








ECML-PKDD 2022
The European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases
文章目录
1 Background and Motivation
神经网络中,步长大于 1 的卷积层和池化层,存在如下的缺点
suffer from loss of fine-grained information and poorly learned features
当输入分辨率较低,或者小目标较多的时候,上述问题会被放大
作者提出 SPD-Conv 结构(SPD-Conv is a space-to-depth layer followed by a non-strided (i.e., vanilla) convolution layer),网络中无 strided convolution and/or pooling layers,对小目标有一定的提升
2 Related Work

本文的实验基于 one-stage anchor-based 类方法展开的,也即比较流行的 YOLO 系列
one-stage 的基础流程如下

-
Small Object Detection
- image pyramid
- SNIP / SNIPER
- FPN / PANet / BiFPN
- SAN
-
Low-Resolution Image Classification
3 Advantages / Contributions
发现了步长大于 1 的 Conv 和 pooling 层的缺点, 提出 No More Strided Convolutions or Pooling 的 SPD-Conv 结构来替代 Strided Conv 和 pooling,对低分辨率小目标场景有一定提升,代码简单,即插即用

4 Method

SPD 后接一个步长为 1 的卷积是为了减少特征图数量
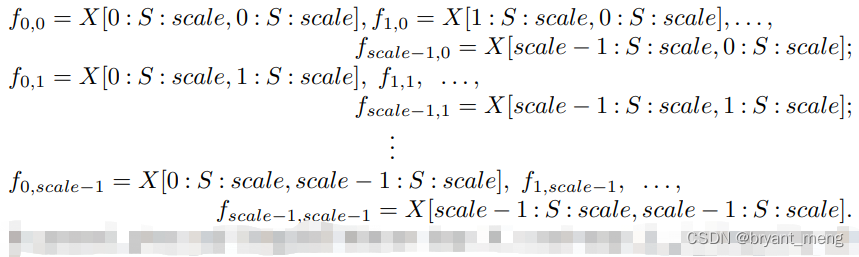
X ( S , S , C ) → X ′ ( S s c a l e , S s c a l e , s c a l e 2 C 1 ) → X ′ ′ ( S s c a l e , S s c a l e , C 2 ) X(S, S, C) \rightarrow X'(\frac{S}{scale}, \frac{S}{scale}, scale^2C_1) \rightarrow X''(\frac{S}{scale}, \frac{S}{scale}, C_2) X(S,S,C)→X′(scaleS,scaleS,scale2C1)→X′′(scaleS,scaleS,C2)
SPD-Conv 使用时采用的 scale 为 2
SPD-conv 本质上就是 Focus 的泛化,并且推广到整个网络而已
应用在 YOLOv5 目标检测器中

two stride-2 convolution layers in the neck
five convolution layers in backbone

应用在分类器中

5 Experiments
5.1 Datasets and Metrics
- COCO-2017 dataset,mAP
- Tiny ImageNet,Top 1, contains 200 classes. Each class has 500 training images, 50 validation images, and 50 test images,图片大小 64×64×3 pixels.
- CIFAR-10,Top 1,图片大小 32×32×3
5.2 Object Detection
COCO 验证集上的结果

模型比较小的时候发挥的效果越大,对小目标的提升很明显
COCO 测试集上的结果

Trf(transfer learning)还是没得说,秒杀,优势还是在小目标
看图

5.3 Image Classification
random grid search to tune hyperparameters including learning rate, batch-size, momentum, optimizer, and weight decay


小分辨率下还是很猛,别人方法效果不好的原因是小分辨的输入 loses fine-grained information during its strided convolution and pooling operations.

6 Conclusion(own) / Future work
看看 SPD 的代码
class space_to_depth(nn.Module):
# Changing the dimension of the Tensor
def __init__(self, dimension=1):
super().__init__()
self.d = dimension
def forward(self, x):
return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
再看看 Focus 的代码,一模一样,推广到了整个网络结构,而不仅仅是用在 first->second stage
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat((x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]), 1))
# return self.conv(self.contract(x))
Otherwise, for instance, using a 3 × 3 filer with stride=3, feature maps will get “shrunk” yet each pixel is sampled only once;
if stride=2, asymmetric sampling will occur where even and odd rows/columns will be sampled different times.
上面描述 3×3 卷积,如果步长为2,奇数和偶数的行或者列被采样的次数不一样,我们以列为例看看

确实,奇数列只被采样了一次,1,3,5…,偶数列被采样了两次,2,4,8,…

















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









