







参考+借鉴+模仿+学习
- Python面向对象编程从零开始(1)——从没对象到有对象
- Python面向对象编程从零开始(2)—— 与对象相互了解
- 【python学习笔记】Python面向对象的理解(封装,继承,多态)
- 分享3 个Python冷知识
最近一次修订时间为:2020-11-04
object oriented programming (OOP)面向对象编程
- 类:对具有相同数据和方法的一组对象的描述或定义。
- 对象:对象是一个类的实例。
- 实例(instance):一个对象的实例化实现。
- 标识(identity):每个对象的实例都需要一个可以唯一标识这个实例的标记。
- 实例属性(instance attribute):一个对象就是一组属性的集合。
- 实例方法(instance method):所有存取或者更新对象某个实例一条或者多条属性的函数的集合。
- 类属性(classattribute):属于一个类中所有对象的属性,不会只在某个实例上发生变化
- 类方法(classmethod):那些无须特定的对性实例就能够工作的从属于类的函数。
1 类、对象、方法
# 定义一个类
class Car:
def drive(self):
print('我正在开车')
def turnover(self):
print('翻车了')
# 创建一个对象
xx = Car()
# 调用类方法
xx.drive()
xx.turnover()
结果为
我正在开车
翻车了
2 类的属性
可以在类中定义属性,也可以在对象中添加属性
class Car:
def drive(selt):
print('我正在开车')
def turnover(self):
print('翻车了')
#创建一个对象
xiao_jie_jie = Car()
xiao_jie_jie.drive()#调用xiao_jie_jie指向的对象的方法
xiao_jie_jie.turnover()
#添加属性,属性就是变量
xiao_jie_jie.name = '小红'
xiao_jie_jie.age = 18
print ("%s的年龄是%d"%(xiao_jie_jie.name,xiao_jie_jie.age))
结果为
我正在开车
翻车了
小红的年龄是18
3 封装、继承、多态
3.1 封装(Encapsulation)
封装:就是隐藏对象的属性和实现细节,仅对外提供公共访问方式(对外部隐藏对象的工作细节)。
list1 = [1,3,2,7,5]
list1.sort()
list1
output
[1, 2, 3, 5, 7]
list1是列表list的实例对象,我们调用了sort方法()
3.2 继承(Inheritance)
子类自动共享父类之间数据和方法的机制
如果一个类 A 继承自另一个类 B,就把这个 A 称为 B 的子类,把 B 称为 A 的父类、基类或超类。继承可以使得子类具有父类的各种属性和方法,而不需要再次编写相同的代码(偷懒)。
在子类继承父类的同时,可以重新定义某些属性,并重写某些方法,即覆盖父类的原有属性和方法,使其获得与父类不同的功能。另外,为子类追加新的属性和方法也是常见的做法。
class list2222 (list):
pass
list2 = list2222()
list2.append(1)
list2.append(3)
list2.append(2)
list2.append(4)
print(list2)
list2.sort()
print(list2)
output
[1, 3, 2, 4]
[1, 2, 3, 4]
list2222继承list类,实例对象list2,也可以调用list的append()、sort()方法
1)如果子类和父类的方法同名,子类会覆盖父类
# 如果子类和父类的方法同名,子类会覆盖父类
class Parent:
def hello(self):
print("****")
class Child(Parent):
def hello(self):
print("####")
p = Parent()
p.hello()
c = Child()
c.hello()
Output
****
####
2)多层继承
# 多层继承 class A(B,C,D……)
class Base1:
def fool1(self):
print("i'm a fool")
class Base2:
def fool2(self):
print("i'm a fool,too")
class A(Base1,Base2):
pass
a = A()
a.fool1()
a.fool2()
Output
i'm a fool
i'm a fool,too
多重继承使用不当会导致重复调用(也叫 钻石继承、菱形继承)的问题,关于__init__的说明请参考本博客的附录
class A():
def __init__(self):
print("进入A…")
print("离开A…")
class B(A):
def __init__(self):
print("进入B…")
A.__init__(self)
print("离开B…")
class C(A):
def __init__(self):
print("进入C…")
A.__init__(self)
print("离开C…")
class D(B, C):
def __init__(self):
print("进入D…")
B.__init__(self)
C.__init__(self)
print("离开D…")
实例化D的时候
d = D()
output
进入D…
进入B…
进入A…
离开A…
离开B…
进入C…
进入A…
离开A…
离开C…
离开D…
进入了两次A。
这有什么危害?我举个例子,假设 A 的初始化方法里有一个计数器,那这样 D 一实例化,A 的计数器就跑两次(如果遭遇多个钻石结构重叠还要更多),很明显是不符合程序设计的初衷的(程序应该可控,而不能受到继承关系影响)
为了让大家都明白,这里只是举例最简单的钻石继承问题,在实际编程中,如果不注意多重继承的使用,会导致比这个复杂N倍的现象,调试起来不是一般的痛苦……所以一定要尽量避免使用多重继承。
如何解决这种问题呢,super()大发神威
class A():
def __init__(self):
print("进入A…")
print("离开A…")
class B(A):
def __init__(self):
print("进入B…")
super().__init__()
print("离开B…")
class C(A):
def __init__(self):
print("进入C…")
super().__init__()
print("离开C…")
class D(B, C):
def __init__(self):
print("进入D…")
super().__init__()
print("离开D…")
实例化
d = D()
output
进入D…
进入B…
进入C…
进入A…
离开A…
离开C…
离开B…
离开D…
3)继承__init__
class Fish1:
def __init__(self):
self.length = 10
self.weight = 5
def eat(self):
self.weight+=1
print("当前的weight:",self.weight)
def growth(self):
self.length+=1
print("当前的length:",self.length)
class Fish2(Fish1):
pass
class Fish3(Fish1):
def __init__(self):
self.hungry = True
#Fish1.__init__(self)
#super().__init__()
def eat(self):
if self.hungry:
print("开吃")
else:
print("吃饱了")
测试
f2 = Fish2()
f2.eat()
f2.growth()
f3 = Fish3()
f3.eat()
f3.growth()
output
当前的weight: 6
当前的length: 11
开吃
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-6-8ce1c7ea1927> in <module>()
5 f3 = Fish3()
6 f3.eat()
----> 7 f3.growth()
<ipython-input-5-2ff9b0c109ac> in growth(self)
7 print("当前的weight:",self.weight)
8 def growth(self):
----> 9 self.length+=1
10 print("当前的length:",self.length)
11
AttributeError: 'Fish3' object has no attribute 'length'
报错了,没有 length 的属性,没有继承父类的__init__,有如下两种解决方法
-
调用未绑定的父类方法
在子类的__init__函数下添加Fish1.__init__(self),不推荐这种方法,因为如果改了继承类还需要修改父类Fish1的名字 -
使用super函数
在子类的__init__函数下添加super().__init__(),推荐这种方法,会自己找继承的父类
修改后的output
当前的weight: 6
当前的length: 11
开吃
当前的length: 11
parent
使用super()或父类的名称调用父类的初始化
super
class Parent:
def __init__(self, city, address):
self.city = city
self.address = address
class Child(Parent):
def __init__(self, city, address, university):
super().__init__(city, address) # 调用父类的初始化方法
self.university = university
child = Child('A', 'B', 'C')
print(child.city, child.address, child.university) # A B C
父类的名字
class Parent:
def __init__(self, city, address):
self.city = city
self.address = address
class Child(Parent):
def __init__(self, city, address, university):
Parent.__init__(self, city, address) # 调用父类的初始化方法,区别于 super,这里需要有 self
self.university = university
child = Child('A', 'B', 'C')
print(child.city, child.address, child.university) # A B C
3.3 动态(Polymorphism)
可以对不同类的对象调用相同的方法,产生不同的结果
class A:
def fun(self):# 记得要加self
print('i love you')
class B:
def fun(self):# 记得要加self
print('i love x')
a = A()
b = B()
a.fun()
b.fun()
output
i love you
i love x
4 公有和私有
class Person:
name = '小明'
person = Person()
person.name
output
'小明'
python属性和方法都是公有的,有 name mangling 机制(在变量名或者函数名之前加上“__”两个下划线,那么这个变量或者函数就会变为私有的了),如下
如果想要在外部访问,那么只需要在名称前面加上 ‘_类名’ 变成 ‘_类名__名称’。
class Engineer:
def __init__(self, name):
self.name = name
self.__starting_salary = 10
dain = Engineer('Dain')
print(dain._Engineer__starting_salary) # 10
print(dain.Engineer__starting_salary) # 报错
output
Traceback (most recent call last):
File "/usercode/file.py", line 9, in <module>
print(dain.Engineer__starting_salary) # 报错
AttributeError: 'Engineer' object has no attribute 'Engineer__starting_salary'
再看看下面的例子
class Person:
__name = '小明'
试试
person = Person()
person.name
output
AttributeError: 'Person' object has no attribute 'name'
再试试
person = Person()
person.__name
output
AttributeError: 'Person' object has no attribute '__name'
都报错了,只能内部访问,外部不行,可以通过定义函数的方式访问
class Person:
__name = '小明'
def get_name(self):
return self.__name
person = Person()
person.get_name()
output
'小明'
但是,name mangling 其实是伪私有,我们可以通过_类名__变量名访问,当然我们并不提倡这种抬杠较真粗暴不文明的访问形式……
class Person:
__name = '小明'
person = Person()
person._Person__name
output
'小明'
Note:python的私有机制是伪私有
5 组合
把类的实例化,放在一个新的类里面,横向之间关系的类用 组合,纵向的用继承
Python 继承机制很有用,但容易把代码复杂化以及依赖隐含继承。因此,经常的时候,我们可以使用组合来代替。在Python里组合其实很简单,直接在类定义中把需要的类放进去实例化就可以了。
class Turtle:
def __init__(self,x):
self.num = x
class Fish:
def __init__(self,x):
self.num = x
# 组合,把类的实例化,放在一个新的类里面
class Pool:
def __init__(self,x,y):
self.turtle = Turtle(x)
self.fish = Fish(y)
def print_num(self):
print("水池里面有乌龟%d 个,有鱼%d个"%(self.turtle.num,self.fish.num))
pool = Pool(1,2)
pool.print_num()
output
水池里面有乌龟1 个,有鱼2个
下面看一个稍微复杂的例子,在附录魔法方法 __str__ 中 小姐姐煮面 例子的基础上改进,这里是买房,构建两个类,一个是房子,一个是家具,都有面积属性,随着家具的增加,房子空余面积变小
class Home:
def __init__(self, area, info, address):
self.area = area # 房子的面积
self.info = info # 房子的户型
self.address = address # 房子的地址
self.left_area = area # 房子空余面积
self.furnitures = [] # 房子中的家具
def __str__(self):
return "房子的面积:{},户型:{},地址:{},现有家具:{},剩余面积:{}".format(self.area, self.info, self.address, self.furnitures,
self.left_area)
def add_furnitures(self, item): # 添加家具
self.left_area -= item.area # 房屋空余面积相应减少
self.furnitures.append(item.furniture) # 新增房子中的家具
class Furniture:
def __init__(self, furniture, area):
self.furniture = furniture # 家具的名字
self.area = area # 家具的面积
def __str__(self):
return "家具{}的面积为{}m2".format(self.furniture, self.area)
home = Home(120, '三室一厅', '上海市 黄浦区 人民大道 666号')
print(home)
bed = Furniture('双人豪华大床', 6)
print(bed)
home.add_furnitures(bed)
print(home)
aircondition = Furniture('立式空调', 1)
home.add_furnitures(aircondition)
print(home)
output
房子的面积:120,户型:三室一厅,地址:上海市 黄浦区 人民大道 666号,现有家具:[],剩余面积:120
家具双人豪华大床的面积为6m2
房子的面积:120,户型:三室一厅,地址:上海市 黄浦区 人民大道 666号,现有家具:['双人豪华大床'],剩余面积:114
房子的面积:120,户型:三室一厅,地址:上海市 黄浦区 人民大道 666号,现有家具:['双人豪华大床', '立式空调'],剩余面积:113
6 属性和方法名相同,方法会被覆盖
class ABC:
def x (self):
print("hello")
abc = ABC()
abc.x()
abc.x = 1
print(abc.x)
abc.x()
output
hello
1
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-21-3e5e59179b1f> in <module>()
6 abc.x = 1
7 print(abc.x)
----> 8 abc.x()
TypeError: 'int' object is not callable
7 绑定
Python 严格要求方法需要有实例才能被调用,这种限制其实就是Python所谓的绑定概念
class BB:
def printBB():
print("hello")
BB.printBB()
bb=BB()
bb.printBB()
output
hello
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-22-dbb760d5e8f1> in <module>()
4 BB.printBB()
5 bb=BB()
----> 6 bb.printBB()
TypeError: printBB() takes 0 positional arguments but 1 was given
附录A:魔法方法
python解释器遇到特殊句法时,会去调用特殊方法,这些特殊方法以双下划线开头
__init__
链接:https://www.zhihu.com/question/46973549/answer/103805810
来源:知乎
定义类的时候,若是添加 _ _ init _ _ 方法,那么在创建类的实例的时候,实例会自动调用这个方法,一般用来对实例的属性进行初使化。比如
class TestClass:
def __init__(self, name, gender):
'''
定义 __init__方法,这里有三个参数,这个self指的是一会创建类的实例的时候这个被创建的实例本身(例中的people),你也可以写成其他的东西,
比如写成me也是可以的,这样的话下面的self.Name就要写成me.Name。
'''
self.Name=name
'''
通常会写成self.name=name,这里为了区分前后两个是不同的东东,把前面那个大写了,等号左边的那个Name(或name)是实例的属性,
后面那个是方法__init__的参数,两个是不同的)
'''
self.Gender=gender
# 通常会写成self.gender=gender
print('hello')
# 这个print('hello')是为了说明在创建类的实例的时候,__init__方法就立马被调用了。
people1 = TestClass('lola','female')
'''
这里创建了类TestClass的一个实例 people1, 类中有__init__这个方法,在创建类的实例的时候,就必须要有和方法__init__匹配的参数了,
由于self指的就是创建的实例本身,self是不用传入的,所以这里传入两个参数。这条语句一出来,实例people1的两个属性Name,
Gender就被赋值初使化了,其中Name是 lola,Gender 是female。
'''
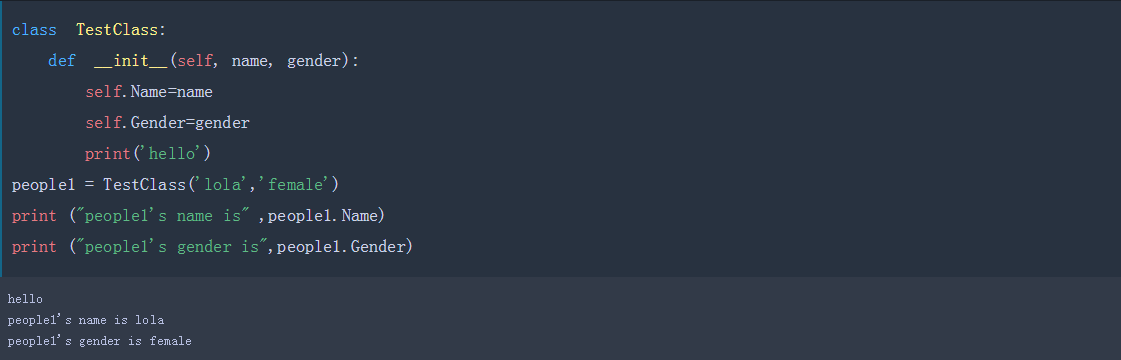
作者:旅人
链接:https://www.zhihu.com/question/46973549/answer/104526401
来源:知乎
class定义出来的是一个类,类有各种参数(属性)和功能(方法)。比如说你定义了一个类–“人”,这个类有身高体重这样的参数,也有吃饭睡觉写字这种功能。你可以用这个类来创建出一个“张三”,再创建出一个“李四”,他们之间没有关系,你也可以随便设置他们的参数,让他们做不同的事情。这就是一个类可以生成多个对象,而 _ _ init _ _简单的来说,就是在用这个类创建一个新的对象时,该做点什么,比如说“人”在刚被创建时,至少应该哭几声嘛。
Note:
class A:
def __init__(self):
return "I love you"
a = A()
output
TypeError Traceback (most recent call last)
<ipython-input-4-66ee88c1e405> in <module>()
2 def __init__(self):
3 return "I love you"
----> 4 a = A()
TypeError: __init__() should return None, not 'str'
_init_ 特殊方法不应当返回除了 None 以外的任何对象
小例子
class Car:
def drive(self):
print ("driving")
def turnover(self):
print ("turnover")
def __init__(self,name,age):
self.age = age
self.name = name
def feature(self):
print("%s的年龄是%d"%(self.name,self.age))
xx = Car("MM",18)
xx.drive()
xx.turnover()
xx.feature()
结果为
driving
turnover
MM的年龄是18
__new__
__new__ 和 __init__ 谁先执行,谁后执行,看看下面的的例子
class test(object):
def __init__(self):
print("test -> __init__")
def __new__(cls):
print("test ->__new__")
return super().__new__(cls)
a = test()
print("\n")
class test2(object):
def __init__(self):
print("test2 -> __init__")
def __new__(cls):
print("test2 ->__new__")
return object()
b = test2()
print("\n")
print(type(a))
print(type(b))
output
test ->__new__
test -> __init__
test2 ->__new__
<class '__main__.test'>
<class 'object'>
__init__ 作用是类实例进行初始化,第一个参数为 self,代表对象本身,可以没有返回值。__new__ 则是返回一个新的类的实例,第一个参数是 cls 代表该类本身,必须有返回值。很明显,类先实例化才能产能对象,显然是 __new__ 先执行,然后再 __init__,实际上,只要 __new__ 返回的是类本身的实例,它会自动调用 __init__ 进行初始化。但是有例外,如果 __new__ 返回的是其他类的实例,则它不会调用当前类的 __init__
__getitem__
实例[idx] 时触发
pytorch 中自定义数据集的读取时会涉及到 【Pytorch】Load your own dataset
参考 init()与__getitem__()及__len__()
__call__
实例(…) 时触发(等价于 实例.__call__() )
但凡是可以把一对括号 () 应用到某个对象身上都可称之为可调用对象,判断对象是否为可调用对象可以用函数 callable
一个类实例要变成一个可调用对象,只需要实现一个特殊方法__call__()
__call__在那些类的实例经常改变状态的时候会非常有效。调用这个实例是一种改变这个对象状态的直接和优雅的做法
class Person:
def __init__(self, name, gender):
self.name = name
self.gender = gender
def __call__(self, name):
self.name = name
p = Person("Bryant","Male")
print("callable:",callable(p))
print("name:",p.name)
print("gender:",p.gender,"\n")
p("James") # change the name
print("new name:",p.name)
print("gender:",p.gender)
output
callable: True
name: Bryant
gender: Male
new name: James
gender: Male
如果不定义 __call__,callable(p) 为 False,p("James") 时会报错 TypeError: 'Person' object is not callable
__str__
当使用 print 输出对象的时候,只要自己定义了__str__(self) 方法,那么就会打印从在这个方法中 return 的数据
参考
Python str() 方法
Python面向对象编程从零开始(5)—— 小姐姐要买房
Python面向对象编程从零开始(4)—— 小姐姐请客下篇
Python面向对象编程从零开始(3)—— 小姐姐请客上篇
下面以小姐姐做面为例,实现随着烹饪时间的推移,添加佐料,提示烹饪状态的功能
class Cook_instant_noodles:
def __init__(self):
self.cookedState = '生的' # 烹饪状态
self.cookedLevel = 0 # 烹饪累计时间
self.condiment = [] # 佐料
def __str__(self):
# 当使用 print 输出对象的时候,只要自己定义了__str__(self) 方法,那么就会打印从在这个方法中 return 的数据
return '泡面状态:{}({}), condiments: {}'.format(self.cookedState, self.cookedLevel, self.condiment)
def add_condiments(self, item): # 添加佐料
self.condiment.append(item)
def cook(self, cooked_time): # 烹饪时间不同,烹饪的状态也不同
self.cookedLevel += cooked_time
if 0 <= self.cookedLevel < 3:
self.cookedState = '还没熟'
elif 3 <= self.cookedLevel < 5:
self.cookedState = '半生不熟'
elif 5 <= self.cookedLevel < 8:
self.cookedState = '煮熟了'
elif self.cookedLevel >= 8:
self.cookedState = '煮糊了'
# 创建了一个泡面对象
instant_noodles = Cook_instant_noodles()
print(instant_noodles)
# 开始煮泡面
instant_noodles.cook(1)
print(instant_noodles)
# 加入调料包
instant_noodles.add_condiments('菜包')
instant_noodles.add_condiments('粉包')
instant_noodles.add_condiments('酱包')
# go on
instant_noodles.cook(1)
print(instant_noodles)
# 加入调料包
instant_noodles.add_condiments('茶叶蛋')
instant_noodles.add_condiments('火腿肠')
# go on
instant_noodles.cook(1)
print(instant_noodles)
instant_noodles.cook(1)
print(instant_noodles)
instant_noodles.cook(1)
print(instant_noodles)
instant_noodles.cook(1)
print(instant_noodles)
instant_noodles.cook(1)
print(instant_noodles)
instant_noodles.cook(1)
print(instant_noodles)
output
泡面状态:生的(0), condiments: []
泡面状态:还没熟(1), condiments: []
泡面状态:还没熟(2), condiments: ['菜包', '粉包', '酱包']
泡面状态:半生不熟(3), condiments: ['菜包', '粉包', '酱包', '茶叶蛋', '火腿肠']
泡面状态:半生不熟(4), condiments: ['菜包', '粉包', '酱包', '茶叶蛋', '火腿肠']
泡面状态:煮熟了(5), condiments: ['菜包', '粉包', '酱包', '茶叶蛋', '火腿肠']
泡面状态:煮熟了(6), condiments: ['菜包', '粉包', '酱包', '茶叶蛋', '火腿肠']
泡面状态:煮熟了(7), condiments: ['菜包', '粉包', '酱包', '茶叶蛋', '火腿肠']
泡面状态:煮糊了(8), condiments: ['菜包', '粉包', '酱包', '茶叶蛋', '火腿肠']
__slots__
用「__slots__」节省内存
如果你曾经编写过一个创建了某种类的大量实例的程序,那么你可能已经注意到,你的程序突然需要大量的内存。那是因为 Python 使用字典来表示类实例的属性,这使其速度很快,但内存使用效率却不是很高。通常情况下,这并不是一个严重的问题。但是,如果你的程序因此受到严重的影响,不妨试一下「__slots__」:
class Person:
__slots__ = ["first_name", "last_name", "phone"]
def __init__(self, first_name, last_name, phone):
self.first_name = first_name
self.last_name = last_name
self.phone = phone
当我们定义了「__slots__」属性时,Python 没有使用字典来表示属性,而是使用小的固定大小的数组,这大大减少了每个实例所需的内存。使用「__slots__」也有一些缺点:我们不能声明任何新的属性,我们只能使用「__slots__」上现有的属性。而且,带有「__slots__」的类不能使用多重继承。
附录 B
hasattr()
判断对象是否包含对应的属性(参考 Python hasattr() 函数)

class Demo:
def __init__(self):
self.x = 1
self.y = 2
self.z = 3
def test1(self):
pass
demo = Demo()
print(hasattr(demo,"x"))
print(hasattr(demo,"y"))
print(hasattr(demo,"z"))
print(hasattr(demo,"test1"))
print(hasattr(demo,"w"))
output
True
True
True
True
False
getattr()
getattr() 函数用于返回一个对象属性值。Python getattr() 函数

class Foo:
def __init__(self):
self.a = 10
foo = Foo()
if hasattr(foo,"a"):
print("bingo!!!")
print(getattr(foo, "a"))
if hasattr(foo,"b"):
print("sorry...")
print(getattr(foo, "b"))
output
bingo!!!
10
class Foo:
def __init__(self):
self.a = 10
foo = Foo()
print(getattr(foo, "b", 11))
print(getattr(foo, "b"))
第一行会报错,第二行会输出设定的默认值
11
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-45-0b35a6049ee9> in <module>
6
7 print(getattr(foo, "b", 11))
----> 8 print(getattr(foo, "b"))
AttributeError: 'Foo' object has no attribute 'b'
Q1:类和对象是什么关系呢?
答:类和对象的关系就如同模具和用这个模具制作出的物品之间的关系。一个类为它的全部对象给出了一个统一的定义,而他的每个对象则是符合这种定义的一个实体,因此类和对象的关系就是抽象和具体的关系。
Q2:函数和方法有什么区别?
细心的童鞋会发现,方法跟函数其实几乎完全一样,但有一点区别是方法默认有一个 self 参数。
Q3:self参数的作用是什么?
答:绑定方法,据说有了这个参数,Python 再也不会傻傻分不清是哪个对象在调用方法了,你可以认为方法中的 self 其实就是实例对象的唯一标志。
Q4:当子类定义了与相同名字的属性或方法时,Python 是否会自动删除父类的相关属性或方法?
不会删除!Python 的做法跟其他大部分面向对象编程语言一样,都是将父类属性或方法覆盖,子类对象调用的时候会调用到覆盖后的新属性或方法,但父类的仍然还在,只是子类对象“看不到”。
Q5: 类对象是在什么时候产生?
当你这个类定义完的时候,类定义就变成类对象,可以直接通过“类名.属性”或者“类名.方法名()”引用或使用相关的属性或方法。
大多数情况下,你应该考虑使用实例属性,而不是类属性(类属性通常仅用来跟踪与类相关的值)。
eg:在一个类中定义一个变量,用于跟踪该类有多少个实例被创建(当实例化一个对象,这个变量+1,当销毁一个对象,这个变量自动-1)。
class C:
count = 0
def __init__(self):
C.count+=1
def __del__(self):
C.count-=1
实例化
a = C()
b = C()
c = C()
print(C.count)
del a
print(C.count)
del b,c
print(C.count)
output
3
2
0
附录 C
相同对象的判断
class Bryant:
pass
print(Bryant() == Bryant())
print(Bryant() is Bryant())
print(id(Bryant()) == id(Bryant()))
print(hash(Bryant()) == hash(Bryant()))
output
False
False
True
True
是不是有些困惑
class Bryant:
def __init__(self):
print("I")
def __del__(self):
print("D")
print(Bryant() == Bryant())
print(Bryant() is Bryant())
print(id(Bryant()) == id(Bryant()))
print(hash(Bryant()) == hash(Bryant()))
output
I
I
D
D
False
I
I
D
D
False
I
D
I
D
True
I
D
I
D
True
从结果可以看出,对象销毁的顺序是造成 False 的原因,当我们连续两次进行这个操作时, Python 会将相同的内存地址分配给第二个对象
id 和 hash 函数使用对象的内存地址作为对象的 id 和 hash 值, 所以两个对象的 id 和 hash 值是相同的
重复定义方法
可以在同一个作用域内多次定义一个方法
但是,只有最后一个会被调用,覆盖以前。
def get_address():
return "First address"
def get_address():
return "Second address"
def get_address():
return "Third address"
print(get_address()) # Third address
ctx
来自 Python ctx
ctx 是 context 的缩写, 翻译成"上下文; 环境"
ctx 专门用在静态方法中,替代 self
self指的是实例对象; 而ctx用在静态方法中, 调用的时候不需要实例化对象, 直接通过类名就可以调用, 所以 self 在静态方法中没有意义
自定义的 forward() 方法和 backward() 方法的第一个参数必须是ctx; ctx 可以保存 forward() 中的变量,以便在 backward() 中继续使用, 下一条是具体的示例

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









