







Abstract
本文提出了一种用于少样本关系分类的多级匹配和聚合网络(MLMAN)。 先前关于该主题的研究采用原型网络,它独立计算查询实例的嵌入向量和每个支持集的原型向量。 相比之下,我们提出的 MLMAN 模型通过在本地和实例级别考虑它们的匹配信息,以交互方式对查询实例和每个支持集进行编码。 每个支持集的最终类原型是通过对其支持实例的表示进行注意聚合(attentive aggregation)获得的,其中权重是使用查询实例计算的。 实验结果证明了我们提出的方法的有效性,在 FewRel 数据集上实现了新的最先进的性能。
6 Conclusions
在本文中,提出了一种用于少样本关系分类的具有多级匹配和聚合的神经网络。首先,查询和支持实例通过本地匹配和聚合进行交互编码。然后,进一步聚合类中的支持实例以形成类原型,并通过基于注意力的实例匹配计算权重。最后,使用可学习的 MLP 匹配函数来计算查询实例与每个候选类之间的类匹配分数。此外,设计了一个额外的目标函数来提高类中所有支持实例的向量表示之间的一致性。实验证明了我们提出的模型的有效性,该模型在 FewRel 数据集上实现了最先进的性能。研究利用远程监督生成的数据的少样本关系分类并将我们的 MLMAN 模型扩展到零样本学习将是我们未来工作的任务。
1 Introduction
关系分类(RC)是自然语言处理(NLP)中的一项基本任务,旨在识别文本中两个实体之间的语义关系。 例如,实例“[London]e1 is the capital of [the UK]e2”表示伦敦和英国两个实体之间的关系 capital of。
一些传统的关系分类方法(Bethard 和 Martin,2007 年;Zelenko 等人,2002 年)采用了监督训练,并且缺乏大规模的手动标记数据。 为了解决这个问题,提出了远程监督方法 (Mintz et al., 2009),它通过启发式地对齐知识库 (KB) 和文本来注释训练数据。 然而,KBs 中的长尾问题(Xiong et al., 2018; Han et al., 2018)仍然存在,使得很难用很少的训练样本对关系进行分类。
本文着重于小样本关系分类任务,该任务旨在解决长尾问题。 在这个任务中,每个关系只给出少数(例如,1 或 5 个)支持实例,如表 1 中的示例所示。
少样本学习问题已在计算机视觉(CV)领域得到广泛研究。一些方法采用元学习架构(Santoro et al., 2016; Ravi and Larochelle, 2016; Finn et al., 2017; Munkhdalai and Yu, 2017),从以前的经验(例如训练集)中学习快速学习能力然后快速推广到新概念(例如,测试集)。其他一些方法使用基于度量学习的网络(Koch 等人,2015;Vinyals 等人,2016;Snell 等人,2017),它们学习类之间的距离分布。原型网络是一种简单有效的基于度量的小样本学习方法(Snell 等人,2017)。在原型网络中,查询和支持实例被独立编码到嵌入空间中。然后,每个类候选的原型向量被导出为嵌入空间中它的支持实例的平均值。最后,通过计算查询的嵌入向量与所有类原型之间的距离来执行分类。这种原型网络方法最近也被应用于少样本关系分类(Han et al., 2018)。
本文提出了一种用于少样本关系分类的多级匹配和聚合网络(MLMAN)。与表示不依赖于查询实例的支持集的原型网络不同,我们提出的 MLMAN 模型通过考虑局部和实例级别的匹配信息,以交互方式对每个查询实例和每个支持集进行编码。在局部级别,查询实例和支持集的局部上下文表示按照句子匹配框架(Chen et al., 2017)相互软匹配。然后,使用最大和平均池化将匹配的局部表示聚合到每个查询和每个支持实例的嵌入向量中。在实例级别,查询实例与每个支持实例之间的匹配度是通过多层感知器(MLP)计算的。以匹配度为权重,将支持集中的实例聚合形成类原型,进行最终分类。 MLMAN 模型中的所有这些匹配和聚合层都是使用训练数据联合估计的 【???】。由于每个类中支持实例的表示被预期为彼此接近,因此进一步设计了一个辅助损失函数来衡量每个类中所有支持表示之间的不一致性。
总之,我们在本文中的贡献是三方面的。 首先,提出了一种多级匹配和聚合网络,以交互方式对查询实例和类原型进行编码。 其次,设计了一个辅助损失函数来衡量支持实例之间的一致性。 第三,我们的方法在公开少样本关系分类数据集 FewRel 上实现了新的最先进的性能。
2 Related Work
2.1 Relation Classification
关系分类是在一个句子中识别两个实体之间的语义关系。 近年来,神经网络已被广泛应用于处理这一任务。 Zeng et al(2014) 使用位置特征和卷积神经网络 (CNN) 分别捕获结构和上下文信息。 然后,采用最大池化操作来确定最有用的特征。 Wang et al(2016) 提出了多级注意力 CNN,它同时捕获了特定于实体的注意力和特定于关系的池化注意力,以便更好地识别异构上下文中的模式。 Zhou et al (2016) 提出了基于注意力的双向长短期记忆网络 (AttBLSTMs) 来捕捉句子中最重要的语义信息。 所有这些方法都需要大量的训练数据,并且无法快速适应从未见过的新类
2.2 Metric Based Few-Shot Learning
在少样本学习范式中,需要一个分类器来泛化到只有少量训练样本的新类。 基于度量的方法旨在学习一组投影函数,这些函数从目标问题中获取支持和查询样本,并以前馈方式对它们进行分类 (The metric based approach aims to learn a set of projec-
tion functions that take support and query samples from the target problem and classify them in a feed forward manner.)。 与基于元学习器的方法相比,这种方法具有更低的复杂性并且更容易实现(Ravi 和 Larochelle,2016;Finn 等人,2017;Santoro 等人,2016;Munkhdalai 和 Yu,2017)
已经为计算机视觉 (CV) 任务开发了一些基于度量的小样本学习方法,所有这些方法都将每个支持或查询图像独立编码为一个向量以进行分类。 Koch 等人(2015)提出了一种学习孪生神经网络的方法,该方法采用独特的结构来分别编码支持和查询样本,并增加一层计算每对之间的诱导距离度量(the induced distance metric)。 Vinyals et al (2016) 提出学习一个用注意力和外部记忆增强的匹配网络。此外,基于测试和训练条件必须匹配的原则,提出了一种基于情节的训练程序,并已被许多后续研究采用。 Snell 等人 (2017) 提出了原型网络,该网络学习一个度量空间,其中可以通过计算与所有类的原型表示的距离来执行分类,并且每个类的原型表示是其所有支持样本的平均值。 Garcia 和 Bruna (2017) 定义了一种图神经网络架构来吸收通用的消息传递推理算法,该算法概括了上述三个模型。
关于少镜头关系分类,Han et al (2018) 采用原型网络在 FewRel 数据集上构建基线模型。 Gao et al (2019) 提出了基于混合注意力的原型网络来处理小样本学习中的噪声训练样本。 在本文中,我们通过多级匹配和聚合对查询实例和类原型进行交互编码,改进了用于少样本关系分类的传统原型网络。
2.3 Sentence Matching
句子匹配对于许多 NLP 任务都是必不可少的,例如自然语言推理 (NLI) (Bowman et al., 2015) 和响应选择 (Lowe et al., 2015)。一些句子匹配方法主要依赖于句子编码(Mueller and Thyagarajan, 2016; Conneau et al., 2017; Chen et al., 2018),它们独立编码一对句子,然后将它们的嵌入传输到分类器中,例如一个神经网络,来决定它们之间的关系。其他一些方法基于联合模型(Chen et al., 2017; Gong et al., 2017; Kim et al., 2018),它们使用交叉特征来表示局部(即单词级和短语级)对齐以获得更好的性能。在本文中,我们遵循联合模型来实现查询实例和类的支持集之间的局部匹配。我们的任务与上面提到的其他句子匹配任务之间的区别在于,我们的目标是将一个句子匹配到一组句子,而不是另一个句子 (Bowman et al., 2015) 或一个句子序列 (Lowe 等人,2015)。
3 Task Definition
在少样本关系分类中,我们有两个数据集,Dmeta-train 和 Dmeta-test。 每个数据集由一组样本 (x, p, r) 组成,其中 x 是由 T 个词组成的句子,第 t 个词是 wt,p = (p1, p2) 表示两个实体的位置,r 是实例 (x, p) 的关系标签。 这两个数据集有自己的关系标签空间,彼此不相交。 在少镜头配置下,Dmeta-test 分为两部分,Dtest-support 和 Dtest-query。 如果 Dtest-support 包含 N 个关系类中的每一个的 K 个标记样本,则这个目标少样本问题 【之前有个目标问题,在这相对应】被命名为 N-way-K-shot。 Dtest-query 包含测试样本,每个样本都标有 N 个类别之一。 假设我们只有 Dtest-support 和 Dtest-query,我们可以使用 Dtest-support 训练模型并评估其在 Dtest-query 上的性能。 但受限于支持样本的数量(即N×K),很难从零开始训练一个好的模型。
尽管 Dmeta-train 和 Dmeta-test 具有不相交的关系标签空间,但 Dmeta-train 也可以用于帮助 Dmeta-test 上的少样本关系分类。 一种方法是 Vinyals 等人提出的范式。 (2016),它遵循测试和训练条件必须匹配的重要机器学习原则。 也就是说,我们也将 Dmeta-train 拆分为 Dtrain-support 和 Dtrain-query 两部分,并在训练阶段模拟了few-shot learning 设置。 在每次训练迭代中,从 Dtrain−support 中随机选择 N 个类,从每个类中随机选择 K 个支持实例。 这样,我们构建了训练支持集 S = {sik; i = 1, …, N, k = 1, …, K},其中 sik 是 i 类中的第 k 个实例。 此外,我们从这 N 个类别的剩余样本中随机选择 R 个样本,并构建训练查询集 Q = {(qj , lj ); j = 1, …, R},其中 lj ∈ {1, …, N } 是实例 qj 的标签。
4 Methodology
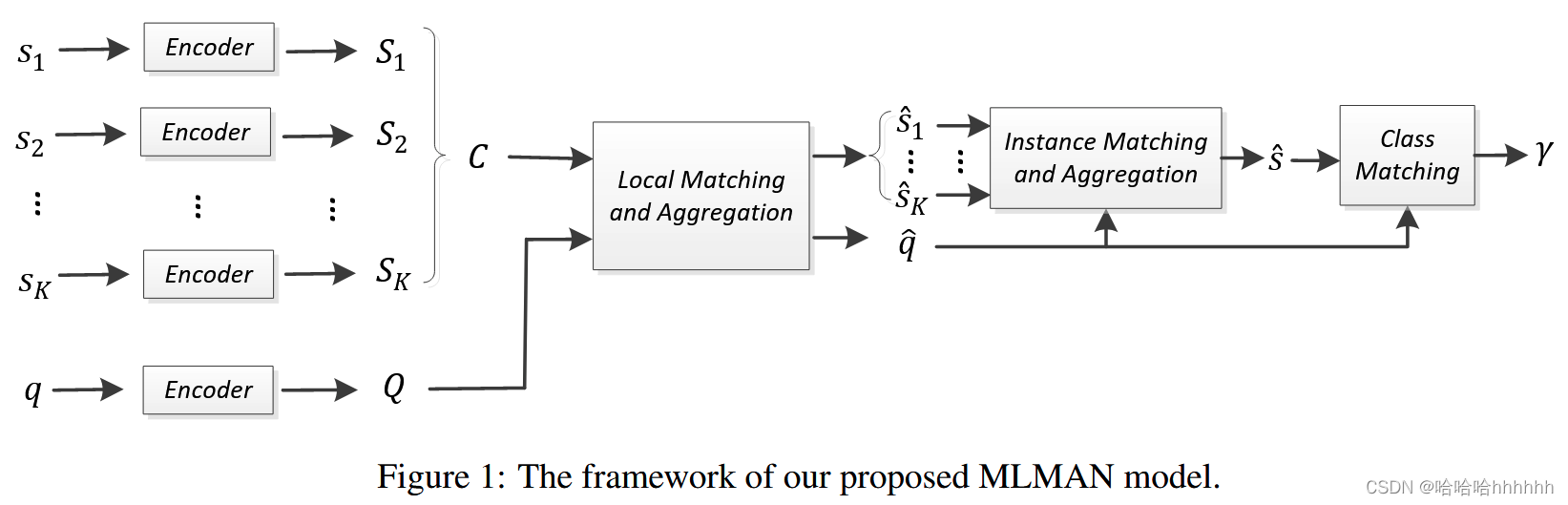
在本节中,我们将介绍我们提出的用于建模 f({sik} k=1-K, q) 的多级匹配和聚合网络 (MLMAN)。 为简单起见,我们将从 4.1 节到 4.4 节丢弃 sik 的上标 i,i 代表某个类别。 我们提出的 MLMAN 模型的框架如图 1 所示,它有四个主要模块。
• 上下文编码器(Context Encoder)。 给定一个句子和该句子中两个实体的位置,采用 CNNs (Zeng et al., 2014) 来获得句子中每个单词的局部上下文表示。
• 本地匹配和聚合(Local Matching and Aggregation)。 与 (Chen et al., 2017) 类似,给定查询实例的局部表示和 K 个支持实例的局部表示,采用注意力方法收集它们之间的局部匹配信息。 然后,匹配的局部表示被聚合以将每个实例表示为嵌入向量。
• 实例匹配和聚合(Instance Matching and Aggregation)。 使用 MLP 计算查询实例和 K 个支持实例中的每一个之间的匹配信息。 然后,我们将匹配度作为权重,对支持实例的表示进行求和,从而得到类原型。
• 类匹配(Class Matching)。 构建一个 MLP 来计算查询实例与类原型的表示之间的匹配分数。
这四个模块的更多细节将在下面的小节中介绍。
4.1 Context Encoder
对于查询或支持实例,句子 x 中的每个单词 wt 首先被映射到一个 dw 维词嵌入 et (Pennington et al., 2014)。 为了描述本实例中两个实体的位置信息,Zeng 等人(2014)提出的位置特征(PFs)也被我们的工作采用。 在这里,位置特征描述了当前单词与两个实体之间的相对距离,并进一步映射到 dp 维的两个向量 p1t 和 p2t。 最后,将这三个向量拼接起来得到单词表示 wt = [et; p1t; p2t] 的维度为 dw +2dp, instance 可以写为 W ∈ RT ×(dw +2dp)。
局部上下文编码最流行的模型是具有长短期记忆 (LSTM) (Hochreiter 和 Schmidhuber, 1997) 的循环神经网络 (RNN) 和卷积神经网络 (CNN) (Kim, 2014)。 在本文中,我们使用 CNN 来构建上下文编码器。 对于输入实例 W ∈ RT ×(dw +2dp),我们将其输入到带有 dc 个滤波器的 CNN 中。 CNN 的输出是一个 T × dc 维度的矩阵。 这样就得到了查询实例 Q ∈ RTq ×dc 的上下文表示和支持实例 {Sk ∈ RTk ×dc ; k = 1, …, K} 的上下文表示 ,其中Tq和Tk分别是查询语句和第k个支持语句的句子长度。
4.2 Local Matching and Aggregation
为了得到 Q 和 {Sk; k = 1, …, K} 之间的匹配信息,我们首先将 K 个支持实例表示拼接到一个矩阵中,如下所示。
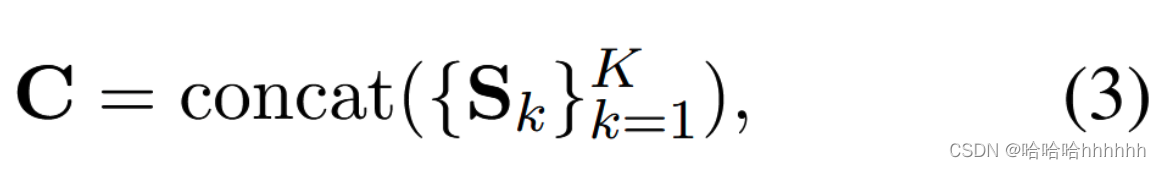
其中 C ∈ RTs×dc ,每行dc维,每列是每个支持样本的词的总数,且 Ts =( T1+T2+ …TK)。 然后,我们收集 Q 和 C 之间的匹配信息并计算它们的匹配表示 ~Q 和 ~S 如下。
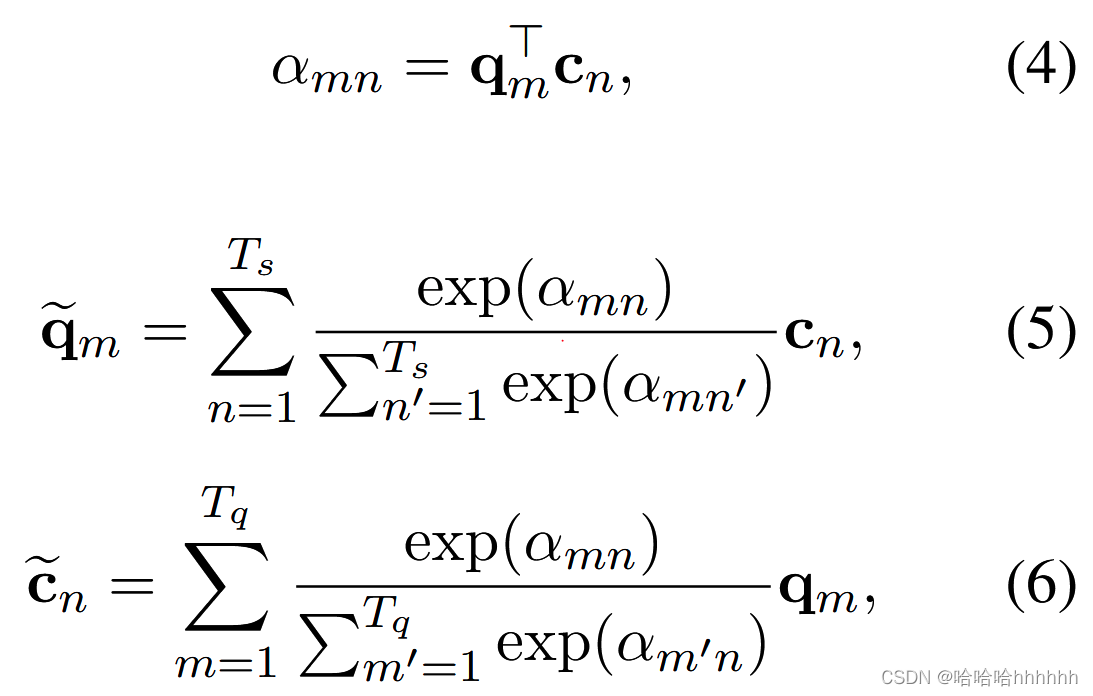
其中在方程式 (5) 中 m ∈ {1, …, Tq} , 在等式(6)中 n ∈ {1, …, Ts} ,qm和~qm分别是Q和 ~Q的第m行,cn和 ~cn分别是C和 ~C的第n行。
接下来,使用 ReLU 层融合原始表示和匹配的表示,如下所示,
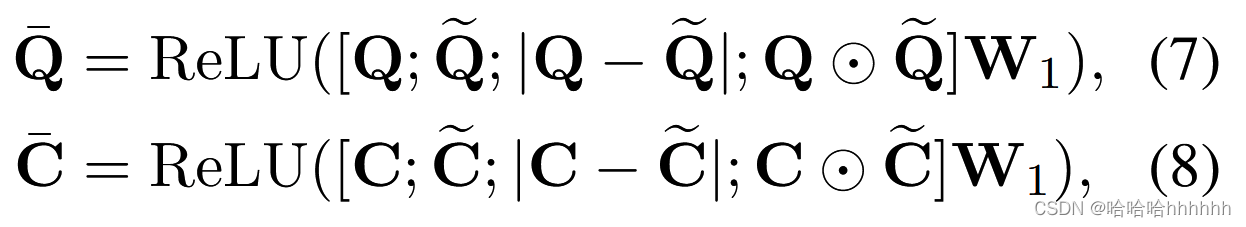 其中是元素乘积,W1 ∈ R4dc×dh 是该层的权重矩阵,用于降低维度。 -C 进一步分为 K 个表示 {-Sk} k=1-K 对应于 K 个支持实例,其中 -Sk ∈ RTk ×dh 。 所有 ̄Sk 和 ̄Q 被送入单层双向 LSTM (BLSTM),沿每个方向有 dh 个隐藏单元,以获得最终的局部匹配结果 ^Sk ∈ RTk ×2dh 和 ^Q ∈ RTq ×2dh
其中是元素乘积,W1 ∈ R4dc×dh 是该层的权重矩阵,用于降低维度。 -C 进一步分为 K 个表示 {-Sk} k=1-K 对应于 K 个支持实例,其中 -Sk ∈ RTk ×dh 。 所有 ̄Sk 和 ̄Q 被送入单层双向 LSTM (BLSTM),沿每个方向有 dh 个隐藏单元,以获得最终的局部匹配结果 ^Sk ∈ RTk ×2dh 和 ^Q ∈ RTq ×2dh
局部聚合旨在将局部匹配的结果转换为每个查询和每个支持实例的单个向量。 在本文中,我们将最大池化和平均池化一起使用,并将它们的结果连接成一个向量 ^sk 或 ^q。 计算如下

4.3 Instance Matching and Aggregation
与传统的原型网络(Snell et al., 2017)类似,我们提出的方法通过该类中所有支持实例的表示来计算类原型 ^s,即 { ^sk }k=1-K。 然而,我们没有使用简单的均值操作,而是通过 {̂ sk}Kk=1 上的注意力来聚合实例级表示,其中每个权重都来自 ̂ sk 和 q 之间的实例匹配分数。 匹配函数如下,

其中 W2 ∈ Rdh×8dh 和 v ∈ Rdh 。 βk 描述了查询实例 q 和支持实例 sk 之间的实例级匹配程度。 然后,将所有{ ^sk }k=1-K 聚合成一个向量 ^s 为, ^s是类的原型。
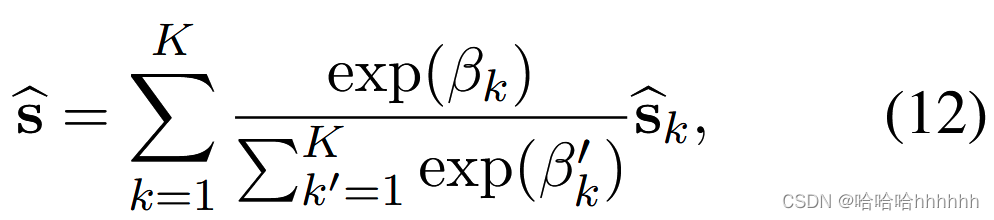
4.4 Class Matching
在确定了类原型 ^s 和查询实例的嵌入向量 ^q 后,等式(2)中的(the class-level matching function)类级匹配函数 f ({sk}K k=1, q) 定义为

等式 (11) 和 (13) 具有相同的形式。 在我们的实验中,在这两个方程中共享权重 W2 和 v,即在每次训练迭代中对实例级和类级匹配使用完全相同的函数,可以带来更好的性能。
如果一个类中所有支持实例的表示彼此相距很远,那么获得的类原型可能很难捕捉到所有支持实例的共同特征。 因此,设计了一个衡量支持实例集之间不一致性的函数。 为了避免直接比较一个类中每两个支持实例的高复杂度,我们将不一致性度量计算为支持实例与类原型之间的平均欧几里德距离:
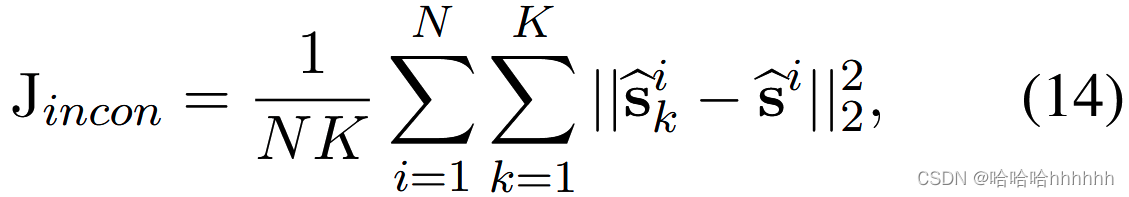 其中 i 是类索引和 || · ||2 计算一个向量的 2-范数。
其中 i 是类索引和 || · ||2 计算一个向量的 2-范数。
通过结合方程(1)和(14),训练整个模型的最终目标函数定义为
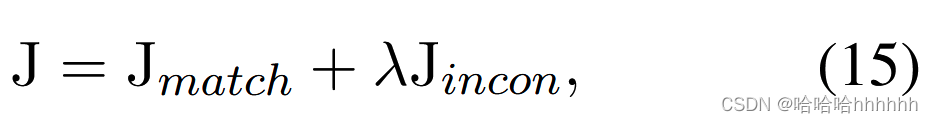
其中 λ 是一个超参数,在我们的实验中设置为 1,没有任何调整















 1776
1776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









