







在之前我们采取了两个主要的措施分别取隐藏和减少latency:
1 . 我们一方面通过大量线程并行的方法去不断读取内存(当一个 thread 读取内存,开始等待结果的时候,GPU 就可以立刻切换到下一个 thread,并读取下一个内存位置)来尽可能的隐藏latency。
2 . 另一方面我们采取了连续的内存存取模式,尽量减少latency,关于所谓的连续存储我们再详细说明一下:
其实更精确的说,global memory 的存取,需要是 “coalesced“。
所谓的 coalesced,是表示除了连续之外,而且它开始的地址,必须是每个 thread 所存取的大小的 16 倍。例如,如果每个thread 都读取 32 bits 的数据,那么第一个 thread 读取的地址,必须是 16*4 = 64 bytes 的倍数。
关于”coalesced“的满足与否,我们还需要考虑下面两种情况:
1 . 如果有一部份的 thread 没有读取内存,并不会影响到其它的 thread 执行 coalesced 的存取:
例如:
if(tid != 3)
{
int number = data[tid];
}虽然 thread 3 并没有读取数据,但是由于其它的 thread 仍符合 coalesced 的条件(假设 data 的地址是 64 bytes 的倍数),这样的内存读取仍会符合 coalesced 的条件。
2 .每个 thread 一次读取的内存数据量,可以是 32 bits、64 bits、或 128 bits。不过,32 bits 的效率是最好的。64 bits 的效率会稍差,而一次读取 128 bits 的效率则比一次读取 32 bits 要显著来得低(但仍比 non-coalesced 的存取要好)。
如果每个 thread 一次存取的数据并不是 32 bits、64 bits、或 128 bits,那就无法符合 coalesced 的条件.
例如,以下的程序:
struct vec3d { float x, y, z; };
...
__global__ void func(struct vec3d* data, float* output)
{
output[tid] = data[tid].x * data[tid].x + data[tid].y * data[tid].y + data[tid].z * data[tid].z;
}这个程序并不是 coalesced 的读取,因为 vec3d 的大小是 12 bytes,而非 4 bytes、8 bytes、或 16 bytes。
要解决这个问题,可以使用 __align(n)__,例如:
struct __align__(16) vec3d { float x, y, z; };这会让 compiler 在 vec3d 后面加上一个空的 4 bytes,以补齐 16 bytes。
另一个方法,是把数据结构转换成三个连续float的数组,例如:
__global__ void func(float* x, float* y, float* z, float* output)
{
output[tid] = x[tid] * x[tid] + y[tid] * y[tid] + z[tid] * z[tid];
}如果因为其它原因使数据结构无法这样调整,也可以考虑利用 shared memory 在 GPU 上做结构的调整。
例如:
__global__ void func(struct vec3d* data, float* output)
{
__shared__ float temp[THREAD_NUM * 3];
const float* fdata = (float*) data;
temp[tid] = fdata[tid];
temp[tid + THREAD_NUM] = fdata[tid + THREAD_NUM];
temp[tid + THREAD_NUM*2] = fdata[tid + THREAD_NUM*2];
//同步
__syncthreads();
output[tid] = temp[tid*3] * temp[tid*3] + temp[tid*3+1] * temp[tid*3+1] + temp[tid*3+2] * temp[tid*3+2];
}在上面的例子中,我们先用连续的方式,把数据从 global memory 读到 shared memory。由于shared memory 不需要担心存取顺序(但要注意 bank conflict 问题,后面马上会讲到),所以可以避开 non-coalesced 读取的问题。
http://blog.csdn.net/sunmc1204953974/article/details/51078818
传输延迟(latency)
在host端和device端之间存在latency,数据通过PCI-E总线从CPU传输给GPU,我们必须避免
频繁的host、device间数据传输,即使是最新的PCIE 3.0 x16接口,其双向带宽也只有32GB/s
在device内部也存在latency,即数据从gpu的存储器到multi-processor(SM)的传输。

访问一次全局内存,将耗费400~600个cycle,成本是非常高的,所以必须谨慎对待全局内存的访问
合并(coalesced)
数据从全局内存到SM(stream-multiprocessor)的传输,会进行cache,如果cache命中了,下一次的访问的耗时将大大减少。
每个SM都具有单独的L1 cache,所有的SM共用一个L2 cache。
在计算能力2.x之前的设备,全局内存的访问会在L1\L2 cache上缓存;在计算能力3.x以上的设备,全局内存的访问只在L2 cache上缓存。
对于L1 cache,每次按照128字节进行缓存;对于L2 cache,每次按照32字节进行缓存。
参考:《CUDA_C_Programming_Guide-V8.0》 Appendix G. COMPUTE CAPABILITIES
合并访问是指所有线程访问连续的对齐的内存块,对于L1 cache,内存块大小支持32字节、64字节以及128字节,分别表示线程束中每个线程以一个字节(1*32=32)、16位(2*32=64)、32位(4*32=128)为单位读取数据。前提是,访问必须连续,并且访问的地址是以32字节对齐。(类似于SSE\AVX的向量指令,cuda中的合并访存也是向量指令)
例子,假设每个thread读取一个float变量,那么一个warp(32个thread)将会执行32*4=128字节的合并访存指令,通过一次访存操作完成所有thread的读取请求。
对于L2 cache,合并访存的字节减少为32字节,那么L2 cache相对L1 cache的好处?
在非对齐访问、分散访问(非连续访问)的情况下,提高吞吐量(cache的带宽利用率)
非对齐访问(unaligned)


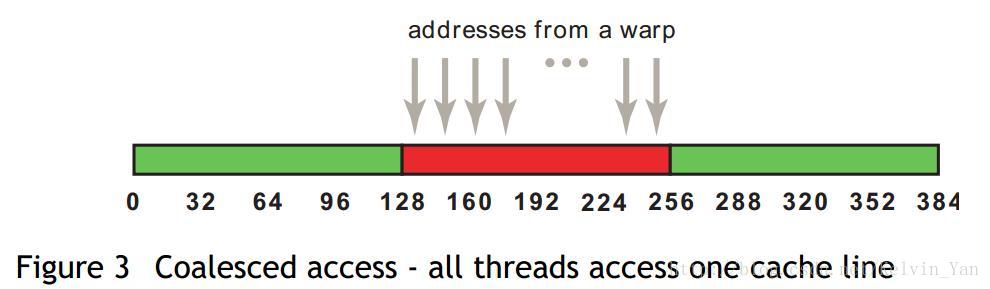
以上是L1、L2 cache的非对齐访问的对比,128字节的数据没有进行内存对齐,首地址位于96~128之间,
L1为了访问128之前的数据,必须访问从0~127的整段内存,其cache的有效利用率是128/256=50%,L2则只需要访问96~127的内存,其cache的有效利用率是128/160=80%
分散访问(scattered)
warp请求访问位于不同地址的数据,数据是非连续的,此时warp无法进行合并访问,每个thread访问一个float,一共需要执行32次访存指令。下面观察L1 和 L2 的区别

L1 cache,访存请求分布在0~383的内存之间,cache的有效利用率是128/384=33%

L2 cache,相比L1在scatterd情况下要好得多,cache的有效利用率达到128/192=67%
关于L2 cache的读写操作
L1 has a cache line size that is fixed at 128 bytes and cannot be changed.
L2 has a cache line size that is fixed at 32 bytes and cannot be changed.
Note that the L1 may be disabled by default on some GPUs, and can be disabled in software.
If the L1 is enabled, a cache line miss will force a load of that cache line, i.e. a 128byte load. This will necessarily result in 4 L2 transactions (4x32=128).
If the L1 is disabled, transactions may attempt to hit in the L2. If they miss in the L2, a DRAM transaction will be generated. The size of this transaction would be 32 bytes.
If the L1 is enabled, and a transaction misses in the L1, it will generate 4 L2 transactions. If all 4 of those L2 transactions also miss, then 4 DRAM read transactions (each of 32 bytes) will be generated. In effect, in this scenario, 128 bytes will be read from DRAM as a result of the miss in L1 and L2.
http://blog.csdn.net/Kelvin_Yan/article/details/53590597
1、引言
2、coalesced memory access


?
在这段代码中,float3类型有12个bytes,不等于要求的4 bytes,8 bytes或16 bytes,half warp读取3个64 bytes中非连续区域,如图:__global__ void accessFloat3 ( float3 * d_in , float3 * d_out ){int index = blockIdx . x * blockDim . x + threadIdx . x ;float3 a = d_in [ index ];a . x += 2 ;a . y += 2 ;a . z += 2 ;d_out [ index ] = a ;}







程序的逻辑关系有时还挺绕的,我们以一个4*4矩阵为例,将逻辑关系展示如下:__global__ void transpose ( float * odata , float * idata , int width , int height ){__shared__ float block [ BLOCK_DIM * BLOCK_DIM ];unsigned int xBlock = blockDim . x * blockIdx . x ;unsigned int yBlock = blockDim . y * blockIdx . y ;unsigned int xIndex = xBlock + threadIdx . x ;unsigned int yIndex = yBlock + threadIdx . y ;unsigned int index_out , index_transpose ;if ( xIndex < width && yIndex < height ){unsigned int index_in = width * yIndex + xIndex ;unsigned int index_block = threadIdx . y * BLOCK_DIM + threadIdx . x ;block [ index_block ] = idata [ index_in ];index_transpose = threadIdx . x * BLOCK_DIM + threadIdx . y ;index_out = height * ( xBlock + threadIdx . y ) + yBlock + threadIdx . x ;}__syncthreads ();if ( xIndex < width && yIndex < height )odata [ index_out ] = block [ index_transpose ];}
















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









