







4-1:Feasibility Of Learning
机器学习的可行性,可能有一个很upset的事情是机器学习可能是不行的,为什么?因为你能确保在数据Data中g满足要求,但是数据外或者进行预测呢?g可能和实际的f差很远。
4-2:Probability to the rescue
补救是有可能性的。
在概率论与数理统计中中,我们做过用样本估计总体的试验,假设有一罐球,如下图所示:

罐子里有绿色和橙色两种玻璃球,假设橙色球的比例是u,那么绿色球的比例肯定是1-u,那么我们如何确定u的数值大小呢?
我们从罐子里取出一堆球,统计橙色球的比例并记为v,那么我们可以用v来近似代替u,因为罐子是被搅拌过的,随机抽取的球满足一般性,可以用样本估计总体。
或者从另外一个角度,即由Hoeffding’s Inequality(霍夫丁不等式)来定量的进行分析。公式如下:
p[|v−u|>ξ]≤2exp(−2ξ2N)
从公示可以看出,随着样本数目N的增多,p变得越来越小,随着
ξ
的增大,p的概率也越来越小,表明v和u的差距越大,概率越小,由Hoeffding’s Inequality可以得出,v和u是相等的这一事件是PAC(Probably Approximately Correct)大概对的。并且N足够大时,
u≈v
。
4-3:Connection to Learning
上一节中罐子小球和机器学习的关系对比如下表:
| bin(罐子) | ML |
|---|---|
| 未知橙色小球比例u | 假设h(x)是否等于目标f(x) |
| 抽取的样本 ∈罐子 | 输入数据x ∈ 总体数据集X |
| 橙色小球 | h(x)是错误的即h(x) ≠ f(x) |
| 绿色小球 | h(x)是正确的即h(x) = f(x) |
| N个样本是从罐子里抽取的 | 输入数据集是从总体数据集随机抽取的 |
由对比可以看出,
我们引入两个记号
Ein
和
Eout
分别代表样本错误率和整个输入数据集的错误率,对于固定的hypothesis,其中,
Ein(h)=1N∑Nn=1[h(x)≠f(x)]

Eout
是未知的,但是
Ein
是已知的,由Hoeffding’s Inequality得知,我们可以用
Ein
来估计
Eout
,即
p[|Ein−Eout|>ξ]≤2exp(−2ξ2N)
,并且当N很大时,
Ein
和
Eout
相等的事件是PAC的。
4-4:Connection to Real Learning
通过第三节,我们可以用
Ein
来估计
Eout
,那么就是要找到一个hypothesis使得
Ein
很小,这样子就会使得
Eout
错误率更低,h和f在整个输入空间就会越接近。但是事实上这样子做会出现问题。
我们以抛硬币为例进行说明,假设有150个人抛硬币,每个人连续抛5次,则一个人抛到5次正面的概率是
132
,那么至少有一个人抛到全部正面的概率是
p=1−(132)150>0.99
的,那么如果选到了5次全正面的那个人作为sample,也就是相当于选到了bad data(坏的数据),然后就会说我的
Ein=0
啊,但是实际上
Eout=132
,这样子是
Ein
和
Eout
就差的比较大。为什么会出现这种情况呢?
Hoeffding’s Inequality告诉我们的是抽到坏数据的概率很小,如下图中:

如果单个假设来看,抽到坏数据的可能性确实特别小,但是当hypothesis增多时,就像150个人抛硬币,最后抽到一个人5次正面朝上的概率>0.99,下面计算一下这个概率:
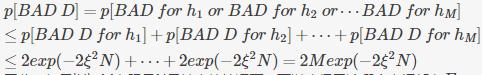
因此,如果|H|=M有限且N足够大的情况下,可以确保无论哪个空间都有
Eout≈Ein
。如果通过算法找到g,使得
Ein(g)=0
,那么根据PAC,相应的
Eout(g)=0















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









