







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
@图像篡改入门02 利用空间结构篡改定位
图像篡改被动取证 利用图像空间结构进行篡改定位
使用一个CNN-LSTM的网络模型捕获篡改边界特征
J. H. Bappy, A. K. Roy-Chowdhury, J. Bunk, L. Nataraj and B. S. Manjunath, “Exploiting Spatial Structure for Localizing Manipulated Image Regions,” 2017 IEEE International Conference on Computer Vision (ICCV), 2017, pp. 4980-4989, doi: 10.1109/ICCV.2017.532.
主要贡献
高科技日志工具的出现促进的对图像的处理操作,也促进了对图像篡改的检测方法。在图像篡改中,篡改区域的定位是一个重点问题。该文通过一个CNN-LSTM的混合网络来捕获篡改区域和未篡改区域的特征,从而进行篡改区域的定位以及检测。对网络使用端到端训练,在给定篡改区域掩码的条件下,通过BP学习参数。最后在三个不同数据集==(NIST、Forensic、Coverage)==上实验,实现对篡改图像空间块和像素级别的分类。
相关工作
- 检测数字图像重采样:有学者通过变换后图像二阶导数插值的周期性检测图像。为了检测JEPG压缩图像的重采样,作者在检测之前就添加了噪声,并且说明噪声有助于重采样。也有由归一化的能量密度导出特征然后SVM对图像检测。
- 为了检测复制移动篡改,可以使用距离度量来确定块。将块划分为多个语义独立的patch,然后在patch之间进行关键点匹配。
- 利用视觉伪影的图像拼接检测技术:有学者提出一种基于SPT和LBP的图像篡改检测方法,讨论了图像中缺失或者受损区域的恢复过程。
简要介绍
- 当前大多数的方法都集中在检测图像是否被处理上,关于图像篡改定位的方法比较少,已经存在对图像块进行分类来解决图像篡改方法。本文提出的框架不仅可以从图像块的级别还可以从像素级别进行定位操作。
- 图像取证的方法中大多数利用图像的频域特性或统计特性。如DWT、SVD、PCA、DCT。近年来深度学习在目标检测、场景分类、语义分割中都有良好的性能。经过良好处理的图像不会出现改变的视觉效果,与真实图像极其相似,这种情况下CNN检测的效果不佳。
框架概述
图像处理当中复制粘贴和移除拼接类型是非常常见的并且难以判别。但是研究发现经过篡改的区域边界性比较与未篡改的区域边界更为平滑。

- 给定图像,通过滑动窗口提取图像块;输入框架后生成一个块标签和像素级别的分类掩码输出。
- 整体框架由5个卷积层和3个堆叠的LTSM结构组成,前面的2层卷积层负责学习底层特征,如边缘和纹理,之后输出一个二维特征图,分成88块,输入到LTSM网络中。LTSM网络用来建模相邻像素之间的空间关系,因为篡改会破坏该区域的自然统计数据(natural statistics)。88块按序分给3个LTSM堆叠网络,产生块之间的联系特征。最后通过softmax分类器对块进行分类,并传递给后面的3层卷积层。
- 在LTSM网络后面使用3个卷积层来获得每个像素的置信度得分的2D图。通过篡改区域的掩码标签进行端到端训练每个像素,通过计算在patch分类层和像素分割层的联合损失,通过BP最小化损失。
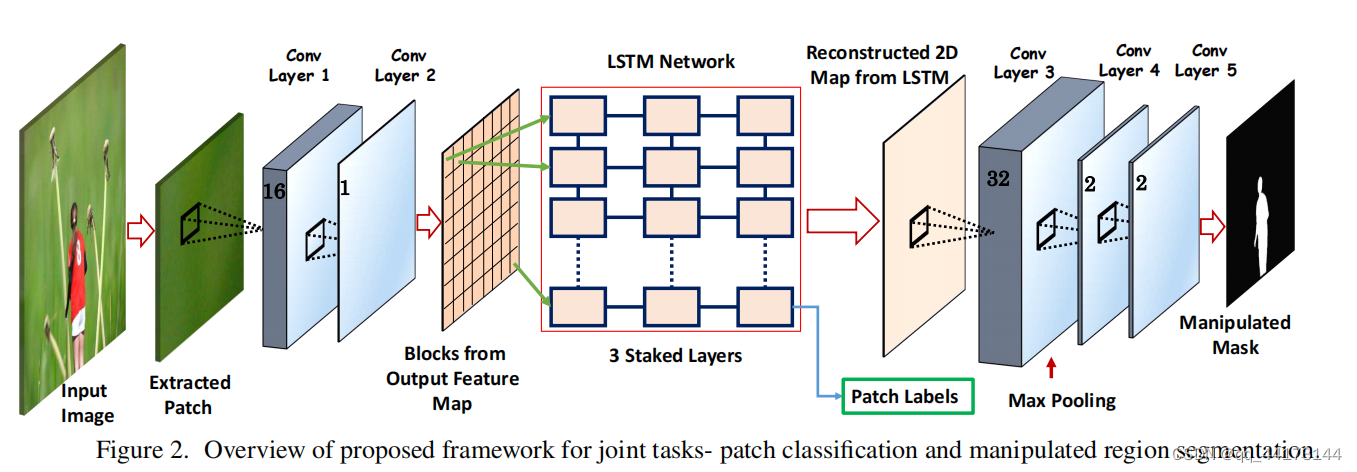
卷积层
- 输入:patch;有RGB值;尺寸64643;卷积核55D(D表示卷深度,不同层D值不同);激活函数:RELU
- 第一层卷积输出16个特征映射,在第二层进行组合;第二层输出二维特征图分成8块进入LTSM网络。记Fc2.
- 只在第三层卷积层最大池化,目的是防止信息丢失。
- 最后使用两层完全卷积层进行像素分类,并且不进行上采样操作防止失真,最后得到64*64的2D置信度图。
LTSM网络
- LTSM网络用来建模相邻像素之间的空间关系,因为篡改会破坏该区域的自然统计数据(natural statistics)。88块按序分给3个LTSM堆叠网络,产生块之间的联系特征。每层64个单元,最后一层每个LTSM提供256维度的向量转换成1616的块,连接所有块形成2d特征图。最后通过softmax分类器对块进行分类,并传递给后面的3层卷积层。
网络训练
- 网络中一共两个sotfmax层分别进行块和像素级别的分类任务。
- 损失函数
- 对patch的分类使用交叉熵损失,
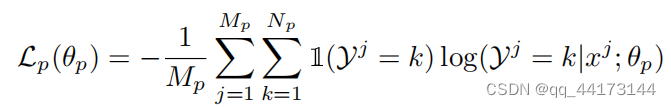
- 对像素分割的交叉熵损失
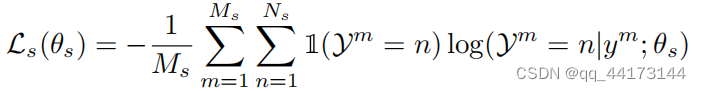
- 联合损失(通过Adam最小化损失)
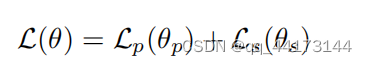
- 对patch的分类使用交叉熵损失,
实验过程
分别在NIST、IEEE Forensics Challenge 、COVERAGE数据集上进行实验。实验过程中,数据集随机划分为训练集(65%)、测试集(25%)、验证集(10%)。为了增强篡改patch,首先会在篡改区域掩膜上使用轮廓逼近获得边界框,以其为中心扩大。使得LTSM能够学习边界差异。通过真实篡改掩膜和预测区域的交集比率IoU,以12.5%为阈值,含有超过该比率的篡改像素则认为该图像块为篡改块。
特殊机制
通过提前预测的patch标签可以减少最后像素分割的假正元素,因为在一个高置信度的未篡改图像块中,很少有元素是假正的,所以可以从结果中移除他们。
实验环境
Tensorflow、 两个NVDIA Tesla K80
实验中的对比网络以及对比内容
S表示像素分割
P表示patch分类

联合学习
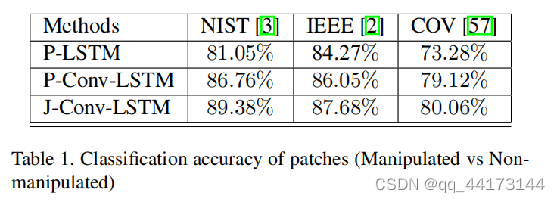
不同层次和不同大小特征图
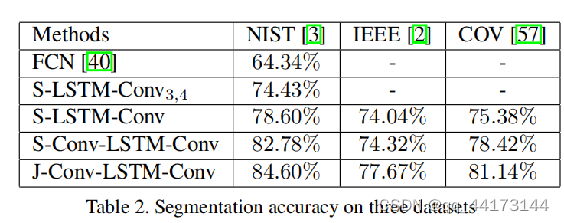
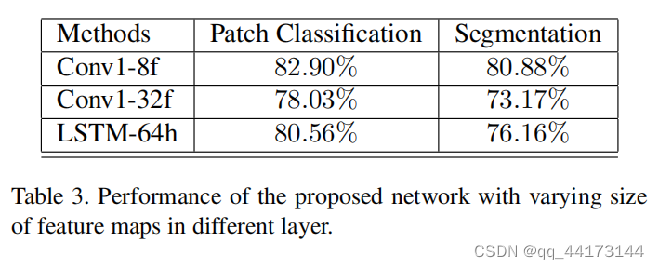
通过减少卷积层的映射数量,得到更好的效果,这是因为通过操作(复制、移除)的图像不会留下视觉线索。
不同IoU阈值的影响
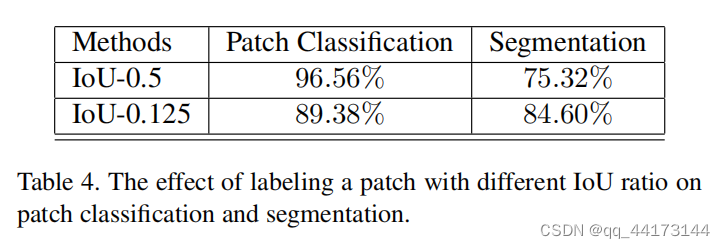
尽管较高的IoU可以提高patch的检测正确率,但是会降低像素分割任务的准确率。上表是网络模型在NIST数据集的结果。
ROC曲线和定性分析
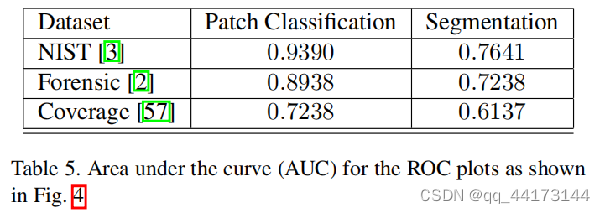

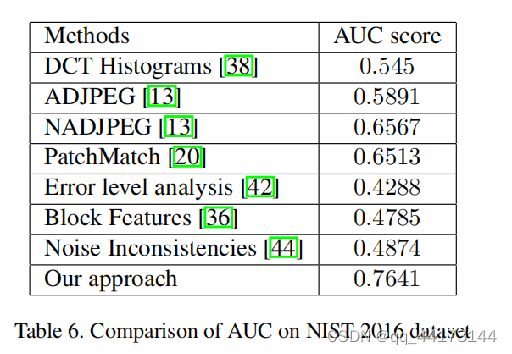
实验效果展示
















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









