







作业内容介绍
首先分享找到的关于作业2的说明PDF和主教给的例程。
链接:https://pan.baidu.com/s/1kyCebLz010LDPw-CH6oOyQ
提取码:ne5o
其中.ipynb文件用Jupyter Notebook打开,阅读比较方便。
下面的链接是作业中用到的数据集:
链接:https://pan.baidu.com/s/1HpXeECc1ay_a2FP76SaX4w
提取码:mneu
然后放上助教对本次课程要求的讲解视频链接:李宏毅2020机器学习配套作业讲解 https://www.bilibili.com/video/BV1ug4y187eg
一句话就是用每个月20天的数据作为训练集,以9小时数据作为输入,求第10小时的PM2.5值。
完整程序
废话不多说,先上完整程序。然后再逐步解释,这个程序是纯手刻~不过注释较少,在本文档进行细致解释。

import sys
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
# import os
data = pd.read_csv('../data/hw1/train.csv', encoding='big5')
data = data.iloc[:, 3:]
# print(data.dtypes)
data[data == 'NR'] = 0
raw_data = np.array(data)
print("data_infomation", raw_data.shape, raw_data.ndim, raw_data.size)
# private_data = pd.read_csv('../data/hw1/test.csv', encoding='big5')
# private_data = private_data.iloc[:, 2:]
# private_data[private_data == 'NR'] = 0
# test_data = np.array(private_data)
def data_set(data_s, days=20, hours=24, ts_size=1000): # 将数据整理为5652个样本和labels,其中每个样本有18*9=162个features!分出ts_size个public
month_data = np.empty([12, 18, 24*20])
all_data3 = np.empty([24*20-9, 18*9])
all_labels2 = np.empty(24*20-9)
all_data_ds = np.empty([12*471, 162])
all_labels_ds = np.empty(12*471)
for month_ds in range(12):
for day_ds in range(days):
month_data[month_ds, :, day_ds*24:24*(day_ds+1)] = data_s[18*day_ds+month_ds*360:18*(day_ds+1)+month_ds*360, :]
month_data = np.swapaxes(month_data, 1, 2)
# print(month_data.shape) #shape:(12, 480, 18)
for month_ds in range(12):
index_1 = random.sample(range(hours*days-9), hours*days-9)
for times_ds in range(hours*days-9):
all_data3[index_1[times_ds], :] = month_data[month_ds, times_ds:times_ds+9, :].flatten()
all_labels2[index_1[times_ds]] = month_data[month_ds, times_ds+9, 9]
all_data_ds[month_ds*471:471*(month_ds+1), :] = all_data3
all_labels_ds[month_ds*471:471*(month_ds+1)] = all_labels2
# print(all_data.shape) # shape: (5652, 162)
# print(all_labels.shape) # shape: (5652,) ndim:1
train_data_ds = all_data_ds[:(-ts_size), :]
train_labels_ds = all_labels_ds[:(-ts_size)]
public_data_ds = all_data_ds[(-ts_size):, :]
public_labels_ds = all_labels_ds[(-ts_size):]
return all_data_ds, all_labels_ds, train_data_ds, train_labels_ds, public_data_ds, public_labels_ds
def train(train_data_tr, train_labels_tr, model_id, learning_rate=0.000001, epochs=1000): # learning_rate=0.000001
w_tr = np.zeros([162])
b_tr = np.zeros([1])
loss_str = np.empty([epochs])
loss_tr = 11
if model_id == 1:
for epoch in range(epochs):
train_y_tr = np.dot(train_data_tr, w_tr) + b_tr
# print(train_y_tr.shape)
loss_tr = np.sqrt(np.sum(np.power(train_y_tr - train_labels_tr, 2)/len(train_labels_tr)))
loss_str[epoch] = loss_tr
# print(loss_tr)
gradient_w_tr = np.dot(train_data_tr.T, train_y_tr - train_labels_tr)/len(train_labels_tr)
gradient_b_tr = np.sum(train_y_tr - train_labels_tr)/len(train_labels_tr)
# print(gradient_tr)
w_tr = w_tr - learning_rate * gradient_w_tr
b_tr = b_tr - learning_rate * gradient_b_tr
# print(w_tr)
weights_tr = np.append(w_tr, b_tr)
train_y_tr = np.dot(train_data_tr, weights_tr[:-1]) + weights_tr[-1]
else:
if model_id == 2:
loss_tr = 100
weights_tr = np.append(w_tr, b_tr)
train_y_tr = 0
loss_m_tr = 100
if loss_tr < 10:
np.savetxt('./model/' + str(model_id) + '.txt', weights_tr)
loss_m_tr = np.abs(np.mean(train_y_tr - train_labels_tr))
return weights_tr, loss_str, loss_m_tr
def test(test_data, test_labels, test_weights):
test_y_ts = np.dot(test_data, test_weights[:-1]) + test_weights[-1]
loss_ts = np.abs(np.mean(test_y_ts - test_labels))
return loss_ts, test_y_ts
def main():
model_id = 1
# weights_way = 1
train_run = 2
_, _, train_data, train_labels, public_data, public_labels = data_set(raw_data)
# print(train_data.shape) # shape: (4652, 162)
# print(train_labels.shape) # shape: (4652,)
# print(public_data.shape) # shape: (1000, 162)
# print(public_labels.shape)
if train_run == 1:
weights, loss_s, loss_m = train(train_data, train_labels, model_id)
plt.plot(loss_s)
plt.show()
print('loss_train:', loss_m)
else:
weights = np.loadtxt('./model/' + str(model_id) + '.txt')
loss_p, pub_y = test(public_data, public_labels, weights)
print([pub_y[0], public_labels[0]])
# plt.figure()
print('loss_public:', loss_p)
return
main()
# data_infomation (4320, 24) 2 103680
# loss_train: 0.056446422682213414
# [29.45807011378206, 36.0]
# loss_public: 1.988317542207781
程序分段描述
加载库文件
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plt
主要用到以上几个库,都是比较常用的库,由于是手刻,没有用到任何框架。
数据导入及预处理
data = pd.read_csv('../data/hw1/train.csv', encoding='big5')
data = data.iloc[:, 3:]
# print(data.dtypes)
data[data == 'NR'] = 0
raw_data = np.array(data)
print("data_infomation", raw_data.shape, raw_data.ndim, raw_data.size)
# data_infomation (4320, 24) 2 103680
这段是加载train_data,其中,由于无雨的数据为NR,将其替换为0。
数据整理数据集建立
这段读入train数据,数据为 4320行×24h列。其中4320行为18features×240days,240days为12months×20days。
所以,我们应该先将数据进行整理18行×(24h240d)=18行×5760列,如图所示。
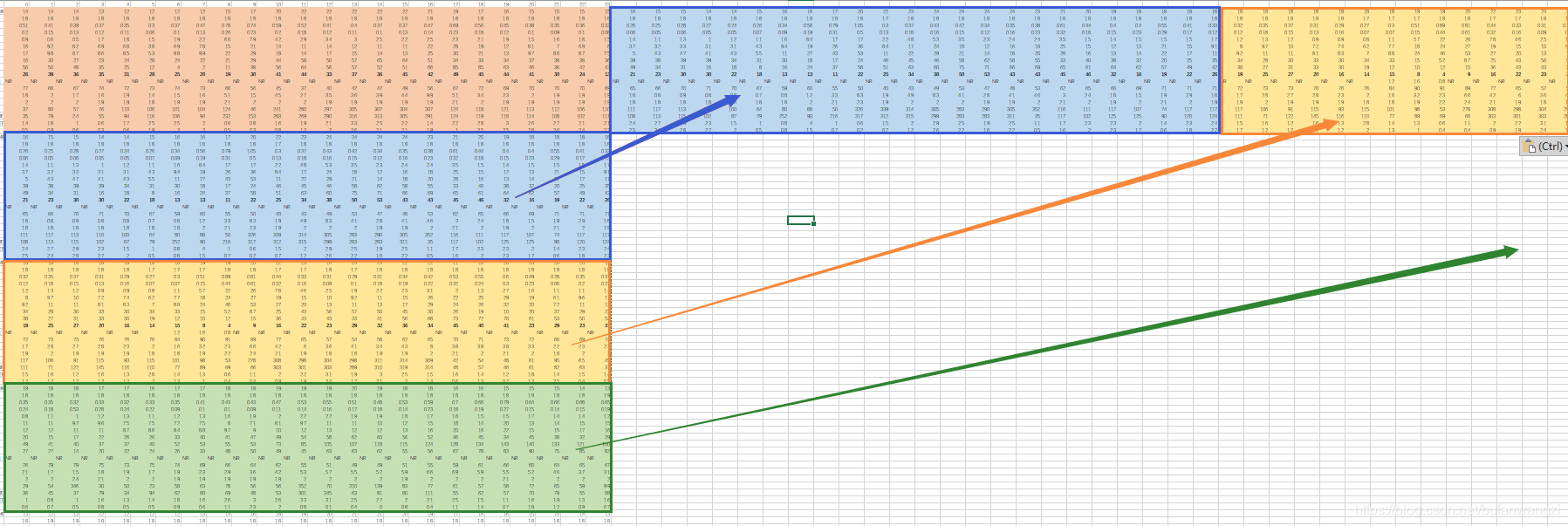 这里有一个问题,就是数据为每月取连续20天,但是两月之间是不连续的,所以不能直接用480天连续取数据,只能分12份,每份20天连续取数据,每份20天24hours,即连续480小时,所以模型输入的连续的9小时包含前一天的最后几小时和次日的前几小时的连续,这样可以丰富我们的训练数据集。而且这样有助于对凌晨PM2.5的估计准确度。如图所示。这样每10个连续小时数据即构成了一组data和label。也就是每份数据480hours,可构成471组数据和标签,每个数据包含189=162个features。
这里有一个问题,就是数据为每月取连续20天,但是两月之间是不连续的,所以不能直接用480天连续取数据,只能分12份,每份20天连续取数据,每份20天24hours,即连续480小时,所以模型输入的连续的9小时包含前一天的最后几小时和次日的前几小时的连续,这样可以丰富我们的训练数据集。而且这样有助于对凌晨PM2.5的估计准确度。如图所示。这样每10个连续小时数据即构成了一组data和label。也就是每份数据480hours,可构成471组数据和标签,每个数据包含189=162个features。
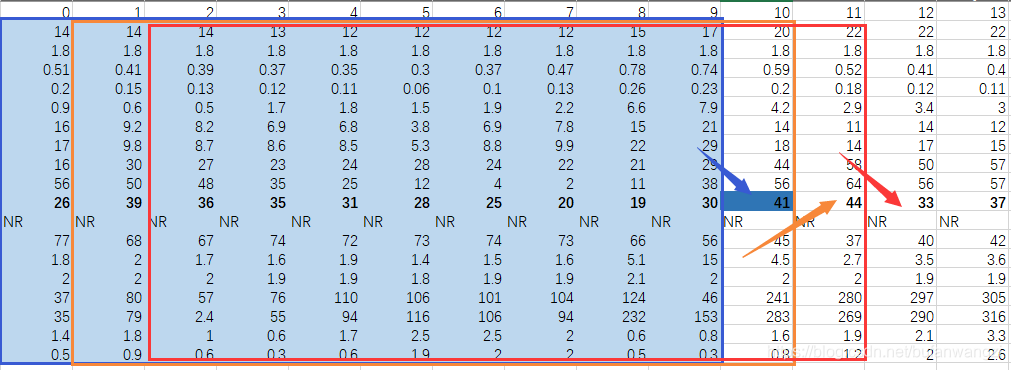 进一步为了取用方便,避免12份数据之间有差别,我又将12份数据整理为一份,将189整理为1列162行,最终数据格式为:5652,162,对应有5652个标签。
进一步为了取用方便,避免12份数据之间有差别,我又将12份数据整理为一份,将189整理为1列162行,最终数据格式为:5652,162,对应有5652个标签。
下边程序中 ts_size为将train data分出一部分做测试用的数量,默认为1000个,也就是,用4652组数据做训练,1000组数据做测试。是最终的输出数据。
def data_set(data_s, days=20, hours=24, ts_size=1000): # 将数据整理为5652个样本和labels,其中每个样本有18*9=162个features!分出ts_size个public_test_data
month_data = np.empty([12, 18, 24*20])
all_data3 = np.empty([24*20-9, 18*9])
all_labels2 = np.empty(24*20-9)
all_data_ds = np.empty([12*471, 162])
all_labels_ds = np.empty(12*471)
for month_ds in range(12):
for day_ds in range(days):
month_data[month_ds, :, day_ds*24:24*(day_ds+1)] = data_s[18*day_ds+month_ds*360:18*(day_ds+1)+month_ds*360, :]
month_data = np.swapaxes(month_data, 1, 2)
# print(month_data.shape) #shape:(12, 480, 18)
for month_ds in range(12):
index_1 = random.sample(range(hours*days-9), hours*days-9)
for times_ds in range(hours*days-9):
all_data3[index_1[times_ds], :] = month_data[month_ds, times_ds:times_ds+9, :].flatten()
all_labels2[index_1[times_ds]] = month_data[month_ds, times_ds+9, 9]
all_data_ds[month_ds*471:471*(month_ds+1), :] = all_data3
all_labels_ds[month_ds*471:471*(month_ds+1)] = all_labels2
# print(all_data.shape) # shape: (5652, 162)
# print(all_labels.shape) # shape: (5652,) ndim:1
train_data_ds = all_data_ds[:(-ts_size), :]
train_labels_ds = all_labels_ds[:(-ts_size)]
public_data_ds = all_data_ds[(-ts_size):, :]
public_labels_ds = all_labels_ds[(-ts_size):]
return all_data_ds, all_labels_ds, train_data_ds, train_labels_ds, public_data_ds, public_labels_ds
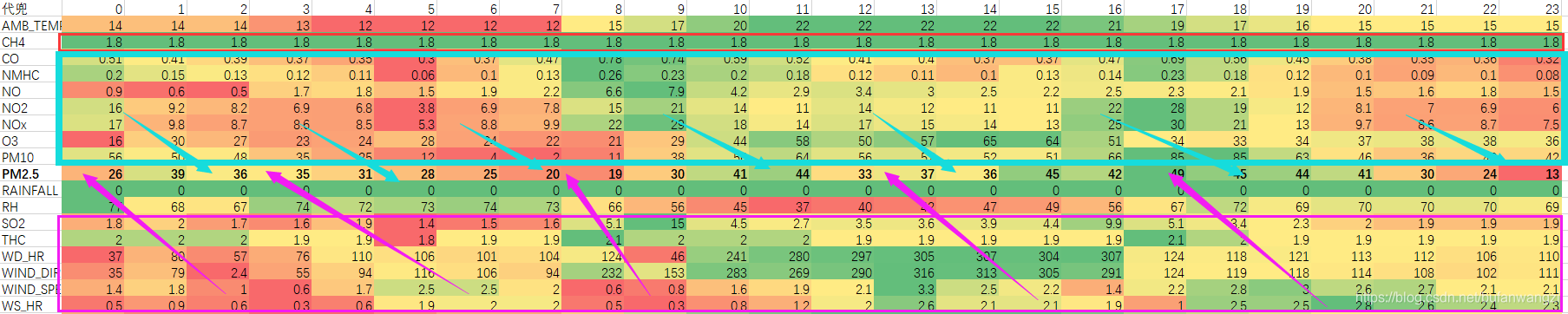
以上,对数据其实还有额外的一些思考,如下图所示,对每行数据进行色阶排序,可以看出数据之间的大致相关程度,这对我们在建立预测模型时选择那些特征是有帮助的。可以看出,CH4这一项,在几乎每天的任何时候都没有什么变化,或者变化0.1,对预测基本没有什么影响,所以,这条数据不应该作为输入特征。
还有,从趋势来看,PM2.5上方的几个测试项目的数据变化基本都优先于PM2.5的变化,这样的特征往往可以用来预测未来PM2.5的变化,我会将他们作为输入特征,而PM2.5下方的几个参数似乎都滞后于PM2.5的变化,或者时远远优先,具体还没搞清楚,在进行模型简化优化时,我会优先将它提出作为尝试。以上仅为个人理解,本次程序将全部162个特征都塞入模型,让它自己去分析吧,这个想法会在后续再进行尝试。
训练过程
训练过程主要是建立模型,初始化参数,然后进行迭代。
迭代过程中,每次运算将全部数据与模型进行一次计算,得到每个数据的损失,计算平均损失,以平均损失对参数进行梯度下降调整,1000次迭代后,得到训练结果。即为参数值。
这里梯度下降过程需要求偏导,需要补充一些公式。
def train(train_data_tr, train_labels_tr, model_id, learning_rate=0.000001, epochs=1000): # learning_rate=0.000001
w_tr = np.zeros([162])
b_tr = np.zeros([1])
loss_str = np.empty([epochs])
loss_tr = 11
if model_id == 1:
for epoch in range(epochs):
train_y_tr = np.dot(train_data_tr, w_tr) + b_tr
# print(train_y_tr.shape)
loss_tr = np.sqrt(np.sum(np.power(train_y_tr - train_labels_tr, 2)/len(train_labels_tr)))
loss_str[epoch] = loss_tr
# print(loss_tr)
gradient_w_tr = np.dot(train_data_tr.T, train_y_tr - train_labels_tr)/len(train_labels_tr)
gradient_b_tr = np.sum(train_y_tr - train_labels_tr)/len(train_labels_tr)
# print(gradient_tr)
w_tr = w_tr - learning_rate * gradient_w_tr
b_tr = b_tr - learning_rate * gradient_b_tr
# print(w_tr)
weights_tr = np.append(w_tr, b_tr)
train_y_tr = np.dot(train_data_tr, weights_tr[:-1]) + weights_tr[-1]
else:
if model_id == 2:
loss_tr = 100
weights_tr = np.append(w_tr, b_tr)
train_y_tr = 0
loss_m_tr = 100
if loss_tr < 10:
np.savetxt('./model/' + str(model_id) + '.txt', weights_tr)
loss_m_tr = np.abs(np.mean(train_y_tr - train_labels_tr))
return weights_tr, loss_str, loss_m_tr
测试函数
测试函数就是将刚刚从总的train data中分出来的数据输入到得到的模型中,看预测结果的偏差值。
def test(test_data, test_labels, test_weights):
test_y_ts = np.dot(test_data, test_weights[:-1]) + test_weights[-1]
loss_ts = np.abs(np.mean(test_y_ts - test_labels))
return loss_ts, test_y_ts
main函数
这里边定义了几个自己的调试参数,model_id 是模型类型,当前为1,就是基础模型,一维线性模型。162个特征全部考虑的模型。之后会增加不同数据分别尝试的模型。
train run是是否重新进行训练,还是直接调用保存的训练模型参数,直接进行测试。
def main():
model_id = 1
# weights_way = 1
train_run = 1
_, _, train_data, train_labels, public_data, public_labels = data_set(raw_data)
# print(train_data.shape) # shape: (4652, 162)
# print(train_labels.shape) # shape: (4652,)
# print(public_data.shape) # shape: (1000, 162)
# print(public_labels.shape)
if train_run == 1:
weights, loss_s, loss_m = train(train_data, train_labels, model_id)
plt.plot(loss_s)
plt.show()
print('loss_train:', loss_m)
else:
weights = np.loadtxt('./model/' + str(model_id) + '.txt')
loss_p, pub_y = test(public_data, public_labels, weights)
print([pub_y[0], public_labels[0]])
# plt.figure()
print('loss_public:', loss_p)
return














 9708
9708











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









