






 本文介绍了如何使用爬虫技术抓取携程网的景点数据,经过数据清洗后,通过散点图展示5A景点分布,分析了景点的热评分和评论分数排名,还探讨了价格与热评分的关系,并制作了免费景点和标签词云图。
本文介绍了如何使用爬虫技术抓取携程网的景点数据,经过数据清洗后,通过散点图展示5A景点分布,分析了景点的热评分和评论分数排名,还探讨了价格与热评分的关系,并制作了免费景点和标签词云图。
1.前言
在之前的一篇文章中,我们利用爬虫技术从携程网上获取了大量的景点数据,包括景点名称、地点、评分、评论数、标签等信息。这些数据为我们后续的分析提供了基础。旅游已经成为人们生活中不可或缺的一部分。作为中国最大的在线旅游服务提供商之一,携程网汇集了大量的旅游信息,包括各地景点的介绍、评价等。本文通过对携程景点数据的爬取和可视化,旨在发现中国旅游热门目的地。
2.0数据清洗与可视化
2.1 pandas 读取csv数据
df = pd.read_csv('csv/全国各景点全.csv')2.2 景点分布散点图
2.2.1 数据处理
# 删除经纬度为空的行data = df.dropna(subset=['坐标'])# 将坐标解析为经纬度data['纬度'] = data['坐标'].apply(lambda x: x.split(',')[0][1:])data['经度'] = data['坐标'].apply(lambda x: x.split(',')[1][:-1])# 选择5A景点的数据data_5a = data[data['是否5A'] == '5A']# 转换为数值类型data_5a['纬度'] = pd.to_numeric(data_5a['纬度'])data_5a['经度'] = pd.to_numeric(data_5a['经度'])
2.2.2 图形绘制
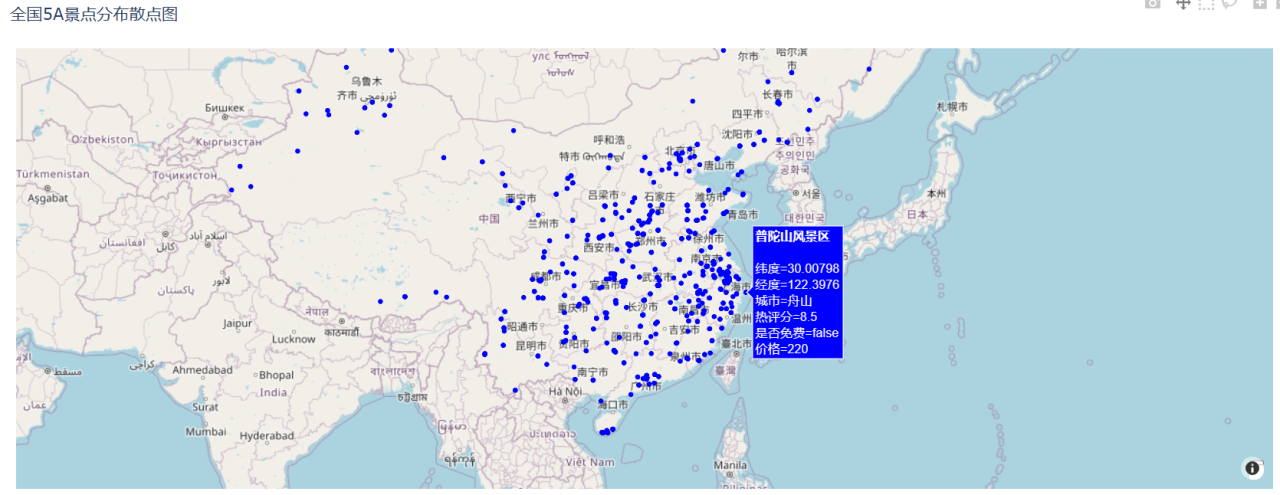
# 绘制散点地图fig = px.scatter_mapbox(data_5a,lat="纬度",lon="经度",hover_name="景点名",hover_data=["城市", "热评分", "是否免费", "价格"],color_discrete_sequence=["blue"],zoom=3, height=600)fig.update_layout(mapbox_style="open-street-map")fig.update_layout(title='全国5A景点分布散点图')fig.show()
2.2.3 可视化结果
2.3 全国5A评论分与热评分排序前十景点
2.3.1 数据处理
# 根据景点名分组,并计算平均热评分和评论分grouped_data = data_5a.groupby('景点名').agg({'热评分':'mean', '评论分':'mean'}).reset_index()# 按照热评分排序并取前十top10_hot_score = grouped_data.sort_values(by='热评分', ascending=False).head(10)# 按照评论分排序并取前十top10_comment_score = grouped_data.sort_values(by='评论分', ascending=False).head(10)
2.3.1 图形绘制
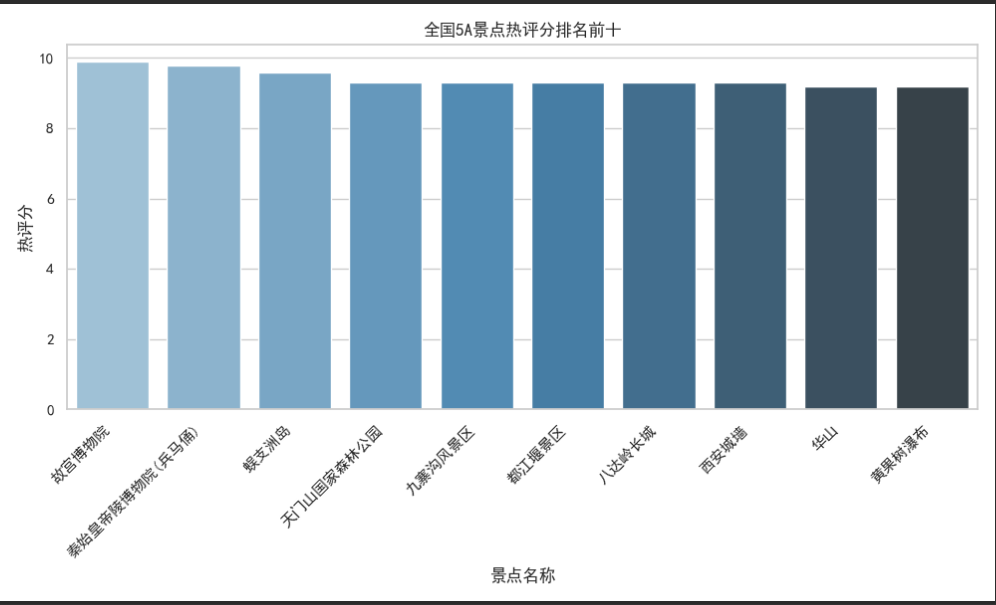
# 设置绘图风格sns.set(style="whitegrid")plt.rcParams['font.sans-serif'] = ['SimHei']# 绘制热评分排名前十的柱状图plt.figure(figsize=(10, 6))sns.barplot(x='景点名', y='热评分', data=top10_hot_score, legend=False,palette="Blues_d")plt.title('全国5A景点热评分排名前十')plt.xlabel('景点名称')plt.ylabel('热评分')plt.xticks(rotation=45, ha='right')plt.tight_layout()plt.show()
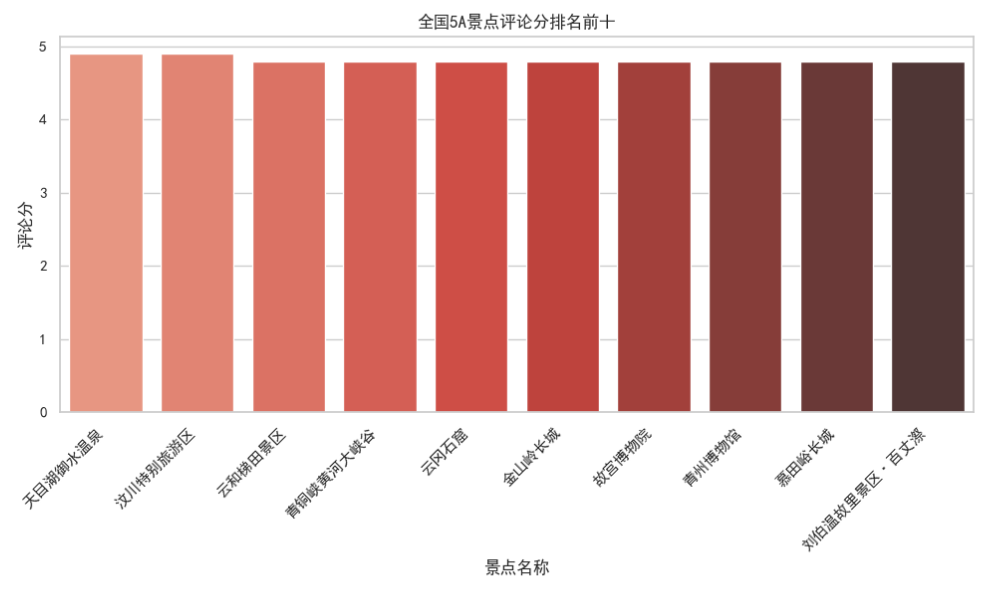
# 绘制评论分排名前十的柱状图plt.figure(figsize=(10, 6))sns.barplot(x='景点名', y='评论分', data=top10_comment_score,legend=False, palette="Reds_d")plt.title('全国5A景点评论分排名前十')plt.xlabel('景点名称')plt.ylabel('评论分')plt.xticks(rotation=45, ha='right')plt.tight_layout()plt.show()
2.3.1 可视化结果
2.4 价格与热评分的关联
2.4.1 数据处理
# 将价格为空的值填充为0df['价格'].fillna(0, inplace=True)
2.4.2 图形绘制
# 绘制价格和热评分的关系图plt.figure(figsize=(10, 6))# sns.scatterplot(x='热评分', y='价格', data=data)sns.lmplot(x='热评分', y='价格', data=df)plt.title('热评分和价格的关系')plt.xlabel('热评分')plt.ylabel('价格')plt.tight_layout()plt.show()
2.4.3 可视化结果
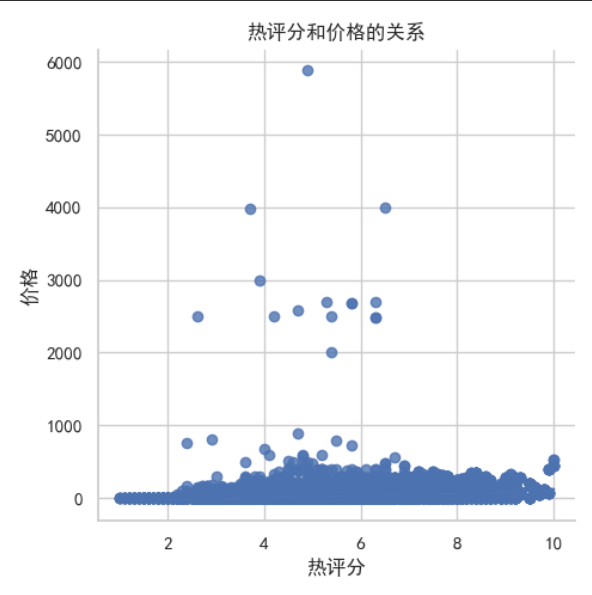
2.5 全国免费景点top10
2.5.1 数据处理
# 选择免费景点的数据free_spots = df[df['是否免费'] == True]#将热评分为空的值填充为0,以便排序free_spots['热评分'].fillna(0, inplace=True)grouped_data = free_spots.groupby('景点名').agg({'热评分':'mean'}).reset_index()# 按照热评分进行排序,并取前十条数据top10_free_spots = grouped_data.sort_values(by='热评分', ascending=False).head(10)
2.5.2 图形绘制
# 绘制柱状图plt.figure(figsize=(10, 6))sns.barplot(x='景点名', y='热评分', data=top10_free_spots, palette="Blues_d")plt.title('免费景点热评分排名前十')plt.xlabel('景点名称')plt.ylabel('热评分')plt.xticks(rotation=45, ha='right')plt.tight_layout()plt.show()
2.5.2 可视化结果
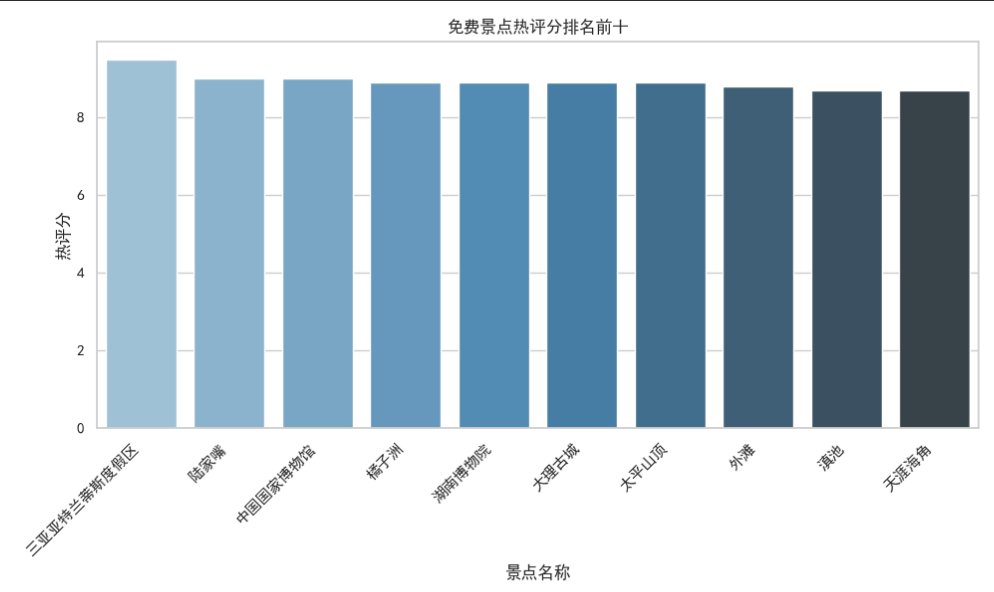
2.6 旅游标签词云图
2.6.1 数据处理
stopwords = {'的', '是', '这', '那', '我们', '你们', '他们', '她们', '它们','[',']'}# 删除经纬度为空的行data = df.dropna(subset=['标签'])# 将标签数据转换为列表类型tags = data['标签'].apply(ast.literal_eval)# 提取标签数据tags_flat = [tag for sublist in tags for tag in sublist]# 统计标签出现的次数tags_count = Counter(tags_flat)# 过滤停用词和单个字tags_count = {word: count for word, count in tags_count.items() if word not in stopwords and len(word) > 1}
2.6.2 图形绘制
font_path = 'C:/Windows/Fonts/msyh.ttc' # 指定中文字体路径# 生成词云图wordcloud = WordCloud(font_path=font_path,width=800, height=400, background_color='white').generate_from_frequencies(tags_count)# 绘制词云图plt.figure(figsize=(10, 6))plt.imshow(wordcloud, interpolation='bilinear')plt.title('景点标签词云图')plt.axis('off')plt.show()
2.6.3 可视化结果



















 3193
3193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











