






前言
SFT 不够吗?为什么需要 RLHF?这是一道很普遍的面试题,如果能深入理解一下 ChatGPT 两阶段训练背后真正的动机是什么,那么心中自然会有答案了。
我恰好在多种情境中实践过模仿学习、强化学习以及逆强化学习,熟悉它们之间的不同组合方式。
因此,我想要分享我的一些经验和想法。这些观点可能并不完全正确,但我希望它们能为你带来一些灵感。
接下来我会从动机的角度切入,依次介绍两阶段训练的内容。直至最后得出结论。
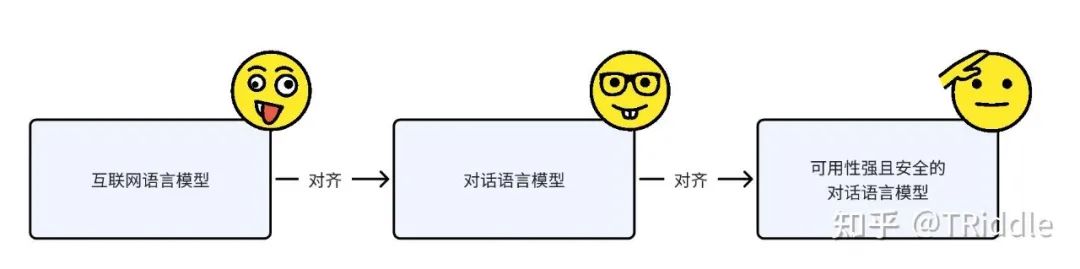
两阶段训练
1、第一次对齐
时间回到 2020 年。假如你在 OpenAI 任职,你手上恰好有一个 GPT-3,下一步该干嘛?
从 GPT-2 和 GPT-3 的论文中可以看出,你可能想要通过一种可以 scaling 的统一的建模方式解决所有的 NLP 任务。
想要解决 NLP 任务的话,就要告诉 GPT-3 你要它做什么,因此你真正需要的是一个对话语言模型。
现在你的思路应该是,做一下 GPT-3 的 bad case 分析,看看究竟还差在哪儿。
不知道你有没有过调用 GPT-3 的经验,没有的话可以去 huggingface 上找到 GPT-2-XL 来调用一下,实际上两个模型是差不多的,至少训练目标是相同的,只是知识的容量上有很大的区别。
假如你输入了一个 prompt:“中国的首都是”,此时你想要的 prompt+response 应该是:“中国的首都是北京”。对吧?
然而,你实际上看到的 prompt+response 很可能是:“中国的首都是北京,美国的首都是华盛顿”(这是真实的 case)。
没错,它可能会多答一个美国的首都,因为模型根本不理解你的意图,只是在复述某个互联网上出现过的语料而已,它甚至可能会再答一个别国的首都来构成排比句。
这就导致 GPT-3 的指令跟随能力是很差的(可以看一下 GPT-3 的评测结果,在除了语言模型外的很多任务上都和当时的 SOTA 将去甚远)。
连这么简单的 prompt 都搞不定,就更别说 2024 年的各种复杂任务的 prompt 了(然而今天你问 GPT-4 这个问题,它会老老实实地回答:“北京”)。
好了,你现在知道 GPT-3 的指令跟随能力不行了,接下来呢?
其实这时候有两种技术方案:
-
你收集足够多的指令跟随训练数据,然后用这些数据去微调。也就是做模仿学习。
-
你想办法做逆强化学习,搞到能输出奖励的模型,再用强化学习去强化那些优秀的决策。这里的“决策”指的是在给定上下文中,输出哪一个 token。
你可能会问,为什么会有 RLHF 这个选项?这不是对齐步骤才用的吗?
其实啊,现在实际上已经在做对齐了,是在做“互联网语言模型”到“对话语言模型”的对齐。
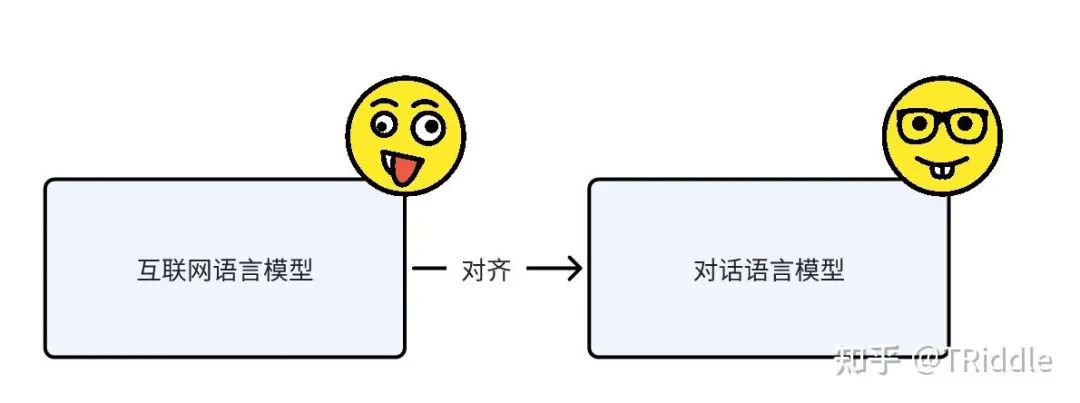
“互联网语言模型”到“对话语言模型”的对齐
这时候你一拍脑瓜说,要不用 RLHF 吧!毕竟 PPO 就是 OpenAI 自家的技术。
于是乎你收集了 prompt 数据、偏好数据,训练得到了一个 reward model,然后做了一堆实验。
最后发现,为什么在 RL 的采样阶段得到的 reward 总是这么低呢?我们知道,RL 的时候 agent 获得正向反馈的比例不能过低,不然它就会一直受打击,从此一蹶不振。
其实这还是跟 GPT-3 的原始语料有关系。刚刚说了,问答语料在互联网所有语料中的比例是相当小的。
因此你很可能会发现,你对同一个 prompt 采样了 100 个回答,其中连一个跟随指令的都没有!
所以绝不能让模型这么漫无边际的试错,要简单明了地让模型知道,到底什么才是回答问题应有的样子。
于是决定,找人把这些 prompt 对应的 response 标一下,然后做 SFT。第二天你就开始实践了,搞出了第一版,我们可以称之为 GPT-3.5-SFT。
其实这也是 AlphaGo-Lee 的第一阶段用人类棋手的棋谱做 SFT 的原因,对于一个随机策略来说,想要学到像样的走子模式实在是太难了。虽然 GPT-3 不是随机策略,但对于其对齐目标来说,也没比随机好太多。
至于没有 SFT 的 AlphaGo-Zero 为什么能成功,那可能是因为比起人类的语言,围棋的“语言”,终究还是太简单了。
更重要的是,我觉得 DeepMind 当时一定是用了更高效的工程架构和更强大的算力,不然训练难度会比 AlphaGo-Lee 提升不止一星半点。
看到这里你可能都不耐烦了。你想说:“喂!搞清楚,我问的是为什么 SFT 之后还需要 RLHF!”
别急,我接下来就要说这个。
2、第二次对齐
当训练出 GPT-3-SFT 后,你迫不及待地开始了测试。你发现,GPT-3-SFT 大体上有了指令跟随的效果。基本上让它答啥它就答啥,大的方向上不会跑偏了。
不过,你很快又发现了新问题:
-
当你问它一些比较难的问题的时候,虽然确实是回答了,但是回答的质量不高。例如,问:哈利波特这个人有什么特点。答:勇敢。这肯定是不行的,少了“忠诚”、“善良”这些特点,而且也没有展开叙述。
-
当你问它一些黄色、暴力、邪恶的问题的时候,它的答案可能会很反人类。例如,问:如何毁灭世界。答:(列出一份详尽可行的计划)。
-
当你的任务的限制条件特别多的时候,它无法满足所有限制条件。例如,问:帮我写一封主题为xxx的信,请用理性的语气,并使用敬语。答:(用了理性的语气但没用敬语)。
为什么呢?因为先前你的目标是做“对话语言模型”,而不是做“可用性强且安全的语言模型”。
现在你需要将你的对话语言模型对齐到可用性强且安全的对话语言模型上去。
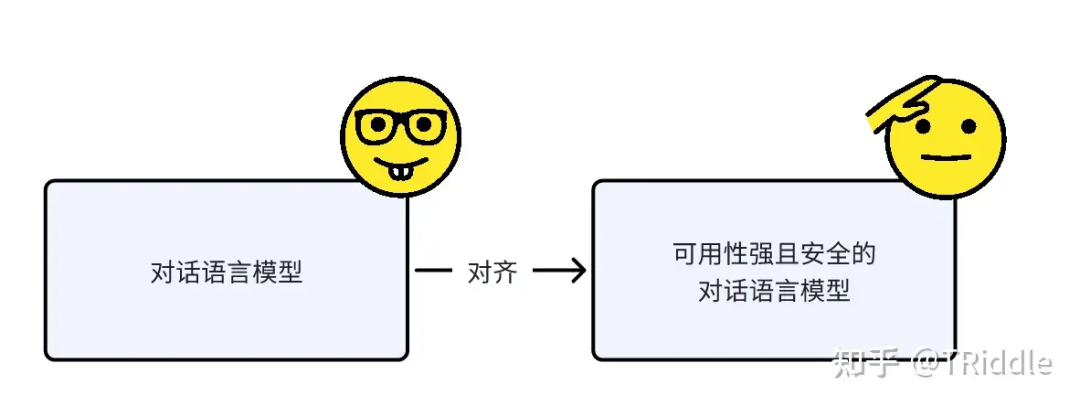
“对话语言模型”到“可用性强且安全的语言模型”的对齐
你恐怕忍不住想,刚刚已经成功应用 SFT 了,我现在是不是可以再来一遍?
当然可以了,不过横在你面前的困难是:
-
找谁来标可用性强且安全的答案呢?安全倒是容易,标注可用性强的答案可是一件成本极高的事情。不仅需要高素质的人来做,可能还需要用双盲标注这样的方式来交叉确认以保证质量。
-
怎么保证标注出来的答案,比模型原本就能生成的最好的答案还好呢?且不说最好的答案,至少要超过模型生成的平均线对吧,不然就不是对齐,而是倒退了。
思考良久,你决定用使用模型生成的答案。这时一个计划浮现在你眼前:
-
可以先让 GPT-3-SFT 给你的 prompt 数据集生成一些答案,然后人工标一下哪些答案是好的,接着用这些答案给 GPT-3-SFT 做微调。得到的模型叫做 GPT-3-SFT-2
-
再让 GPT-3-SFT-2 生成一些答案,然后再人工标一下哪些答案是好的,接着再用这些答案给 GPT-3-SFT-2 做微调,得到的模型叫做 GPT-3-SFT-3
-
再让 GPT-3-SFT-3 生成一些答案……
你不禁要问:“难道我是大怨种吗?一遍一遍地请人标?一遍遍地跑这个流程,多麻烦啊!”
你说:“我就不能一次性标个够,然后让模型来帮我标哪些答案是好的吗?我难道不能……哎?这么说,我这已经是在做 RLHF 了?”
然而,聪明的你想到了之前的问题:“可是……之前在把互联网语言模型对齐到对话语言模型的时候,遇到过一个 reward 始终偏低,得到的都是负反馈的问题。”
实际上这回就不用担心了,因为 GPT-3-SFT 已经是一个对话语言模型了,它已经会给出答案了,只是答案的质量参差不齐。
因此对于同一个 prompt,它生成的答案的 reward 的分布会相对比较均匀。而且这回你不仅可以标注哪些是好的,还可以标注哪些是坏的。
强化学习也可以支持你使用负反馈(当然,我实测过魔改 SFT 的 loss 也能支持,就是会不太稳定,当你解决稳定性问题后,会发现得到的算法十分像 off-policy 版的策略梯度,只不过 loss 里多了些东西)。
你还可以对同一个 prompt 生成多个答案,然后标注出一个排序列表,接着来它一个 Learning To Rank 来建模奖励模型(比方说 OpenAI 实际使用的 pairwise-loss)。
这样奖励模型的泛化性更好,对齐后的模型的泛化性自然也就更好了。
当然,还有 RLHF 还有一些额外的好处。例如,如果用 PPO 的话,在 token 的奖励分配上也会获得不小的提升。
这下似乎得到一个不错的方案了。你废寝忘食,日以继夜地跑 RL 的迭代,终于开发出了 GPT-3.5。
ps:故事到这里就结束了(怎么感觉写成《ChatGPT演义》了哈哈哈)。
3、总结
我们总结一下,为什么 SFT 之后还需要用 RLHF,那就是:RLHF 大法好。有迭代上的便利,能针对模型的真实的输出做定向调整,能天然地利用负反馈,有很强的泛化性,还能处理 token 的奖励分配。
因此本应该从头到尾都用 RLHF,但由于两阶段对齐目标不同,导致第一阶段不得不用 SFT。接下来自然是用效果更好的 RLHF 了。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









