






在了解大语言模型训练优化秘籍之前,我们先来了解一下大语言模型训练面临的挑战,以此进行针对性的训练优化。
大语言模型训练面临的挑战
随着模型参数量规模的增大,资源和效率逐渐成为制约模型训练的因素。
按照摩尔定律的预测,芯片的集成度每 18 ∼ 24 个月便会增加 1 倍,这意味着单位计算性能大约每两年翻1倍。
模型参数量不超过 10 亿个时,对资源的需求未触达单机硬件的极限。
随着大语言模型技术的进步,模型的参数量每年增长 10 倍,很快透支了处理器的富余算力。
另外,处理器的存储资源并未遵循摩尔定律的增长规律,其集成度仅呈线性增长趋势。
因此,大语言模型天然地对训练工程提出了多机分布式要求。
要实现大语言模型的分布式训练,首先要关注的问题是怎么切分数据。
在传统的分布式系统设计中,根据数据是否有冗余,存在副本与分片两种基本模式。
在大语言模型的训练中,模型参数和训练样本都是要被切分的对象。
根据数据冗余情况、切分内容、切分方法等划分标准,训练工程提出了数据并行、模型并行、流水线并行、张量并行等不同的分布式技术。
这些分布式技术,或提高模型训练的参数规模,或提高训练过程中计算资源的利用效率,最终达到加速训练的目的。
在解决了基本的模型与数据切分后,大语言模型的预训练和微调仍无法在几个小时内完成。
训练大语言模型需要投入巨大的资源。
以 LLaMA2 模型为例,训练参数量规模为 70B 的模型需要投入累计 170 万卡时,相当于 1,000 张卡训练 70 天。
大量的资源投入会引起边际效用的下降,因此,提高资源投入的边际效用也是训练工程关注的重要课题,常见做法是尽量消除系统中各级传输的瓶颈。
在长时间的大规模训练中,软件或硬件故障不可避免,集群故障的及时发现和恢复速度对训练效率有很大的影响。
此外,监控与容灾也是大语言模型训练工程需要特别关注的技术。
大语言模型训练优化秘籍
分布式训练技术解决了大语言模型训练面临的两个最主要的问题—— 模型参数量大和训练数据量大。
如果要保障端到端训练的吞吐量,就还有需要优化的问题,如I/O 优化、通信优化和稳定性优化。
I/O 优化
大语言模型训练场景下的 I/O 优化有一些常规方法,如增加进程数量以提升数据并发处理效率,通过数据预获取(Prefetch)降低等待时延,优化内存(如 Pin Memory)以提升复制效率,等等。
这些方法在深度学习框架中通常都有内置的支持,也可以通过配置进行完善。
还有一些需要关注的 I/O 问题,如训练数据量比较大,通常有几 TB∼几百 TB,这对存储的要求比较高,既需要大存储容量,又需要高吞吐性能。
需要高吞吐性能的原因是大语言模型需要多节点并行训练,并且每个节点都需要频繁访问存储、加载训练数据,节点越多,对吞吐性能的要求就越高。
除此之外,需要具备足够的容错能力。这对于现有的存储系统是比较大的挑战。具体的优化方案有以下两种。
优化方案一:高可用的大容量存储服务+本地缓存。这种方案适用于训练数据量为 TB 级别的情况,本地缓存(当前磁盘容量通常都是 TB 规格)可以完全满足存储需求。训练数据对于模型性能的重要性不言而喻,因此,高可用(容错能力)的大容量存储是必要条件。本地缓存可以很好地满足数据的高吞吐需求。训练开始前,要先通过数据预热将训练数据同步至各个计算节点的本地缓存。由于一次模型训练过程通常包含多轮,因此,初始数据预热占用的同步时间在整个训练过程中的占比很低,而且本地缓存不受节点数量增加的影响,可以保证每个节点具有同等的吞吐性能。本地缓存数据加速过程如图所示,该过程包括数据预热和加载数据两个关键步骤。
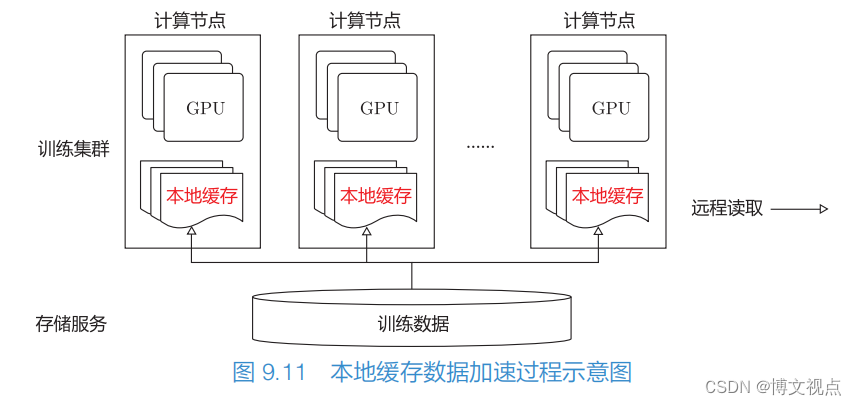
(1)数据预热:大容量存储服务,将训练数据分发至所有计算节点的本地缓存。
(2)加载数据:计算节点从本地缓存读取训练数据,无须访问远程大容量存储。
数据预热时需要将一份数据快速分发到多个计算节点。传统的做法是:设置一定的并发量,每个计算节点分别从远程中心存储加载数据。这种方式的中心存储很容易成为瓶颈,效率不高。可优化为采用 P2P 链式分发,即部分节点先从中心存储获取数据副本,当这些节点得到完整副本后也变成数据服务,并向其他节点分发数据。这样做效率更高,性能可提升数倍。
优化方案二:高可用的大容量存储服务+高性能的分布式缓存。前者需满足容量和容错能力的需求,后者解决本地缓存容量过小的问题,同时满足高吞吐性能。该方案适用于训练数据量为几十TB∼几百TB 的场景,若本地缓存容量过小,在这类场景中将无法存放完整的训练数据。因为训练数据的使用规律是每轮只使用 1 次,且每轮都对数据进行随机打乱(Shuffle),所以本地缓存的数据难以被复用。如图 9.12 所示,分布式缓存利用训练节点的本地缓存组成一个大的分布式缓存服务,解决本地缓存容量过小的问题,并通过以下两点满足对吞吐量的要求。
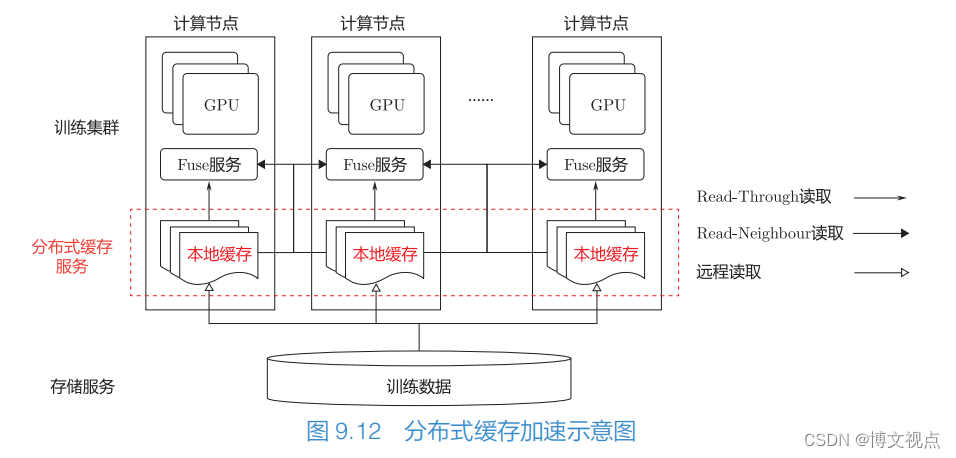
(1)Read-Through 读取:在读取数据时优先从本地缓存中读取,速度最快。
(2)Read-Neighbour 读取:如果在本地缓存中检索不到数据,则从邻居节点中读取,其速度优于直接从远程读取。
通信优化
大语言模型训练通常需要多机、多节点并行计算,合理的通信优化能有效地提升训练吞吐量。
不同的分布式并行技术对通信带宽的要求不同,因此,针对不同的硬件环境,需要选择最适合的分布式并行方案,并针对不同的数据量和模型特点做针对性的优化,从而达到最好的通信效率。
图 9.13 为 NVIDIA CPU 多机、多节点的链接拓扑,单机内的节点通过NVIDIA 专有高速链接(NVLink,带宽为 300Gbps 以上)通信,多机之间通过以太网(带宽为 100Gbps∼200Gbps)或者 RDMA 网络 (带宽为 800Gbps 以上) 通信。
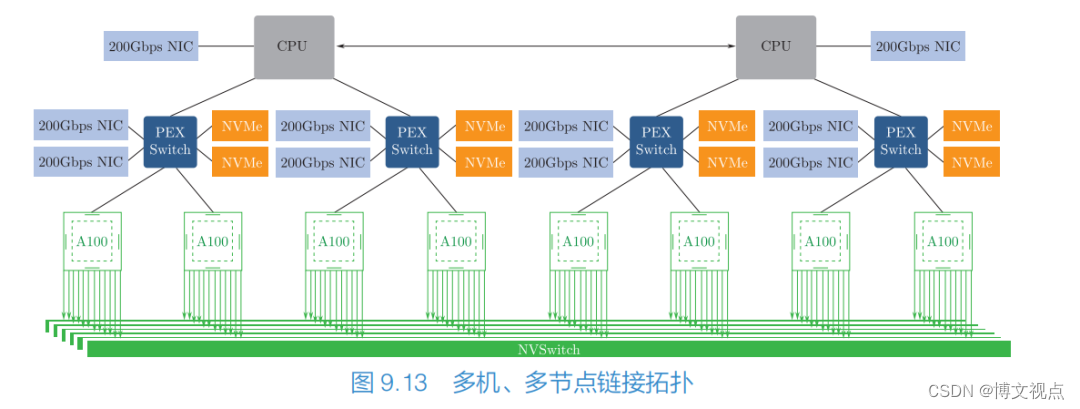
首先,需要根据网络条件选择使用哪种并行方案。
如果网络是普通的以太网,则多机之间的带宽容易成为通信的瓶颈。首选方案是混合并行(或三维并行)。将需要高通信量的数据并行和张量并行安排在单机内,这样可以充分利用单机内的高速通信(如 NVLink)。
然后,多机之间采用流水线并行,这样多机之间只需要同步中间结果,通信量远小于模型权重参数。
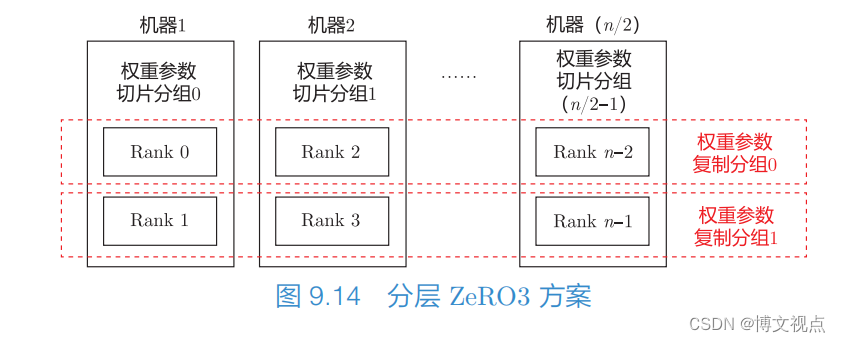
次选方案是分层 ZeRO3 方案。相比于原生 ZeRO3 方案,前者可以降低网络通信瓶颈的影响。
如图 9.14 所示,该方案利用单机内的高速通信,只在单机内切分权重参数,可有效降低权重参数同步的时延。
由于多机之间需要进行梯度同步,因此能明显观察到通信时延的影响。虽然混合并行方案比流水线并行方案的性能好,但是需要深入适配模型代码,实现难度较高。
虽然流水线并行方案的性能不如混合并行方案,但是更容易实现,且性能优于原生 ZeRO3 方案。
混合并行方案和流水线并行方案的扩展性都受限于单机的计算能力,模型参数量的规模不能随着机器数量的增加而扩展。
RDMA 网络是大语言模型训练比较理想的网络条件。与以太网相比,RDMA 网络的吞吐量增加了 4 ∼ 8 倍,时延减少了 90%(从 50µs 降至 5µs)。
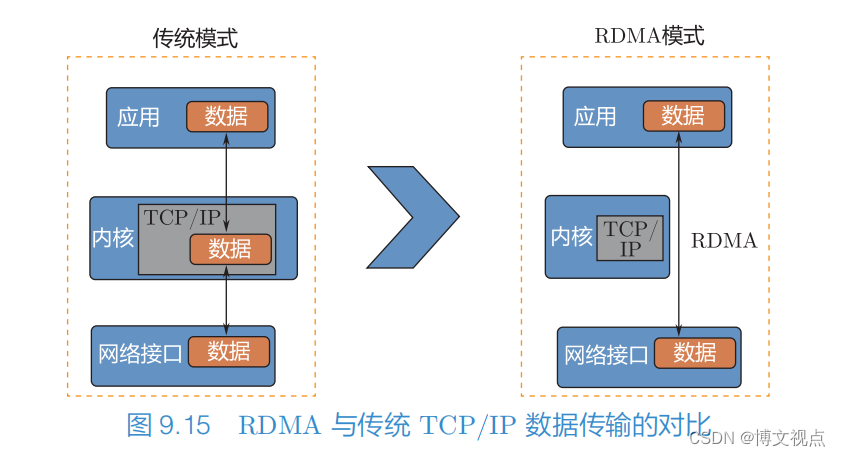
如图 9.15 所示,相比传统 TCP/IP 通信,RDMA 通信可以跳过内核操作,将数据从用户态直接发送到网络,实现低时延、高吞吐。选择分布式并行方案时,网络通信不会成为限制因素。
首选方案是采用 ZeRO3 算法,此方案容易实现,模型参数量可随机器数量的增加而增加。
备选方案是混合并行,根据网络拓扑和模型网络结构适配设计张量并行、流水线并行和数据并行的数量。此方案可达到更高的吞吐量,但实现难度较大。
RDMA 网络的缺点是不够成熟,维护配置难度较大,稳定性不如以太网,因此在使用RDMA 网络时,需要从软件层面做一些配置优化。常见优化如下。
(1)网络“参数面”调优:这关系到 RDMA 网络的性能和稳定性,需要专业网络工程师的支持。出于对成本的考虑,RDMA 网络一般会选择 RoCE 方案实现,即 Infiniband 网卡+ 以太网交换机(不是 Infiniband 专用交换机)。要充分发挥 RDMA 网络的性能,需要建立不丢包的无损网络环境。而对于 RoCE 方案,PFC(Priority-based Flow Control,基于优先级的流量控制)可以解决网络拥塞,实现不丢包的无损网络。
(2)开启 GDRDMA,即允许数据在网卡和显存之间直接读写,无须经过内存复制,效率更高。通常可提升 20% ∼ 30% 的吞吐量。
(3)NCCL 调优:由于主要的硬件加速设备是 NVIDIA 显卡,所以 NCCL 是目前多机通信效率最高的选择。NCCL 包含大量可用于优化通信效率和稳定性的配置,如提升 Infiniband通信中断容忍度的 NCCL_IB_TIMEOUT 和 NCCL_IB_RETRY_CNT 等;便于优化 NCCL通信的调试日志,即 NCCL_DEBUG 和 NCCL_DEBUG_SUBSYS 等。
稳定性优化
由于模型参数量和训练数据量都比较大,因此大语言模型的训练周期较长,少则几天,多则一两个月。
训练过程包含大量的计算节点、网络设备,任何一个环节出现问题都会使训练无法正常完成。保障训练稳定进行,或者降低故障次数和 MTTR(Mean Time To Repair)非常重要。常见的故障包括计算节点单机故障(如 CPU、内存、磁盘、GPU 等出现故障)、网络中断(如网卡故障、网线脱落、交换机故障等),以及软件故障(如磁盘满、代码错误、集群维护性故障等)。可以通过以下方式规避故障问题。
(1)问题排查及预防:定期进行健康检测,提前发现问题,有针对性地进行改善。
单机层面:进行容量监控,设备及系统健康检测,及时发现并处理问题。
网络层面:流量监控和控制,避免无效流量对训练网络的影响,通过节点探访,及时发现并解决风险点。
软件代码层面:小规模数据量的 Demo 测试,保障所有代码路径有效测试(数据加载、前向及反向传播、模型文件保存等)。
(2)故障及时发现:包括两个方面,一是及时发现训练中断或训练异常卡住的情况;二是模型性能不收敛。前者通过监控一些指标就能发现,如所有节点的 CPU 利用率、日志更新的时间间隔等。后者需要监控模型的学习曲线(如 Loss 曲线),与正常情况比对。另外,大语言模型的性能不能完全由 Loss 曲线反映,需要定期对模型做评测,如有问题及时终止、及时调整(如超参配置等),重新开始训练。
(3)快速恢复:对于不同故障要做预案,当故障发生时,采取有效手段,快速恢复训练,降低故障的影响时长。如果机器故障率比较高,那么可以适当地配置一些资源用于替换。恢复训练需要的条件,包括代码、数据和模型权重参数保存文件。前两个条件是相对静态的,可以提前做好准备,比较容易实现。由于大语言模型的参数量通常比较大,因此模型的检查点文件通常达到 TB 级,需要选择合理的保存周期。周期太短,保存耗时累计会太高,而且需要占用大量的存储空间;周期太长,不利于故障后的恢复(例如若在保存周期的最后一步发生故障,将浪费整个训练周期)。保存周期需要根据具体情况(存储容量、存储性能和故障率)而定,通常以 2 小时左右为佳。
本文节选自2024年3月的新书《大语言模型:原理与工程实践》一书,
市场上缺乏大语言模型在实际应用方面的资料。
现有的资料多聚焦于理论研究,而具体的实践方法多被保密,难以获得实际操作的指导。
为了填补这一空白,轩辕大模型实践者杨青团队历经一年的实践和探索,决定分享他们的经验和成果,旨在为大语言模型的初学者和实践者提供快速入门和应用的途径。
作为真正的大语言模型实践者,他们拥有十亿、百亿、千亿等不同参数规模大语言模型的训练经验。
在本书中,这些经验都被毫无保留地融入其中,确保本书内容的实用性和深度,并且提供了代码资源,GitHub 社区(https:// github.com/Duxiaoman-DI/XuanYuan),用于持续更新作者团队的技术成果和见解。
本书一经上市便位居京东新书热卖榜日榜TOP 1 !

















 4573
4573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









