






 文章介绍了一种利用即插即用(MVDR)波束形成技术和深度学习先验的语音分离框架,通过降噪正则化整合数据驱动的语音信息,以提升MVDR的性能和鲁棒性。研究者使用预训练的FRCRN模型并进行实验验证,包括数据集WSJ0的评估和客观/主观评价。
文章介绍了一种利用即插即用(MVDR)波束形成技术和深度学习先验的语音分离框架,通过降噪正则化整合数据驱动的语音信息,以提升MVDR的性能和鲁棒性。研究者使用预训练的FRCRN模型并进行实验验证,包括数据集WSJ0的评估和客观/主观评价。
PLUG-AND-PLAY MVDR BEAMFORMING FOR SPEECH SEPARATION
第二章 目标说话人提取之《即插即用的MVDR波束成形语音分离》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是西北工业大学深圳研究院,西北工业大学海洋科学与技术学院,中国工商银行

一、任务
我们提出了一个基于物理的MVDR模型和数据先验的语音分离框架。我们的方法通过结合即插即用(PnP)技术来捕获语音先验,特别是采用降噪正则化(RED)方法将从数据中获得的先验语音信息整合到优化过程中,从而增强了MVDR。
二、动机
MVDR依赖于有关信号角度和协方差矩阵的物理信息,然而,忽略了波束形成器输出可能从语音信号的先前结构中获益。
三、挑战
制作一个有效的正则化器和一个有效的求解方法是非常重要的。
尽管利用深度神经网络强大的非线性建模能力来提取高级特征具有优势,但它们的黑箱性质限制了它们的物理可解释性和泛化性。
尽管依赖于信号角度和协方差矩阵信息的清晰物理解释,但MVDR的性能和鲁棒性有时会达不到预期。
四、方法
1. 问题建模
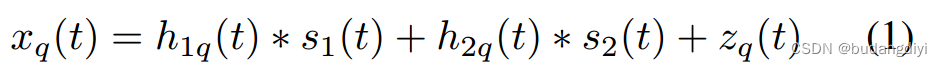
其中s1(t)和s2(t)分别代表两个不同说话人的源语音。h1q(t)和h2q(t)分别为两个声源到第q通道的时不变声学传递函数(atf)。zq(t)表示与语音源无关的零值加性噪声。
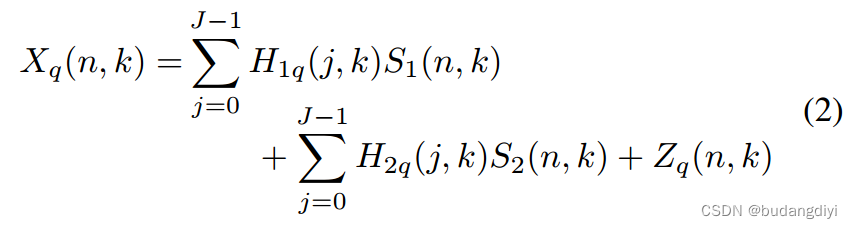
其中n和k分别表示时间框架和频率bin指标。其中J为atf的阶数,Hiq(J;k)和Si(n;K)表示说话人I的hiq(t)和si(t)的对应物。时不变声学传递函数(atf)
如果我们把说话人1作为目标说话人,语音分离的任务就是从麦克风阵列的观察语音中估计S1。考虑到MVDR波束形成过程,我们可以通过以下优化问题寻求目标说话人的最优权向量。
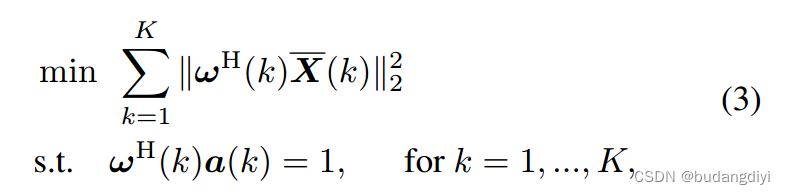
H为矩阵的共轭转置,X(k)为观测值第k波段对应的频谱,a(k)为源1第k波段的方向矢量。
2.提议框架
我们首先将MVDR波束形成的优化问题重新表述为结合深度语音先验,然后给出求解方法。
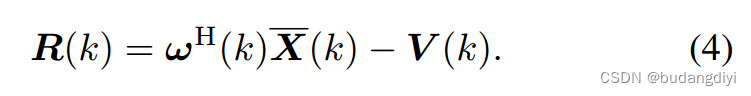
V (k)是建模和处理过程中噪声的估计。R被认为是估计的期望语音信号,因此引入正则化来合并语音先验是有益的。
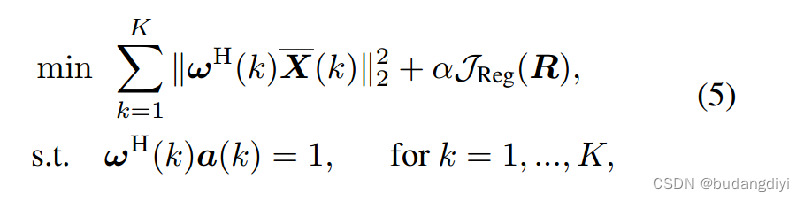
其中α表示权衡参数,JReg是正则化器。我们建议使用PnP策略将数据驱动的语音先验从去噪网络中学习到数学优化过程中。具体来说,我们考虑RED形式的JReg®,它是一种有效的正则化器,以其在温和假设下的良好导数性质而闻名:

Ω(·)表示现成的去噪器。(5)中优化问题的完整形式为:
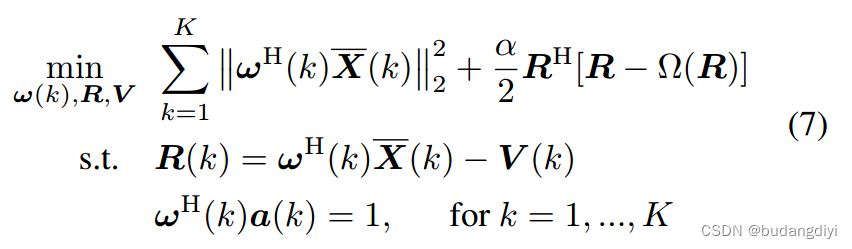
该问题的(缩放)增广拉格朗日函数为:
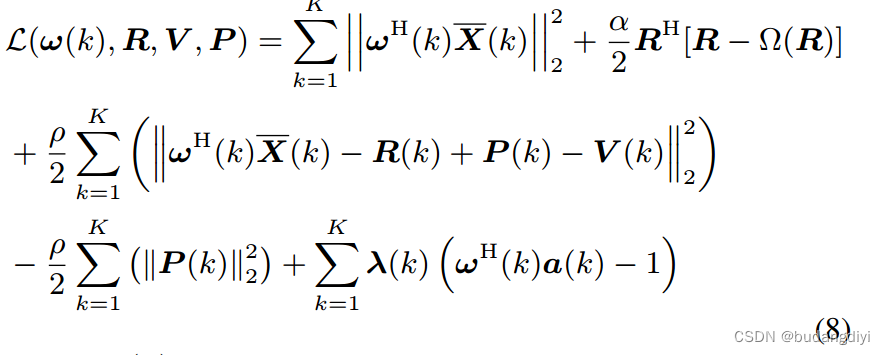
其中P (k)是对偶变量,ρ是惩罚参数,λ(k)表示拉格朗日乘子。通过将方程(8)的优化解耦为几个子问题,这些变量可以通过索引为L的迭代进行优化。
3. 步骤优化
步骤1 -关于w(k)的优化:(8)的优化简化为:
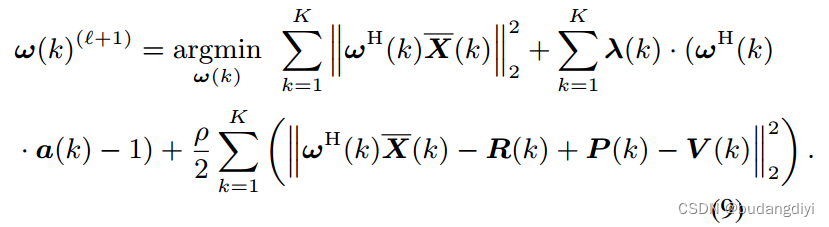
令w(k)和λ(k)的偏导数分别为零,我们可以计算出w(k)的解析解为:
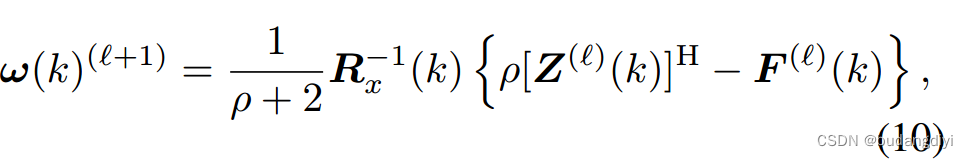
Rx(k) = X(k)X H (k)表示观测值的协方差矩阵,其中
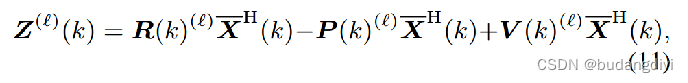
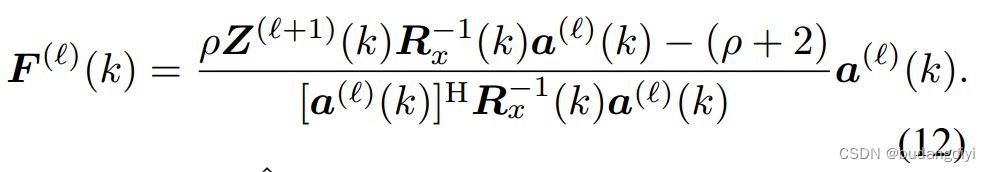
然后,通过计算得到^S:
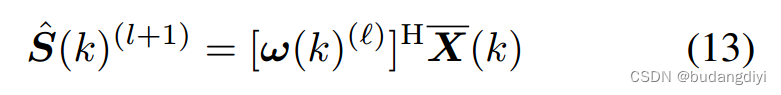
第二步:关于R的优化:优化问题(8)变成:
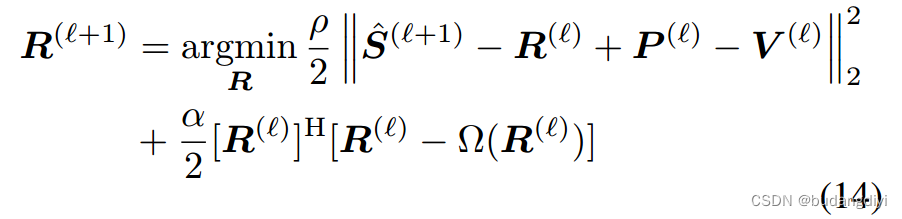
从RED的角度来看,语音先验可以通过对语音^R进行去噪处理而纳入(15)。我们可以通过固定点迭代来解决这个问题:
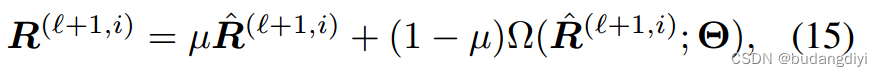
µ为固定点的权衡参数,Θ为去噪器的可学习参数。
步骤3 -关于V的优化:
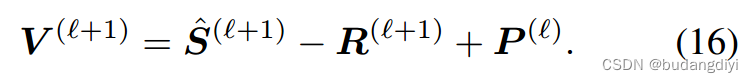
步骤4 -更新P:
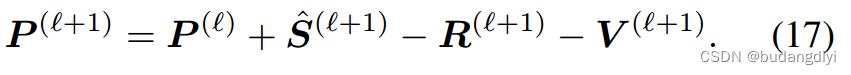
算法1总结了具有数据先验的MVDR的PnP框架,将输出R视为估计的目标语音。

输入:观察到的多通道语音:X
输出:预测语音:R
参数:内部迭代:I;变量分裂法的惩罚参数:ρ;定点算法参数:µ
初始化:辅助变量:V = 0K×N;双变量:P = 0K×N;预测的过滤器权重向量:w(k) = 0Q×1。
4.实验
在这里,为了专注于这项工作的主要思想,我们直接使用预训练的基于dnn的去噪器,称为频率递归卷积递归网络(FRCRN)。该模型采用卷积循环编码器-解码器架构来预测目标语音的复杂理想比例掩模,使网络能够学习远程频率相关性并增强语音输入的特征表示。
五、实验评价
1.数据集
WSJ0
2.消融实验
3.客观评价

频域加权分割信噪比(fwSNRseg)
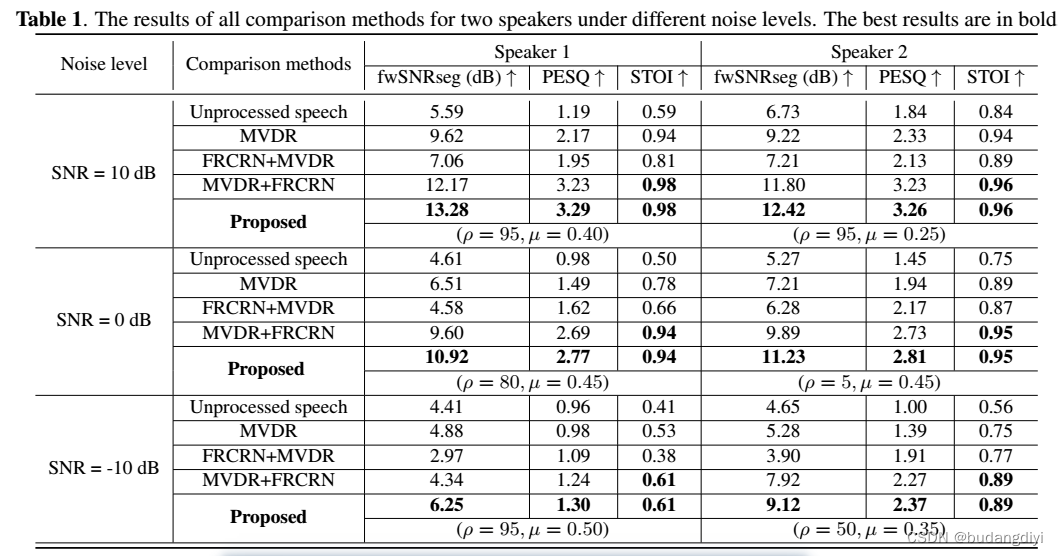
4.主观评价
六、结论
本文提出了一种利用数据驱动语音先验来提高MVDR波束形成性能的新方法。为了实现这一点,我们采用了一种基于变量拆分方法的即插即用(PnP)策略,特别是利用RED策略。我们将预训练的FRCRN模型集成到优化过程中,以有效地捕获语音先验。


















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











