






 本文介绍了加利福尼亚大学和英伟达合作开发的CleanUNet2模型,它结合了基于频谱图和波形的去噪策略,以提高高噪声环境下的语音质量。模型通过自注意力块优化表示,并在DNS2020数据集上表现出色。
本文介绍了加利福尼亚大学和英伟达合作开发的CleanUNet2模型,它结合了基于频谱图和波形的去噪策略,以提高高噪声环境下的语音质量。模型通过自注意力块优化表示,并在DNS2020数据集上表现出色。
CleanUNet 2:基于波形和频谱图的混合语音去噪模型
第一章 语音增强之《CleanUNet 2: A Hybrid Speech Denoising Model on Waveform and Spectrogram》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是加利福尼亚大学和英伟达。
一、任务
本文介绍了一种名为CleanUNet 2的混合语音去噪模型。它使用基于频谱图的去噪器和基于波形的去噪器作为子模块。使用CleanUNet作为基于波形的子模块,并引入CleanSpecNet作为基于频谱图的子模块。
二、动机
基于谱图的方法在中等噪声水平下工作良好,但在高噪声水平下会有明显的噪声泄漏,这主要是由于噪声语音的相位估计不准确。基于波形的方法在高噪声水平下能很好地防止噪声泄漏,但会有一些语音质量下降。为了进一步提高去噪质量,作者提出将频谱图和基于波形的去噪方法的优点结合起来。
三、挑战
不同的方法在高噪声水平下有不同的缺点。
四、方法
1.模型图
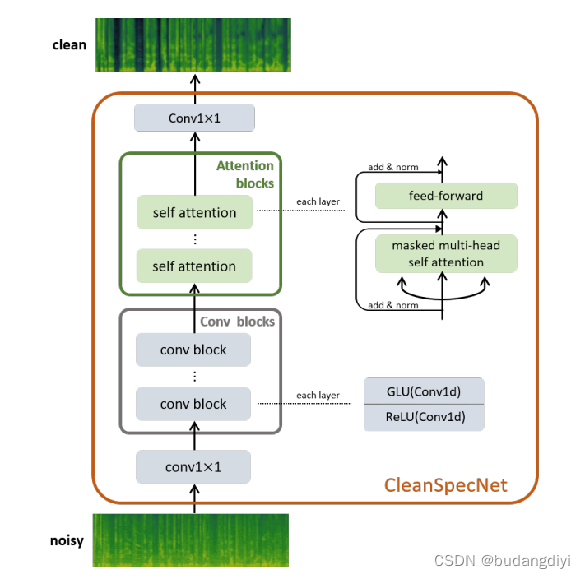
首先训练基于谱图的去噪器。然后,给出基于谱图的去噪器的预测谱图,训练基于波形的去噪器。在预测谱图上训练波形模型在语音合成中是有益的,因为它减少了两级系统中的误差传播。
CleanSpecNet由一堆卷积层组成,后跟一堆自注意力块 。每个卷积层由一个保留通道的1-D卷积(Conv1d)、(ReLU)、另一个通道加倍的Conv1d和(GLU)组成。每个Conv1d的卷积核大小为K,步幅为1。每个自注意力块包含:i) 一个拥有8个头、512个模型维度和因果关注掩码的多头自注意力层,以及 ii) 一个位置逐层全连接层。
作者使用CleanUNet架构作为基于波形的模型的主要组件,因此作者将混合模型命名为CleanUNet 2。它是灵活的,可以很容易地与任何基于频谱图的去噪器组合。
2.loss
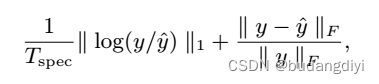
其中Tspec 是谱图的长度。
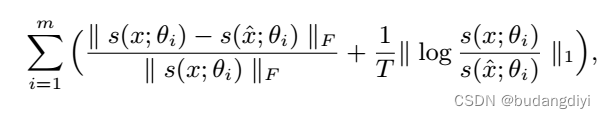
其中{θ1,···,θm}为m个不同分辨率的STFT超参数。多分辨率STFT损失。
3. CleanUNet 2
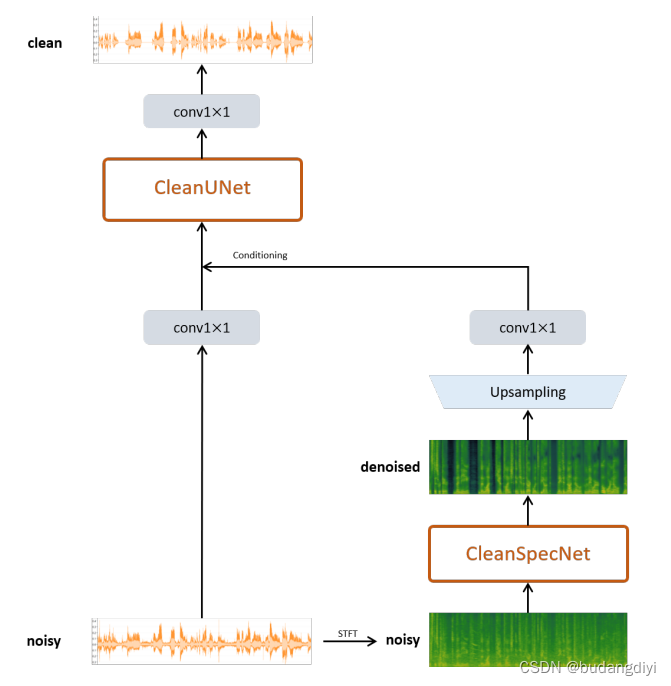
由编码器层、自注意块(瓶颈)和解码器层组成,解码器层通过跳过连接与编码器层连接。作者用CleanSpecNet计算去噪的频谱图之后,通过2个转置的二维卷积对其进行256次上采样。
CleanUNet的超参数如下:它有8个编码器/解码器层,每个层的隐藏维度H = 64,步长S = 2,内核大小K = 4。它有5个自注意块,每个有8个头,模型维度= 512,无dropout,无位置编码。CleanSpecNet的超参数如下:它有5个卷积层,每个层的隐藏维度H = 64,步长S = 1,内核大小K = 4。它有5个自注意块和CleanUNet一样。
4.
五、实验评价
1.数据集
DNS 2020数据集包含441小时的干净语音(2150名说话者阅读书籍)和70K噪声片段,均为16kHz采样率。
2.消融实验
3.客观评价
i)语音质量的感知评价(PESQ,其中WB表示宽带,NB表示窄带),ii)短时客观可理解性(STOI),以及iii)语音信号失真(SIG),背景噪声侵入性(BAK)和c)整体质量(OVRL)的平均意见评分(MOS)预测。
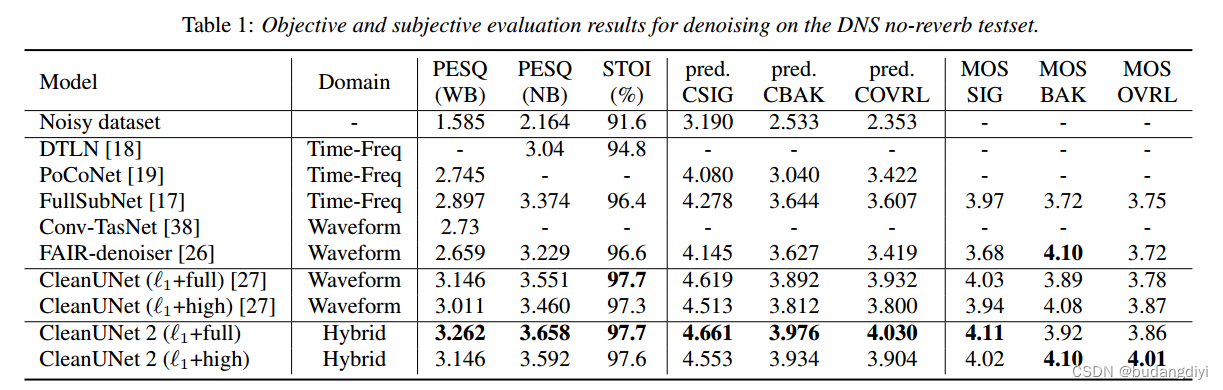
对DNS无混响测试集去噪的客观和主观评价结果。
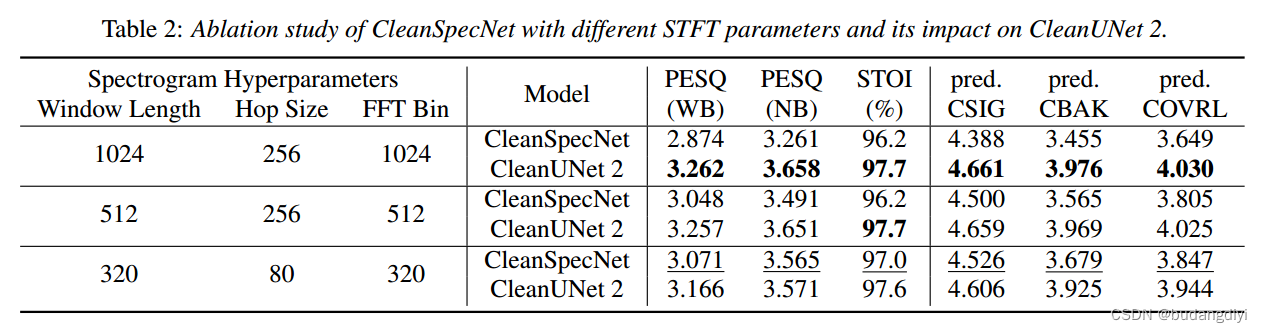
不同窗长和窗移对网络结果的影响。得出三点结论。首先,窗口长度为320的CleanSpecNet本身就是一种极具竞争力的去噪器。其次,CleanUNet 2总是优于CleanSpecNet。第三,发现对于CleanSpecNet,较小的窗口长度和跳跃大小导致更好的质量(见下划线分数),而对于CleanUNet 2则相反。

4.主观评价
六、结论
介绍了一种混合语音去噪模型CleanUNet 2。它首先应用基于频谱图的模型对频谱图进行降噪,然后使用它来调节基于波形的模型(CleanUNet),该模型输出降噪后的波形。对于这两个子模块,作者使用自注意力块来改进表示。在DNS上测试CleanUNet 2;它在客观和主观评价方面都达到了最先进的语音去噪质量。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











