






SVAD: A ROBUST, LOW-POWER, AND LIGHT-WEIGHT VOICE ACTIVITY DETECTION WITH SPIKING NEURAL NETWORKS
第二章 目标说话人提取之《Svad:一个鲁棒、低功耗、轻量级的语音活动检测与尖峰神经网络》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是新加坡国立大学,天津大学,香港中文大学。

一、任务
本文介绍了一种新的基于snn的VAD模型,即sVAD,该模型的特点是听觉编码器具有基于snn的注意机制。
二、动机
脉冲神经网络(snn)在生物学上是合理的,而且节能。
三、挑战
基于snn的VAD在噪声条件下会遭受显著的性能损失。
实现最佳性能通常需要大型SNN模型。
四、方法
1.
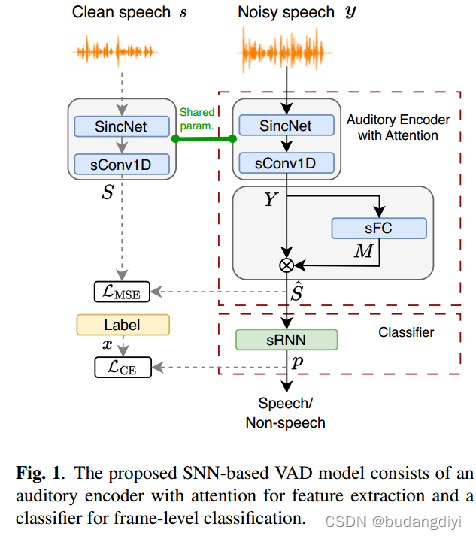
本文提出的基于snn的VAD模型由两个关键组件组成:1)带注意的听觉编码器,将原始音频输入转换为峰值特征帧;2)专门用于逐帧语音活动检测任务的分类器。
2.LIF神经元模型
我们采用广泛认可的Leaky Integrate-and-Fire (LIF)模型[16]来研究尖峰神经元。LIF神经元整合突触输入,直到其膜电位超过放电阈值,导致输出峰传递给后续神经元。LIF神经元的动态由以下离散时间表达式捕获: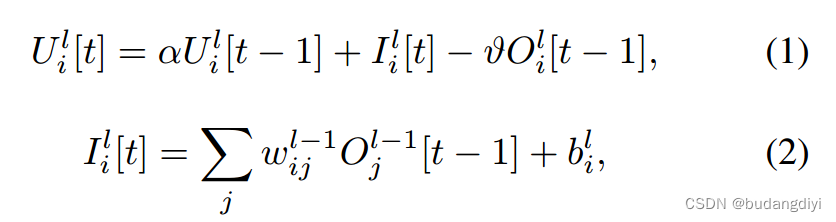
U l i [t]表示神经元i在第l层的膜电位,il i [t]表示t时刻的输入电流。α表示膜电位衰减常数,v表示神经元放电阈值,wl−1 ij表示前一层中神经元j的连接权值,bl I表示注入神经元I的恒电流。输出尖峰的发生,记为oli [t−1],使用尖峰激活函数确定。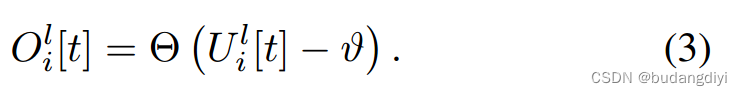
Θ(·)为Heaviside阶跃函数。
3. 具有注意力的听觉编码器
我们的研究利用了成熟的听觉编码器SincNet,该编码器以其出色的特征提取能力而闻名。通过将SincNet集成到我们的听觉编码器中,我们增强了特征提取,提高了基于snn的VAD模型在各种噪声条件下的性能,同时保持了轻量级配置。
一维卷积层引入可训练参数,增强编码器对数据特征的适应性,并通过训练提高性能。受ConvTasNet的启发[17],我们通过在sincnet处理的特征中添加基于snn的1D卷积层(sConv1D)来扩展这种数据驱动能力。这使编码器能够在训练期间优化听觉特征提取。此外,sConv1D输出尖峰,便于将原始音频转换为尖峰表示,用于后续基于snn的处理。
为了增强VAD模型的鲁棒性,特别是在低信噪比条件下,我们引入了一种受人类听觉系统掩蔽效应启发的注意机制。
我们将提取的特征Y置于三层基于snn的全连接(sFC)层中,以得出一个注意掩码M。随后,我们利用这个注意掩码来调制提取的特征,生成被关注的特征。
可训练的三层sFC块优化了不同声学条件下的注意Mask。
4.
为了增强序列建模能力,我们使用带有循环连接的SNN建立分类器,称为sRNN。与前馈处理更新公式(Eq.(2))不同,循环神经元的更新方程包含了一个额外的循环连接项。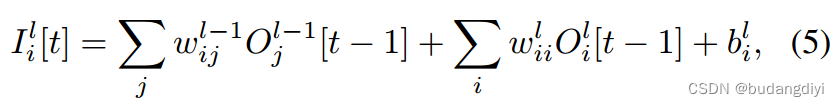
5 损失函数
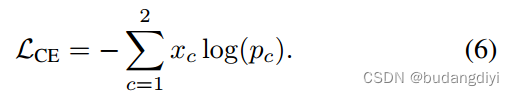
分类损失和注意屏蔽损失。对于分类损失,我们采用交叉熵(CE)。[x1, x2]表示单热编码(语音为[0,1],非语音为[1,0]),pc为输入属于c类的Softmax概率。为了计算注意掩码损失,我们使用均方误差(MSE)。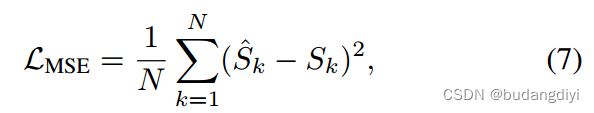
S为干净语音特征,N为特征中元素的总数,k为元素的索引。
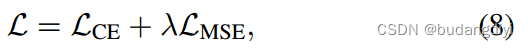
五、实验评价
1.数据集
QUT-NOISETIMIT数据集。该数据集包含600小时的有噪声语音。该数据集将来自TIMIT数据集的干净语音记录与现实世界的噪声场景(如咖啡馆、汽车、家庭、街道和混响环境)相结合。数据集分为三个噪声级别:低(信噪比= +15dB, +10dB),中(信噪比= +5dB, 0dB)和高(信噪比= -5dB, -10dB)。
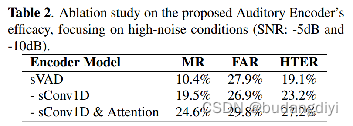
2.消融实验
3.客观评价
我们使用帧级半总错误率(HTER),平均缺失率(MR)和虚警率(FAR)来报告结果。
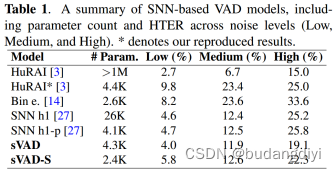
在所有基于snn的模型中,我们的模型对编码器使用最小的帧移(即15ms)(例如,[14]中的20ms),从而产生最低的延迟。
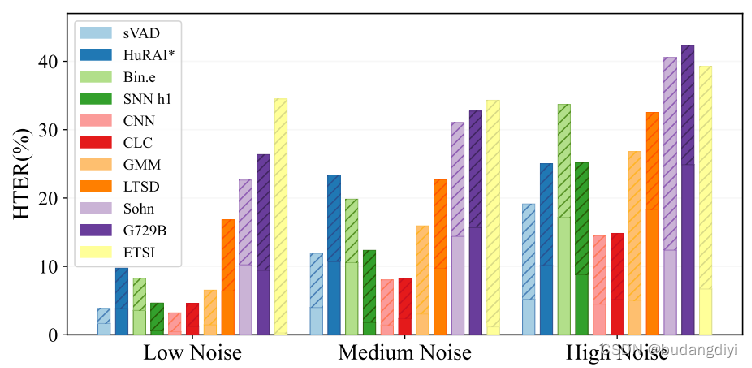
结果表明,除了CNN和CLC模型外,我们的sVAD模型优于大多数模型。这可以归因于CNN和CLC模型使用更大的帧大小和移位来进行决策(与我们的模型相比,CNN的帧大小和移位超过5倍,CLC的帧大小和移位超过3倍),从而增加了延迟。本研究的主要重点是在噪声条件下开发基于snn的鲁棒、低功耗和轻量化VAD模型,而不是追求最高的HTER性能。
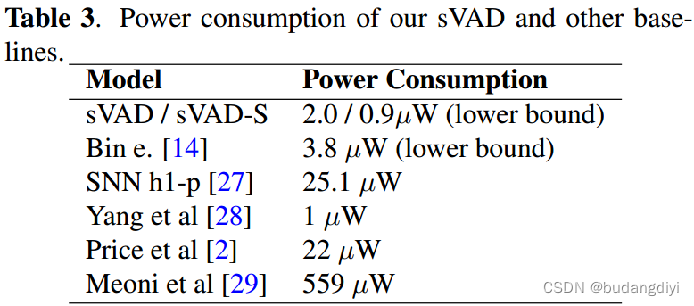
4.主观评价
六、结论
作者开发了一种新的基于snn的VAD模式,该模式包括一个用于特征提取的听觉编码器和一个用于分类的sRNN。实验结果表明,该方法具有噪声鲁棒性好、功耗低、占用空间小等优点。消融研究进一步验证了我们提出的听觉编码器的有效性和鲁棒性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











