








CVPR-2018
caffe 代码:https://github.com/hujie-frank/SENet
caffe 代码可视化工具:http://ethereon.github.io/netscope/#/editor
1 Background and Motivation
CNN extract informative features by fusing spatial and channel-wise information together within local receptive fields.
为了 增强 CNN 的 representation power
- several methods:enhancing spatial encoding(spatial correlations、spatial attention)比如,inception 中的多个感受野 concatenate
- 作者:focus on the channel relationship
因此作者设计出 Squeeze-and-Excitation 结构,emphasise informative features and suppress less useful ones(channel-wise)
2 Advantages
- ILSVRC2017 classification first place
- reduced the top-5 error to 2.251%
The development of new CNN architectures is a challenging engineering task, typically involving the selection of many new hyperparameters and layer configurations.
3 Related work
-
Deep architecture
-
Attention and gating mechanisms
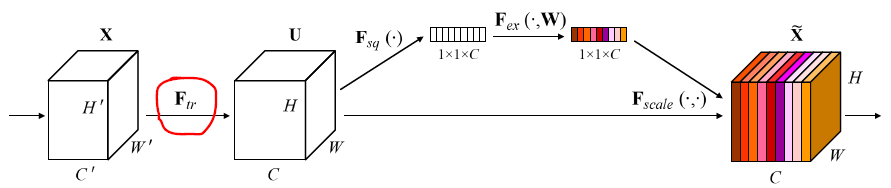
4 Method
the role it performs at different depths adapts to the needs of the network
- In the early layers, it learns to excite informative features in a class agnostic manner
- In later layers, the SE block becomes increasingly specialised(in a highly class-specific manner)
SE 结构可以自成一派(用 SE block stacking 成 neural network),也可以中西结合,即插即用,as a drop-in replacement for the original block at any depth in the architecture(eg,resnet、resnext 的 bottleneck block).
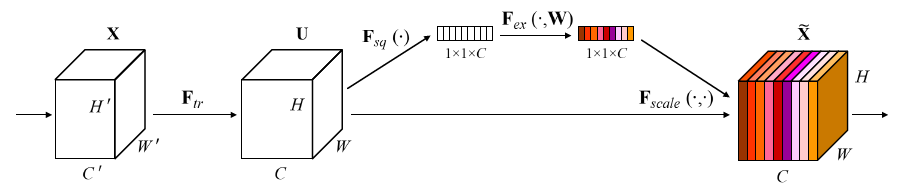
F
t
r
F_{tr}
Ftr is a convolution operator ,
F
t
r
:
X
→
U
F_{tr}:X→U
Ftr:X→U,具体运算如下
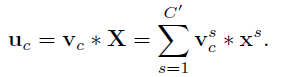
对于上面公式的理解,可以参考如下图片

X
X
X 即为输入的 feature map,
V
c
V_c
Vc (上图红色字体,小写c,黑色的为大写)为某个 filter,
u
c
u_c
uc (上图红色字体,小写c,黑色的为大写)是某个生成的结果!
其中
V
=
[
v
1
,
v
2
,
.
.
.
,
v
C
]
V = [v_1,v_2,...,v_C]
V=[v1,v2,...,vC](大写的 C)
其中
U
=
[
u
1
,
u
2
,
.
.
.
,
u
C
]
U = [u_1,u_2,...,u_C]
U=[u1,u2,...,uC](大写的 C)
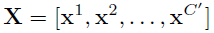
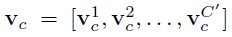
上标表示 spatial kernel,也即我图片中拆分出
X
X
X 和
v
c
v_c
vc(小写的 c )画出来的部分!这样就明朗了很多,至于从这个耳熟能详的公式,如何就能引发对 channels 的特征重要性的思考,进而提出 SE block 的结构,我目前还体会不出来!
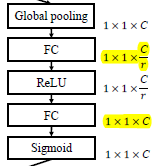
4.1 Squeeze: Global Information Embedding

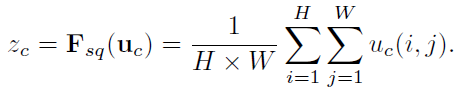
u
c
u_c
uc 是特征图
u
u
u 的
c
c
c 通道,上面的公式是对该通道进行 global average pooling,
z
c
z_c
zc 为标量,是 channel descriptor(如下图) 的一小格
当然,global average pooling 只是一种统计全局信息的方式,more sophisticated aggregation strategies could be employed here as well.
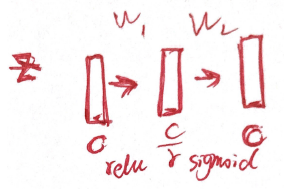
4.2 Excitation: Adaptive Recalibration
两个设计准则
- flexible(channels 之间有 non-linear interaction)
- non-mutually-exclusive(非互斥的,避免 one-hot)
作者落地的方式为:employ a simple gating mechanism with a sigmoid activation,再细化一点即 two fully connection,再具体一点,如下图所示,第一个 fc 降低 dimension,activation function 为 relu,第二个还原为原来的 dimension,activation function 为 sigmoid(借鉴 LSTM 中的门机制)
公式如下:
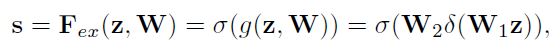
δ
\delta
δ 为 relu,
σ
\sigma
σ 为 sigmoid
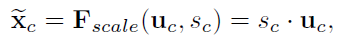
上述公式的意义为,
U
U
U 的一个 channels 与
s
s
s 的一个 dimension 相乘,相当于对 feature map 的加权!对应如下图
F
s
c
a
l
e
F_{scale}
Fscale 部分!

最后的输出
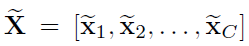
总结一下
- F s q F_{sq} Fsq global average pooling
- F e x F_{ex} Fex two fully connection
- F s c a l e F_{scale} Fscale feature map ( U U U) multiply channels weight ( F e x F_{ex} Fex 的输出结果)
4.3 Exemplars: SEInception and SEResNet
- SEInception:
F t r F_{tr} Ftr 替换成 Inception block,关于 Inception 的理论与实践,可以参考 https://blog.csdn.net/bryant_meng/article/details/78597190 中1.1 Classification / Object Detection和4.1 【Keras】Classification in CIFAR-10 系列连载

左边正常的 inception,右边 SE-Inception
- SE-ResNet:

F t r F_{tr} Ftr 替换成 non-identity branch of a residual module
4.4 Model and Computational Complexity
trade-off between model complexity and performance
| ResNet-50 | SE-ResNet-50 | |
|---|---|---|
| GPU:training a mini-batch 256 images,8 TItan X | 190 ms | 209 ms |
| CPU:inference | 164 ms | 167ms |
global pooling and inner product are less optimised in existing GPU libraries
额外的参数量如下:two FC layers of the gating mechanism
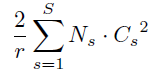
- s 为 stage
- r 为 reduction ratio
- N s N_s Ns 为 repeated block number for stage s.
- C s C_s Cs 为 the dimension of the output channels,也即 number of channels
看这个图就知道怎么计算了 ,某个 stage 中的一个 block 的计算量增加量为
C
r
∗
C
+
C
r
∗
C
\frac{C}{r}*C+\frac{C}{r}*C
rC∗C+rC∗C,我们都知道,越后面的 stage,C 越大,增加的计算量也越大,作者实验表明,去掉后面 stage 的 SE 结构,效果不会降太多,但是计算量会增加的少一些!
5 Experiments
database
- ImageNet 2012
- COCO
- Places 365-Challenge
r r r :reduction ratio is 16
5.1 ImageNet Classification

看 SENet 的小括号,加 SE 结构效果都有提升!看看下面训练和测试的 loss

看看在轻量级网络上的表现

看 table 2 和 table 3 SENet 小括号中的内容就说明了一起,强,有普适性, can be used in combination with a wide range of architectures.(residual or no residual)
华山论剑,一决雌雄

5.2 Scene Classification
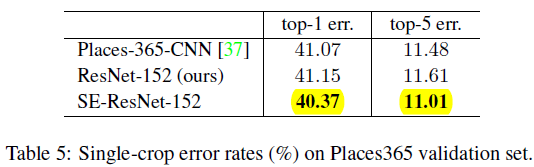
providing evidence that SE blocks can perform well on different datasets
5.3 Object Detection on COCO

基于 Faster R-CNN,猛猛猛
5.4 Analysis and Interpretation
1)Reduction ratio
r
r
r :作者设置 reduction ratio 为 16,trade-off between model complexity and performance

2)The role of Excitation
感觉是统计 SE block 在 squeeze 之后,excitation之前的 activation 情况,5 类,每类 50 个样本,average activations for fifty uniformly sampled channels

作者有如下三个发现:
- lower layer features are typically more general(例如(a),说明特征共享)
- higher layer features have greater specificity(例如(c)、(d),不同类别的不同 channels激活值不一样)
- (e)中,activation 为1,也即类似于 identity 了, 所以在此处加不加 SE block 不是那么重要,不加的话还可以大量减少计算量,参考本博客 4.4 小节的分析!
小节
利用了 gate mechanism,有普适性,图 5 的关于特征的分析尤为重要,以及 reduction ratio(two fully connection 中)complexity 和 performance 的 trade off!















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









