










2017-2019年计算机视觉顶会文章收录 AAAI2017-2019 CVPR2017-2019 ECCV2018 ICCV2017-2019 ICLR2017-2019 NIPS2017-2019
《FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation》
来源:EMNLP 2018
Introduction
对于关系分类任务,目前常见的方法都需要基于大规模的人工标注数据集。对于新的关系类别,大规模标注数据成本很高,而且需要与原来的数据一起进行重新训练。Few-Shot的方法可以借助少量的样本对新的关系进行分类,在图像领域的发展比较成熟,文本领域目前没有广泛应用的成熟的技术。本文提出了一个适用于Few-Shot关系分类的监督数据集,且应用了目前较成熟的几个Few-Shot方法进行了可行性实验,得到了一定效果。
主要贡献
· 将关系分类定义为few-shot learning任务,并提出了一个适用于few-shot关系分类任务的大规模监督数据集-FewRel
· 应用目前主流的few-shot learning方法于关系分类任务
· 应用本文提出的数据集进行各种方法的实验效果评估,并指出一些可能的研究方向
FewRel数据集
覆盖100种关系,每种关系700个实例。
1. 通过弱监督构建candidate set
2. 人工清洗得到最终数据
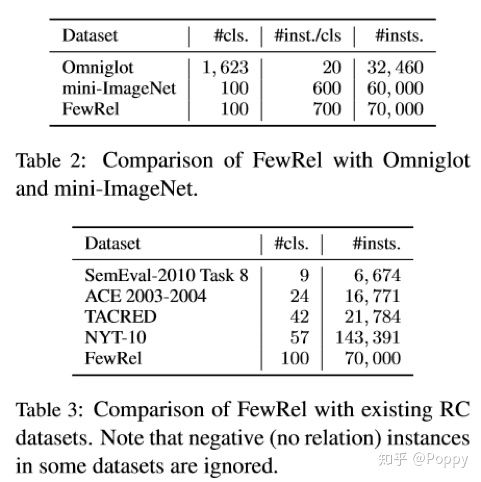
作者分别将FewRel与目前比较常用的few-shot图像数据集和关系分类任务数据集进行了数据量及分布对比。
任务设置
在few-shot关系分类任务中,我们的目标是通过比较少量的样本数据就可以对新的关系进行分类,希望得到函数
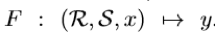
其中
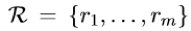
为关系集合,
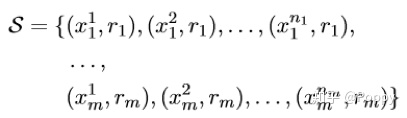
为支持集,对于每种关系,支持集中有nm个样本(这里指表达该种关系的句子)
对于query instance x, 我们希望预测其包含的实体关系分类。测试集的关系只来源于支持集,且支持集和训练集中的关系类别不重合。目前只探究对于支持集的关系达到分类效果,但是后续研究的目标还是希望可以对全部关系进行分类。
目前的研究中主要应用N way K shot设定,即对于N种关系,每种关系的支持集中包含K个样本。

实验设置
本文考虑了4种few-shot任务:5 way 1 shot, 5 way 5 shot, 10 way 1 shot, 10 way 5 shot,并采用五种常见的方法进行实验。
1. CNN/PCNN+Finetune/KNN
作者分别对CNN和PCNN应用finetune/KNN两种训练方法来进行few-shot.
- Finetune:在训练集中学习关系分类,在支持集上微调参数
- KNN:共同训练所有关系类别,测试时对所有instance进行embed,再用K近邻对测试instance进行分类。
2. Meta Network
元学习的一种算法,希望模型可以根据之前的知识学习新任务,不再把新的任务独立思考。利用一个base learner来监督训练过程,权重分为fast和slow两部分。对于fast weights可以简单理解为快速调整参数,比如用较大的学习率对支持集里的关系进行拟合,使之快速适应新任务,避免分类器倾向于样本多的类。Slow weights用来最小化分类损失。
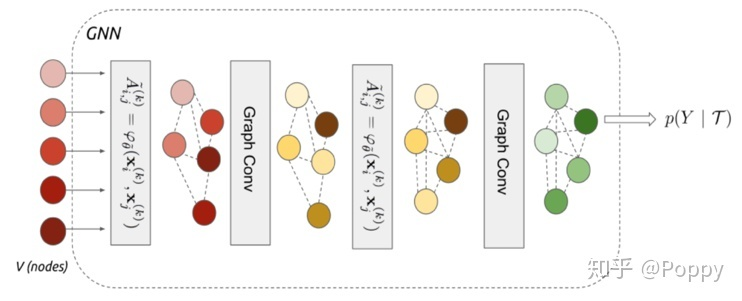
3. Graph Neural Network (GNN)
基于图的一种方法,把每一个实例样本看作一个节点,通过CNN学习节点的embedding,再通过节点embedding学习边的embedding,信息在节点间传递,测试时通过图的拓扑结构将支持集的信息传递给query样本来进行预测,最后输出样本的预测标签。
4. SNAIL
元学习的一种算法,利用神经网络和attention快速学习之前的经验知识。将支持集中的instance-label对进行排序构成序列,序列中支持集中的数据在前,需要预测的query instance在后。再用Temporal convolution和attention的方法,将支持集中的信息传递给query instance进行预测。
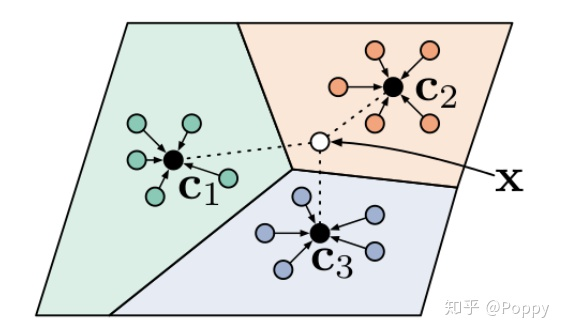
5. Prototypical Networks
原型网络是一种比较简单的方法,基于每个类都存在一个原型中心的想法。训练时学习如何拟合中心,测试时用支持集中的样本来拟合某个类的聚类中心,再用query instance 进行比较,选择最近的原型作为其分类。
实验结果
对于不同的实验设置,应用不同方法,结果如下:
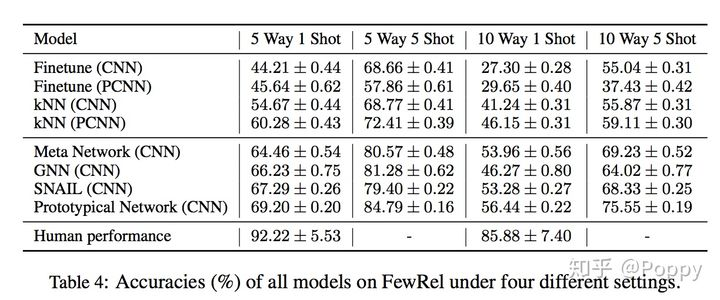
应用few-shot方法会比用finetune或KNN效果更好,但是和人的分类能力来比还是差距很大。同时指出在实验过程中,作者发现对于同种关系的差异化表达是模型比较难以学习到的:

上表的四个句子都表达educated_at关系,但是推理表达逻辑上差异很大,未来也许可以增加常识性信息来进行优化。

















 3957
3957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









