15]、[42] 中使用,但具有不同的动机和技术。 [15]、[42]中提出的WLMNC loss旨在获得更好的深度恢复结果而不是更好的分类性能,学习两个相似簇之间相对较小的margin,而本文中的WLMNC loss旨在学习两个相似类之间相对较大的margin 以获得更好的小样本分类性能。 关于方程(8)中附加系数ωkl的实现,[15]、[42]中的ωkl在ck和cl的两个相似簇之间应该更小,而我们的ωkl应该更大。
IV. EXPERIMENTS
A. DATASETS
B. IMPLEMENTATION DETAILS
- OPTIMIZATION SETUP
我们还对 4-Conv 和 ResNet12 主干采用了不同的优化策略。 所有 4-Conv 网络都使用自适应矩估计 (Adam) [43] 进行训练,初始学习率为 10-3。 我们分别将 P-net 和 R-net 的学习率每 104 次迭代和 105 次迭代减半。 对于具有 WLMNC 损失的模型,我们使用 s = 1000(更新所有类中心的步长)和 M = 20(每个类的样本数)来更新 Omniglot 上的 ˆck。 对于 ResNet12,我们使用具有 0.9 动量和 5e−4 权重衰减的随机梯度下降 (SGD) 优化器。 学习率初始化为 0.1,并在所有数据集的第 40,000 次、第 50,000 次和第 60,000 次迭代中衰减 0.1 倍。 对于 1-shot 和 5-shot 任务,每批次的任务数分别为 4 和 2。 对于 WLMNC 损失增强模型,我们使用 M =300 和 s =100 来更新 ˆck。【M和s有两次设置?】
C. RESULTS
- EMBEDDING LEARNING PERFORMANCE
我们使用 t 分布随机邻域嵌入 (t-SNE) 从 miniImageNet 的训练集中可视化 5 个选定类的嵌入学习结果,并显示 P-net 的一个 5 路 1-shot 集的分类结果以说明嵌入学习中与 CE 损失相比 LMNC 和 WLMNC 损失的有效性。 如图 3 所示,与 CE 损失相比,LMNC 损失可以生成更具判别力的嵌入空间,导致 0 类(饮料杯)与 2 类(钢琴)的分离,并且可以正确预测来自第 0 类的查询示例的标签 。此外,通过利用多模态数据分布引起的各类之间的多级相似性,和更加关注相似的类,WLMNC loss 进一步正确区分了两种狗(第 1 类和第 3 类),而在使用 LMNC loss 时 ,该狗被错误分类为相似的 3 类而不是 1 类。
 FIGURE 3. 使用t-SNE可视化从miniImageNet训练集中选取的5个类的嵌入学习结果,以及P-net[19]的一个5-way 1-shot episode 的分类结果
FIGURE 3. 使用t-SNE可视化从miniImageNet训练集中选取的5个类的嵌入学习结果,以及P-net[19]的一个5-way 1-shot episode 的分类结果
- IMPACT OF THE HYPERPARAMETERS
边距 m 和调整因子 β 决定了 LMNC 损失增强模型的性能。 我们通过实验评估了它们的影响,并与 miniImageNet for P-net 上的 5-way 1-shot 任务的 CE 损失进行了比较。 在图 5 (a) 中,我们设置 m = 0.01 并根据指数衰减 {2−4,…,2−14} 改变 β 以评估 β 的影响。 类似地,我们设置 β =0.001 并根据指数衰减{2-1,…,2-7} 改变 m 以评估图 5 (b) 中 m 的影响。 据观察,在 m 和 β 的大范围内,LMNC 损失增强的 P-net 超过了使用 CE 损失的 P-net,表现出高鲁棒性。 FIGURE 5. 两个超参数的影响:(a) margin m和 (b)调整因子β。在m和β的大范围内,LMNC损失增强P-net超过了原始利用CE损失的P-net[19]。
FIGURE 5. 两个超参数的影响:(a) margin m和 (b)调整因子β。在m和β的大范围内,LMNC损失增强P-net超过了原始利用CE损失的P-net[19]。
- MULTILEVEL SIMILARITY EVALUATION
为了验证少样本分类中存在多级相似性,我们在 miniImageNet 上为 P-net 计算所有类对之间的相似性以获得 ωkl 矩阵。 我们选择了 64 个训练类,然后将所有类重新排序,将同一模式的类放在一起; 然后,得到一个 64 × 64 的矩阵,如图 6 左侧部分所示。矩阵中较白的区域对应于较大的 ωkl 值,这表明两个类更相似。 我们假设数据遵循 4-mode 分布,每种模式有 16 个类,并使用 Mp 表示一个包含模式 p 中所有类的子集。 |MP| 是 Mp 中的类数。 那么,模式p和模式q之间的权重ωpq是模式p和模式q中的类组成的所有类对之间的权重ωkl的平均值,可以写:
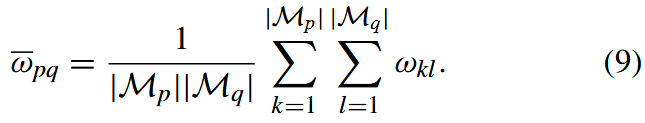

 FIGURE 6. 在miniImageNet上P-net[19]的多模态数据分布图示。
FIGURE 6. 在miniImageNet上P-net[19]的多模态数据分布图示。
如图 6(a) 所示,第 2 种模式中的类别多为圆柱形物体,如水杯、垃圾桶、口红和啤酒罐,第 3 种模式中的类别均为动物,如不同的狗、狐狸和鸟。此外,ω22 = 0.8346 和 ω33 = 0.7835,表明模内相似度都大于模间相似度 ω23 =0.6659,这说明第二模式中的类与第三模式中的类不同。 R-net 也存在类似的现象,W = [ωpq] 的对角线元素都大于 W 的非对角线元素,证实了少样本分类中存在多级相似性。因此,WLMNC 损失在对相似类进行分类时相对增加铰链损失的惩罚权重是很自然的,因为可以轻松区分来自不同模式的不相似的类,并且来自相同模式的相似类强烈影响模型性能。值得注意的是,图 6(b) 中 R-net 的 W 是不对称的,这是由于特征图在深度上的拼接 C(·,·),产生了不对称的关系分数。
- COMPARISON WITH OTHER FEW-SHOT LEARNING
METHODS

V. CONCLUSION
本文首先提出在基于度量的少样本分类方法的情景训练中采用 LMNC 损失,以学习更具判别力的嵌入空间并获得更准确的分类结果。 然后,考虑到各个类之间的多级相似性,本文进一步提出采用WLMNC loss来提高模型有效利用类间信息的能力。 性能通过四个基于度量的小样本学习基准在各种小样本数据集上的实验结果得到验证。 特别是,LMNC 和 WLMNC 损失可以在 miniImageNet 上的原型网络中分别获得 1.86% 和 2.46% 的增益,用于 5-way 1-shot 场景。 未来,我们将在人工数据集上理论上分析这两个损失函数,然后在更复杂的网络以及更具挑战性的数据集上测试它们。















 611
611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









