







Exploiting Spatial Structure for Localizing Manipulated Image Regions
ICCV 2018
篡改边缘特征

部分的篡改图像,根本就不符合逻辑,不符合图像的基本语义信息。
剩下的大部分的图像篡改,通过放大图像就可以被人眼识别出来。
这是篡改水平决定的。
一般而言,为了边缘的平滑过度,不被人眼识别出怪异,一般在图像篡改后进行边缘的平滑。
因此,放大边缘,一般有锯齿的是真实图像,而很明显的没有锯齿痕迹的往往是篡改图像。欲盖弥彰。
网络结构图

- 第一步:从原图取patch 64 * 64 * 3
- 第2步: 对每个batch卷积
- 第3步 :对特征层 选1层 64 * 64 * 1 分为小block,8 * 8 依次输入到LSTM(这一步描述的不是很清楚,需要看代码理解)
Loss
对于batch的LOSS
针对的预测是Patch labels ,像是交叉熵loss
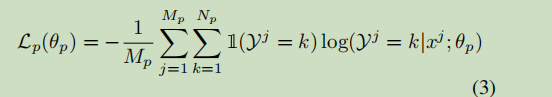
对于单像素的Loss
就是交叉熵loss
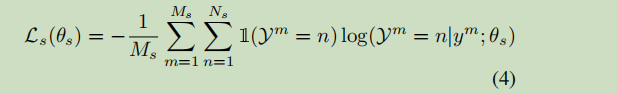
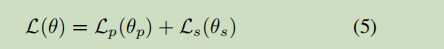
最终计算的loss为二者简单相加
结果

那个CRF RNN 是语义分割模型的结果,不知道作者说半天语义分割是想要表达什么。
由于算法加入了块的预测,并由块的分类结果影响了像素的预测结果,所以会在其中由一些明显的割裂感,是这个小块被预测为正确块的影响,导致了整个小块全部被更改为正确。
由大而小,分而治之的思想。这种做法理论上还是很有道理的,不知道实际做出来效果怎么样,这篇算法没有测试过。
下面的链接感觉是这篇算法的代码。
















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









