







现在对近几年一些比较经典的神经网络结构进行学习。其它如LeNet-5、AlexNet、VGGNet都有学习过,但除开有些东西已经很老了以外,近几年的神经网络结构更加优异也是事实,在此就不写出来了。
一、ResNet网络
ResNet网络又名残差网络,是2015年ILSVRC竞赛冠军。我们知道,特征的“等级”随增网络深度的加深而变高,网络的深度是实现好的效果的重要因素。但要实现比较深的网络是很难的,因为梯度消失和梯度爆炸的问题是训练深层次的网络的障碍,会导致无法收敛。
而ResNet网络使用了一种连接方式叫做“shortcut connection”,顾名思义,shortcut就是“抄近道”的意思,我们能够利用这一方法构建ResNet网络,从而实现一个深度神经网络。
1.残差块
ResNet网络是由残差块构建的,先来理解一下残差块的概念。下面是一个二层的神经网络。
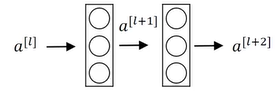
上图中先在l层进行激活得到l+1层再得到l+2层,过程如下,其中g表示激活函数ReLU
z
[
l
+
1
]
=
W
[
l
+
1
]
a
[
l
]
+
b
[
l
+
1
]
a
[
l
+
1
]
=
g
(
z
[
l
+
1
]
)
z
[
l
+
2
]
=
W
[
l
+
2
]
a
[
l
+
1
]
+
b
[
l
+
2
]
a
[
l
+
2
]
=
g
(
z
[
l
+
2
]
)
z^{[l+1]}=W^{[l+1]}a^{[l]}+b^{[l+1]}\quad\quad a^{[l+1]}=g(z^{[l+1]})\quad\quad z^{[l+2]}=W^{[l+2]}a^{[l+1]}+b^{[l+2]}\quad\quad a^{[l+2]}=g(z^{[l+2]})\quad\quad
z[l+1]=W[l+1]a[l]+b[l+1]a[l+1]=g(z[l+1])z[l+2]=W[l+2]a[l+1]+b[l+2]a[l+2]=g(z[l+2])
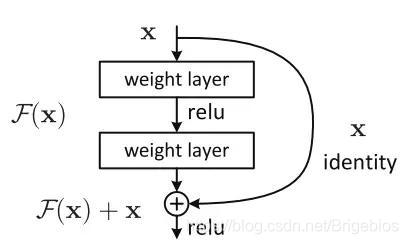
在残差网络中,我们在主路径的基础上再抄个近道,不沿着主路径传递,也就是表示如下
z
[
l
+
1
]
=
W
[
l
+
1
]
a
[
l
]
+
b
[
l
+
1
]
a
[
l
+
1
]
=
g
(
z
[
l
+
1
]
)
z
[
l
+
2
]
=
W
[
l
+
2
]
a
[
l
+
1
]
+
b
[
l
+
2
]
a
[
l
+
2
]
=
g
(
z
[
l
+
2
]
+
a
[
l
]
)
z^{[l+1]}=W^{[l+1]}a^{[l]}+b^{[l+1]}\quad\quad a^{[l+1]}=g(z^{[l+1]})\quad\quad z^{[l+2]}=W^{[l+2]}a^{[l+1]}+b^{[l+2]}\quad\quad a^{[l+2]}=g(z^{[l+2]}+a^{[l]})\quad\quad
z[l+1]=W[l+1]a[l]+b[l+1]a[l+1]=g(z[l+1])z[l+2]=W[l+2]a[l+1]+b[l+2]a[l+2]=g(z[l+2]+a[l])
上图中F(x)是一开始得到的l+2层的值,F(x)+x是我们应用跳跃连接得到的值,暂且设它为H(x)。
2.残差网络
构建一个ResNet网络就是通过将很多个这样的残差块堆积在一起,形成一个深度神经网络。我们知道了残差块的结构,明白了ResNet网络是怎么工作的,但为什么要这样设计呢?这样设计有什么用呢?来看看下面这张图

上面一层表示一个普通的网络,下面是残差网络。
我们知道,一个网络越深,它在训练集上训练网络的效率会有所下降,要更新下一层网络的权值就会变得很麻烦,所以错误率不降反增。
如果使用残差网络能够较好解决这一问题。假设我们的网络随着不断训练使x的值优化为最优解,如果是普通的网络继续下去错误率反而会提高。但使用残差网络,把F(x)替换为H(x)即F(x)+x,如果模型是最优的,很容易能把F(x)优化为0,这样就有H(x)=x,即当前层的与下一层都是最优解,可以理解为最优网络后面的层数都是废掉的(不具备特征提取的能力),实际上没起什么作用,这样就能很好解决网络的性能随着深度的增加而降低的问题了。当然在实际中x肯定是很难达到最优的,但是总会有那么一个时刻它能够无限接近最优解。采用ResNet的话,只用小小的更新F(x)部分的权重值就行了,不用像一般的卷积层一样大动干戈。
需要注意的是在残差块的F(x)+x中,两者的维度需要相同,这也是为什么残差网络中大量用到了1X1的卷积核的原因,或者也可以用全0填充一个升维的矩阵,都能解决问题。
二、GoogLeNet网络
GoogLeNet由Christian Szegedy等开发并且是2014年ImageNet ILSVRC挑战赛冠军。为了致敬卷积神经网络的鼻祖LeNet-5,GoogLeNet将L字母大写。它提出了Inception模块,同时增加了网络深度和宽度,使得GoogLeNet更加有效地使用参数。至今为止Google的研究者接连发布了Inception-v3,Inception-v4等版本,还有基于Inception-v3的Xception,获得了很好的效果。
1.Inception网络
在图像识别任务中简单地堆叠较大地卷积层非常消耗计算资源,Inception模块较好解决来了这一问题。Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏结。
下图是”原始“的Inception模块。它使用了3个不同大小的滤波器(1 X 1 , 3 X 3 , 5 X 5 )对输入执行卷积操作,此外,它还会执行最大池化。所有子层的输入最后会被级联起来,并传送至下一个Inception模块。

使用3X3,5x5的卷积核仍然会带来巨大的计算量。为了减少计算量,使用1x1的卷积核实现降维操作,以此来减小网络的参数量,如图所示。

添加了这些额外的1x1卷积之后,就构成了可实现降维的Inception模块。
使用Inception (V1)模块构建的GoogleNet:

这一网络实际上是重复堆叠的Inception模块构成的
为了阻止该网络中间梯度消失过程,作者引入了两个辅助分类器,它们对其中两个Inception模块的输出执行softmax操作,然后在同样的标签上使用计算辅助损失。实际测试的时候,这两个额外的softmax会被去掉 。
2.Xception网络
取自论文:《Xception: Deep Learning with Depthwise Separable Convolutions》
论文链接:https://arxiv.org/abs/1610.02357
Xception是google继Inception后提出的对Inception v3的另一种改进,主要是采用depthwise separable convolution来替换原来Inception v3中的卷积操作。
要介绍Xception的话,需要先从Inception v3讲起,Inception v3和Inception v1对比主要是将5*5卷积换成两个3*3卷积层的叠加。如下图Figure1所示

为什么要这么做呢?直观上来说,当卷积不会大幅度改变输入维度时,神经网络可能会执行地更好。过多地减少维度可能会造成信息的损失,这也称为「表征性瓶颈」。
使用2个3x3的卷积代替5x5的卷积,这样既可以获得相同的视野(经过2个3x3卷积得到的特征图大小等于1个5x5卷积得到的特征图),还具有更少的参数,还间接增加了网络的深度。因此能够解决表征性瓶颈的问题。
可以简化为下面的Inception结构,就是Figure 2。

接下来把3个独立的1X1卷积核整合起来再连接3个3X3的卷积,也就表示如下

这3个卷积操作只将前面1*1卷积结果中的一部分作为自己的输入,也就是原通道数的1/3。接下来以Figure3为基础,设定3X3卷积的个数和1X1卷积的输出通道数一样,即每个3*3卷积都是和1个输入的通道做卷积。可以表示为Figure4,如下图所示

上图中,该模块将输入数据在channel维度上进行解耦合,该模块称之为**‘extreme’version of Inception module**。而在Xception中,作者采用的是用depthwise separable convolution(深度可分离卷积)来替换原来Inception v3中的这一操作。
什么是depthwise separable convolution?看看下面这张图

上图中,a是传统的卷积操作,b和c就是depthwise separable convolution。
简单来说,输入通道数是M,要得到的输出通道数是N,a中用N个Dk X Dk X M的卷积核进行卷积能够完成操作。
在depthwise separable convolution中,输入通道和输出通道不变,但我们做的是对输入的每个通道分别用M个Dk X Dk X 1的卷积核进行卷积,得到了16个特征图谱。在融合操作之前,再对这M个特征图谱用N个1X1的卷积核进行卷积得到结果。
直观来说,传统的卷积操作所需参数为N X M X Dk X Dk;深度可分离卷积所需参数为M X Dk X Dk + N X M X 1 X 1,参数数量明显减少,计算效率更高。
depthwise separable convolution与原先的卷积操作有何不同呢?
depth wise separable convolutions:先进行channel-wise 空间卷积,然后1x1卷积进行融合
Inception:先进行1x1卷积,然后进行channel-wise空间卷积
depthwise separable convolution:两个操作之间没有激励函数
Inception:两个操作之间添加了ReLU非线性激励
下面是Xception网络

对于Xception模型而言,其一共可以分为3个flow,分别是Entry flow、Middle flow、Exit flow;分为14个模块,其中Entry flow中有4个、Middle flow中有8个、Exit flow中有2个。其中的SeparableConv就是depthwise separable convolution。此外,每个小块的连接采用的是residule connection(图中的加号),而不是原Inception中的concat。
论文中各项数据也表示了Xception网络相较于Inception来说有更好的表现,Xception作为Inception v3的改进,主要是在Inception v3的基础上引入了depthwise separable convolution,在基本不增加网络复杂度的前提下提高了模型的效果。事实上也达到了目的,以后有机会亲自实践。
三、SENet网络
SENet(Squeeze-and-Excitation Networks)获得了2017年ILSVR挑战赛的冠军,使得在ImageNet上的TOP-5错误率下降至2.25%。
论文:《Squeeze-and-Excitation Networks》
论文链接:https://arxiv.org/abs/1709.01507
SENet实际上是引入了Squeeze-and-Excitation模块,将这一模块插入到现有的各种网络中都能取得不错的效果。该模块主要用到的是Squeeze和Excitation两个操作,接下来结合论文看看这两个操作的作用。下面引用论文中一张图片
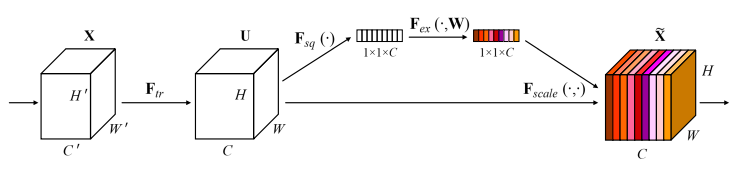
上图中X到U用到了Ftr操作,就是我们通常的卷积操作,在此不表。
1.Squeeze
上图中Fsq对应Squeeze操作,顾名思义就是把W(宽度)和H(高度)挤压成1X1大小,实际用到的是global average pooling(全局平均池化)操作。简单来说就是将每个二维的特征通道都变成一个实数,这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配,也就是C。
引用论文中的公式表示如下
Z
c
=
F
s
q
(
U
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
u
c
(
i
,
j
)
Z_c=F_{sq}(U_c)=\frac{1}{H\times W}\sum_{i=1}^H\sum_{j=1}^Wu_c(i,j)
Zc=Fsq(Uc)=H×W1i=1∑Hj=1∑Wuc(i,j)
2.Excitation
上图Fex对应的就是Excitation操作,论文中写到:它是一个类似于循环神经网络中门的机制。通过参数来为每个特征通道生成权重,其中参数被学习用来显式地建模特征通道间的相关性。以 Inception 结构为例,如下图

上图可以看出,在经过全局平均池化,也就是到Excitation操作时,首先利用一个 Fully Connected (全连接层)将特征维度降低到输入的 1/r,然后经过 ReLu 激活后再通过一个全连接层升回到原来的维度。然后再通过利用Sigmoid 函数进行归一化,得到每个通道的权重。使用两个全连接层的意义是限制模型复杂度,增加泛化。
引用论文中的公式表示如下
s
=
F
e
x
(
z
,
W
)
=
σ
(
g
(
z
,
W
)
)
=
σ
(
W
2
δ
(
W
1
z
)
)
s=F_{ex}(z,W)=\sigma(g(z,W))=\sigma(W_2\delta(W_1z))
s=Fex(z,W)=σ(g(z,W))=σ(W2δ(W1z))
其中降维层参数为W1,升维层参数是W2。
简单来说,可以把Excitation操作后输出的权重看作是每个通道的重要性。接下来再把这一输出与原先的特征图相乘, 也就是上图中Scale 的操作,可以使选择出来的相对“重要”的特征通道数值更高,不相关的数值更小。可以表示为下面这张图

引用论文中的公式表示如下
X
~
=
F
s
c
a
l
e
(
U
c
,
s
c
)
=
s
c
U
c
\tilde{X}=F_{scale}(U_c,s_c)=s_cU_c
X~=Fscale(Uc,sc)=scUc
以上就是Squeeze-and-Excitation模块的作用与原理。以下是该模块在Inception网络和ResNet网络中的应用

以上是本次学习的内容,其他还有MobileNet网络,也是用到了depthwise separable convolution模块,在此就不多说了。还有EfficientNet网络也是值得学习的,但临近开学就先到此为止吧,后面有空再好好研究研究。














 577
577











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









