







问题:磁盘故障预测(Disk Failure Prediction)
(一)背景和说明
在大规模IDCS和云计算环境中,各种磁盘故障是罕见但昂贵的事情。因此,为了节约成本,HDD供应商非常积极的去降低故障率。幸运的是,我们有S.M.A.R.T.(自监控、分析和报告技术),从计算机硬盘驱动器(HDDs)、固态驱动器(SSDs)和eMMC驱动器收集的日志,这些日志报告各种驱动器SMART属性,目的是预测硬件故障。SMART属性表示HDD健康状况统计信息,例如扫描错误的数量,重新分配计数和HDD的试用计数。如果被认为对HDD健康状况至关重要的属性超过一定阈值,则HDD被标记为可能故障。自2013年以来,Backbreze根据他们的数据中心发布了统计数据和相关分析,以及这些报告的数据。关于本问题,您可以从Backblaze网站下载SMART日志,然后需要设计并实现一种基于机器学习的解决方案,来预测每天的磁盘故障(在每个测试日输出预测结果)。解决方案应包括以下几个部分:
·数据预处理和特征工程的方法或流程。
·如何选择机器学习模型并调整参数?
·如何评估结果?
·从这项任务中获得哪些经验教训?
提示:
·您可从这里了解更多的背景信息。
·您可以考虑以周或以月来评估结果。
·需提供代码和结果图表。
(二)相关研究[1]
Pinheiro等人在Google数据中心分析了超过10万个企业级硬盘驱动器中的大型磁盘驱动器的故障趋势。他们发现特定的SMART参数(扫描错误,重新分配计数,离线重新分配计数和试用计数)跟故障有很大关系。最重要的是,大部分故障驱动器在其所有监测的SMART属性中都没有出现故障迹象,因此不太可能实现仅基于SMART信号建立准确的预测故障模型[2]。
BackBlaze分析了其HDD故障和SMART属性之间的相关性,并发现了SMART5,187,188,197和198与HDD故障的相关率最高。这些SMART属性还与扫描错误,重新分配计数和试用计数有关[3]。
El-Shimi等发现在随机森林模型中除了以上5个特征还有这5个SMART属性有最大权重,它们是:SMART9,193,194,241,242[7]。
Pitakrat等人评估了21种用于预测硬盘故障的机器学习算法。 Pitakrat等人发现,在测试的21种ML算法中,随机森林算法在ROC曲线下有最大面积,而KNN分类器具有最高的F1值[4]。
Hughes等人也研究用于预测HDD故障的机器学习方法。他们分析了SVM,朴素贝叶斯的表现。 SVM实现了最高性能,检测率为50.6%,误报率为0%[5]。
(三)数据集
实验使用Backblaze.com上的BackBlaze Dataset。Backblaze是一个在线备份和云存储提供商,可在86529个企业硬盘上开源公共信息。Backblaze提供2013-至今期间HDD的SMART属性和健康状况的每日快照报告。这些硬盘驱动器来自众多硬盘驱动器供应商,包括:希捷,日立,HGST,西部数据,东芝和三星,容量从2TB到8TB[6] 。
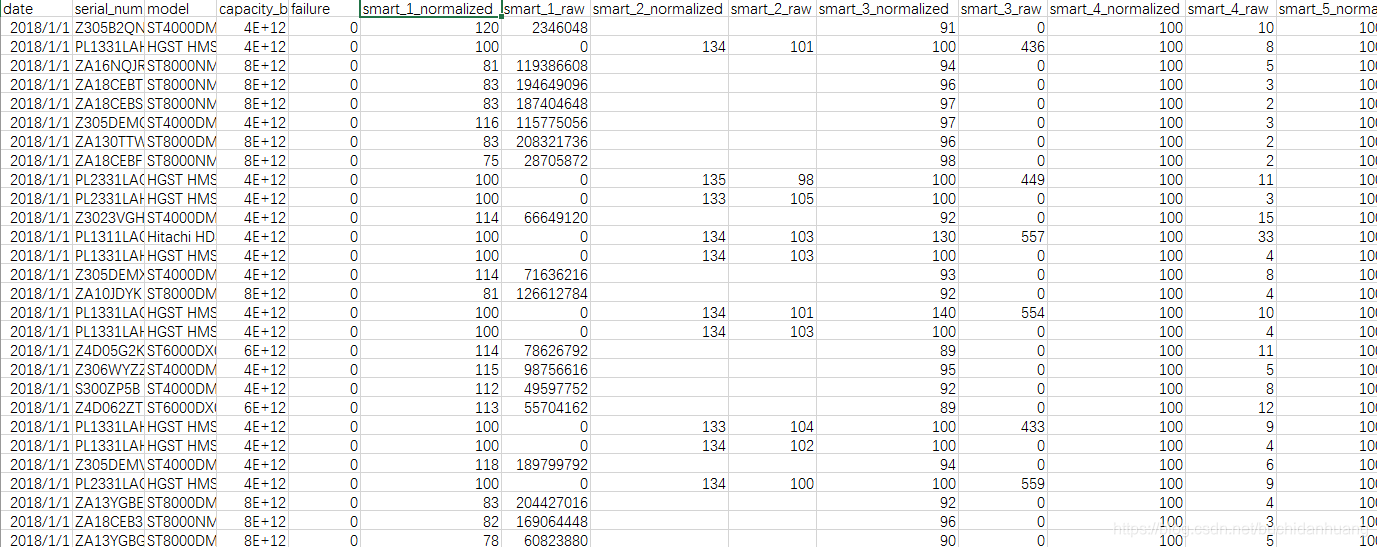
如上图所示,2018年第一季度每个csv文件包含255个变量,这些变量代表原始和规范化形式的SMART特征,以及收集数据的日期,HDD的序列号,型号,总容量(以字节为单位)和故障状态(0表示未故障1表示故障)。一旦HDD的故障状态变为1,它就表示故障并随后从所有未来的数据列表中删除并将新硬盘添加到数据中。由于每个供应商都有自己的收集SMART属性的方法,因此并非所有HDD都包含相同的SMART属性集。所以你可以看到有些特征是空的。如果磁盘的SMART属性为空且它是用于预测的属性的话,那么我们对数据点用零进行填充。
为了在各个模型中获得一致的结果,所有模型都用2018年第一季度到2018年第三季度的9个月数据训练。然后,所有模型使用2018年第四季度数据进行测试。
(四)KNN实验
4.1 数据预处理
·过滤指定特征的原始数据而非正则化数据:正则化定义不明(如有必要可自行定义并进行正则化)
·为减小样本点X中0与非0元素的差异,对X进行log(x+1)操作;KNN不需要正则化这会使得样本点抱团
·故障平滑或回溯:对故障HDD选前n天进行回溯,重置failure status为1记为正样本
·选择特定型号HDD:我们选的是“ST4000DM000”型号,因为可用数据量大
·平衡数据集:对于故障硬盘,随机采该盘正常时的n天数据
4.2 特征工程:这里只考虑特征选择
简要的概述一下特征工程:特征工程需要做两件事1.特征构建2.特征选择。当没有特征时我们要去构建去设计特征,当有了可选特征时我们要从特征集合中去选择特征子集来做实验。其中特征选择需要回答一下4个问题:1.如何进行特征选择(即选哪些特征) 2.为什么要选这些特征3.如何获得这些特征。对于第一点如何进行特征选择也即选哪些特征一般的方法是:a)过滤式选择:例如根据已有的研究成果进行挑选 b)包裹式选择:根据实验结果选择特征子集 c)嵌入式选择:自动选择,相比上面的缺点是我不知道它选了啥特征[8]。回答了如何进行特征选择(选哪些特征)也在一定程度上回答了为什么要选这些特征。利用传统机器学习方法的话一定会涉及到特征提取和选择问题,而且特征这里面可以大作文章例如a方法一般用于简单实验比如本文,b方法一般用于工业界,c方法一般用于学术创新;而利用深度学习方法的话它不太刻意去做特征挑选而是重点在如何将原始数据特征化、量化,在较高级的特征空间中特征的提取、选择是在深度网络中自动完成的,这带来的好处是不用过多的人工设计挑选提取特征,缺点是特征是什么未知。
200多个变量和数百万个数据点不仅需要花费大量时间进行训练和测试,而且还会导致过度拟合。为了减少计算工作量并提高模型的性能,我们仅选择最相关的属性特征,并避免使用大量空值的数据点。
由于计算机上的RAM有限,我们将属性个数限制为最多10个SMART属性。首先,根据BackBlaze分析我们选择了这五个与磁盘故障高度相关的特征:SMART 5,187,188,197和198。然后我们根据El-Shimi的实验分析,还有这5个特征也可以考虑它们是:SMART9,193,194,241,242。值得注意的是这10个特征在不同的模型中也不是都全用,比如在Logistic回归中有人使用SMART 193,194,241,197和9,Naive Bayes中有人只用SMART 5,187,188,197和198,Random Forest使用SMART5,187,188,197,198,9,193,194,241和242(10个全用)作为其输入特征。对于KNN,我将选择所有这10个特征。
4.3 模型的选择
这里挑选KNN模型来实验(有必要的话各种模型都尝试一下进行比较)。KNN优点:精度高、对异常值不敏感、对输入没有特定假设要求;缺点:计算复杂度高,空间复杂度高。调参:k取2, 3, 5, 7。
4.4 模型的评估
评估方法:十折交叉验证;评估指标:Precision,Recall,Accuracy,F1,ROC曲线
4.5 实验结果
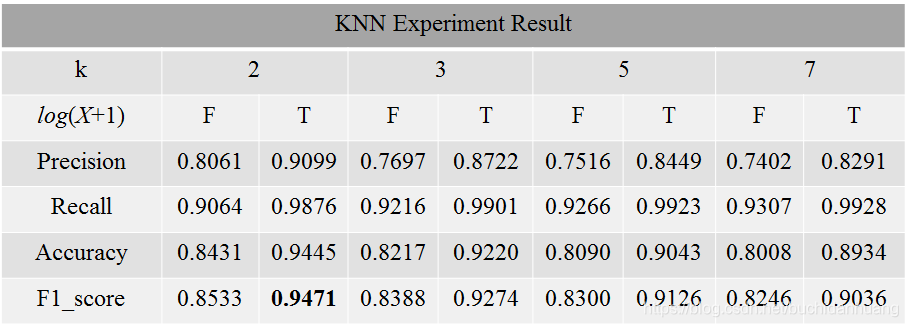
有必要可以多跑几个模型,进行横纵向比较,找到最优模型。这里log(x+1)处理项中F表示没有对X进行处理,T表示进行了该处理,从结果我们可以发现应当对原始数据进行对数化处理以保证减少输入数据值间的差距。
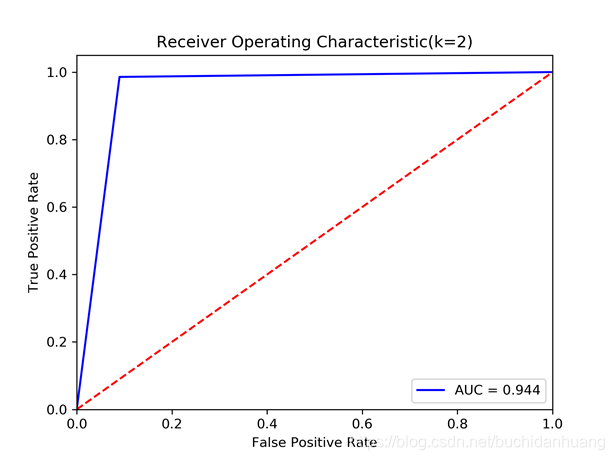
开源代码
Reference:
[1] 主要参考:Proactive Prediction of Hard Disk Drive Failure
[2] Pinheiro, Eduardo, Wolf-Dietrich Weber, and Luiz André Barroso. "Failure Trends in a Large Disk Drive Population." FAST. Vol. 7. No. 1. 2007.
[3] Klein, Andy. “What SMART Hard Disk Errors Actually Tell Us.” Backblaze Blog | Cloud Storage & Cloud Backup,6 Oct. 2016, www.backblaze.com/blog/what-smart-stats-indicate-hard-drive-failures/.
[4] Pitakrat, Teerat, André van Hoorn, and Lars Grunske. "A comparison of machinelearning algorithms for proactive hard disk drive failure detection." Proceedings of the 4thinternational ACM Sigsoft symposium on Architecting critical systems. ACM, 2013.
[5] Hughes, Gordon F., et al. "Improved disk-drive failure warnings." IEEE Transactions on Reliability 51.3 (2002):350-357.
[6] Beach, Brian. “Hard Drive SMART Stats.” Backblaze Blog | Cloud Storage & Cloud Backup, 27 Jan. 2015,www.backblaze.com/blog/hard-drive-smart-stats/.
[7] El-Shimi, Ahmed. “Predicting Storage Failures.” VAULT-Linux Storage and File Systems Conference.VAULT-Linux Storage and File Systems Conference, 22 Mar. 2017, Cambridge.
[8] 周志华.机器学习[M].北京:清华大学出版社,2016:247-251.

















 638
638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









