







 本文深入探讨CUDA编程,涉及并行通信模式(Map, Gather, Scatter, Stencil, Transpose)、内存模型、控制流和同步,以及原子操作。重点讲解如何提高GPU计算效率,例如通过最大化算术强度、最小化内存访问和同步线程。"
113663103,10504541,SQL学习:视图VIEW与存储过程PROCEDURE详解,"['SQL', '数据库理论', '程序设计方法']
本文深入探讨CUDA编程,涉及并行通信模式(Map, Gather, Scatter, Stencil, Transpose)、内存模型、控制流和同步,以及原子操作。重点讲解如何提高GPU计算效率,例如通过最大化算术强度、最小化内存访问和同步线程。"
113663103,10504541,SQL学习:视图VIEW与存储过程PROCEDURE详解,"['SQL', '数据库理论', '程序设计方法']
本文为CUDA系列学习第四讲,首先介绍了Parallel communication patterns的几种形式(map, gather, scatter, stencil, transpose), 然后复习了cuda memory model并从high level上分析怎样写出高效代码,最后学习了流程控制(control flow)以及其中一个重要部分——原子操作。参考资料:udacity cs344.
(一). Parallel communication Patterns
在上一章CUDA系列学习(二)CUDA memory & variables中我们介绍了memory和variable的不同类型,本章中根据不同的memory映射方式,我们将task分为以下几种类型:Map, Gather, Scatter, Stencil, transpose.
1.1 Map, Gather, Scatter
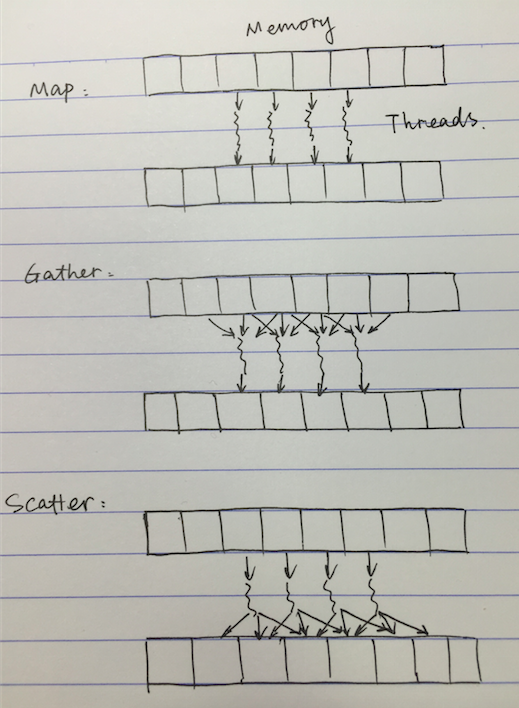
- Map: one input - one output
- Gather: several input - one output
e.g image blur by average - Scatter: one input - several output
e.g add a value to its neighbors
(因为每个thread 将结果scatter到各个memory,所以叫scatter)
图为Map, Gather & Scatter示意图:
1.2 Stencil, Transpose
stencil: 对input中的每一个位置,
stencil input:该点的neighborhood
stencil output:该点value
e.g image blur by average
这样也可以看出,stencil和gather很像,其实stencil是gather的一种,只不过stencil要求input必须是neighborhood而且对input的每一个元素都要操作
图示:- 2D stencil: (示例为两种形式)
- 3D stencil:
- 2D stencil: (示例为两种形式)
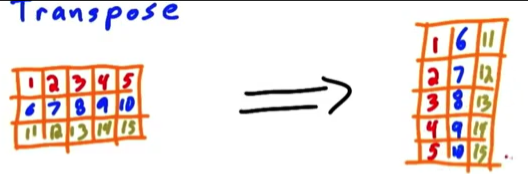
transpose
input:matrix M
output: M^T
图示:Matrix transpose
Transpose represents in vector

Exercise
Q:
看这个quiz图,给每个蓝线画着的句子标注map/gather/scatter/stencil/transpose:

A:四个位置分别选AECB。
这里我最后一个选错成B&D, 为什么不选D呢?看stencil的定义:如果是average,也应该对每一个位置都要进行average,而题目中有if(i%2)这个condition。
那么对于不同的Parallel communication Patterns需要关注哪些点呢?
1. threads怎样高效访问memory?- 怎样重用数据?
2. threads怎样相互交互部分结果?(通过sharing memory)这样安全吗?
我们将在下一节中首先回顾讲过的memory model,然后结合具体问题分析阐述how to program。
(二). Programming model and Memroy model
第一讲和第三讲中我们讲过SM与grid, block, thead的关系:各个grid, block的thread组织(gridDim,blockDim,grid shape, block shape)可以不同,分别用于执行不同kernel。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 131
131

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









