







1、检查单词是否为句中其他单词的前缀(3分)
问题描述
给你一个字符串sentence作为句子并指定检索词为 searchWord,其中句子由若干用 单个空格 分隔的单词组成。
请你检查检索词searchWord是否为句子sentence中任意单词的前缀。
- 如果
searchWord是某一个单词的前缀,则返回句子sentence中该单词所对应的下标(下标从1开始)。 - 如果
searchWord是多个单词的前缀,则返回匹配的第一个单词的下标(最小下标)。 - 如果
searchWord不是任何单词的前缀,则返回-1。
字符串S的 「前缀」是S的任何前导连续子字符串。
示例 1:
输入:sentence = "i love eating burger", searchWord = "burg"
输出:4
解释:"burg" 是 "burger" 的前缀,而 "burger" 是句子中第 4 个单词。
示例 2:
输入:sentence = "this problem is an easy problem", searchWord = "pro"
输出:2
解释:"pro" 是 "problem" 的前缀,而 "problem" 是句子中第 2 个也是第 6 个单词,但是应该返回最小下标 2 。
示例 3:
输入:sentence = "i am tired", searchWord = "you"
输出:-1
解释:"you" 不是句子中任何单词的前缀。
示例 4:
输入:sentence = "i use triple pillow", searchWord = "pill"
输出:4
示例 5:
输入:sentence = "hello from the other side", searchWord = "they"
输出:-1
提示:
1 <= sentence.length <= 100
1 <= searchWord.length <= 10
sentence 由小写英文字母和空格组成。
searchWord 由小写英文字母组成。
前缀就是紧密附着于词根的语素,中间不能插入其它成分,并且它的位置是固定的——-位于词根之前。(引用自 前缀_百度百科 )
解题思路
- 最好的方法就是将单词逐个拆捡出来存到动态数组(
vector)或者是哈希表(map)里(数组下标从1开始为key,单词为value即可),然后再利用专们的识别字符串前缀的函数来验证是否子串是单词的前缀。 - C++的STL中的
mismatch()函数的用法:mismatch()返回值是由两个迭代器first1+i和first2+i组成的一个pair,表示第1对不相等的元素的位置。如果没有找到 不相等的元素,则返回last1和first2+(last1-first1)。因此,语句equal(first1,last1,first2)和mismatch(first1,last1,first2).first==last1是等价的。
补充:
- (1)
unordered_multimap,在VS环境下需要添加#include<unordered_map>。但要注意,unordered_multimap里面的key是无序存储的,与输入的顺序不一致,所以不可用unordered_multimap来解题。 - (2)
multimap的特点是key值有序排列,即使每个key值匹配好相应的key值也会因为multimap的特点导致出错。
代码实现
class Solution {
public:
int isPrefixOfWord(string sentence, string searchWord) {
map<int, string> ismap;
string::iterator iter = sentence.begin(), itertemp;
int i = 1;
for(;; iter++)
{
itertemp = iter;
iter = find(itertemp, sentence.end(), ' ');
string str(itertemp, iter);
ismap[i++] = str;
if(iter == sentence.end())
break;
}
for(auto& ismaptmp : ismap)
{
auto iter = mismatch(searchWord.begin(), searchWord.end(), ismaptmp.second.begin());
if(iter.first == searchWord.end())
return ismaptmp.first;
}
return -1;
}
};
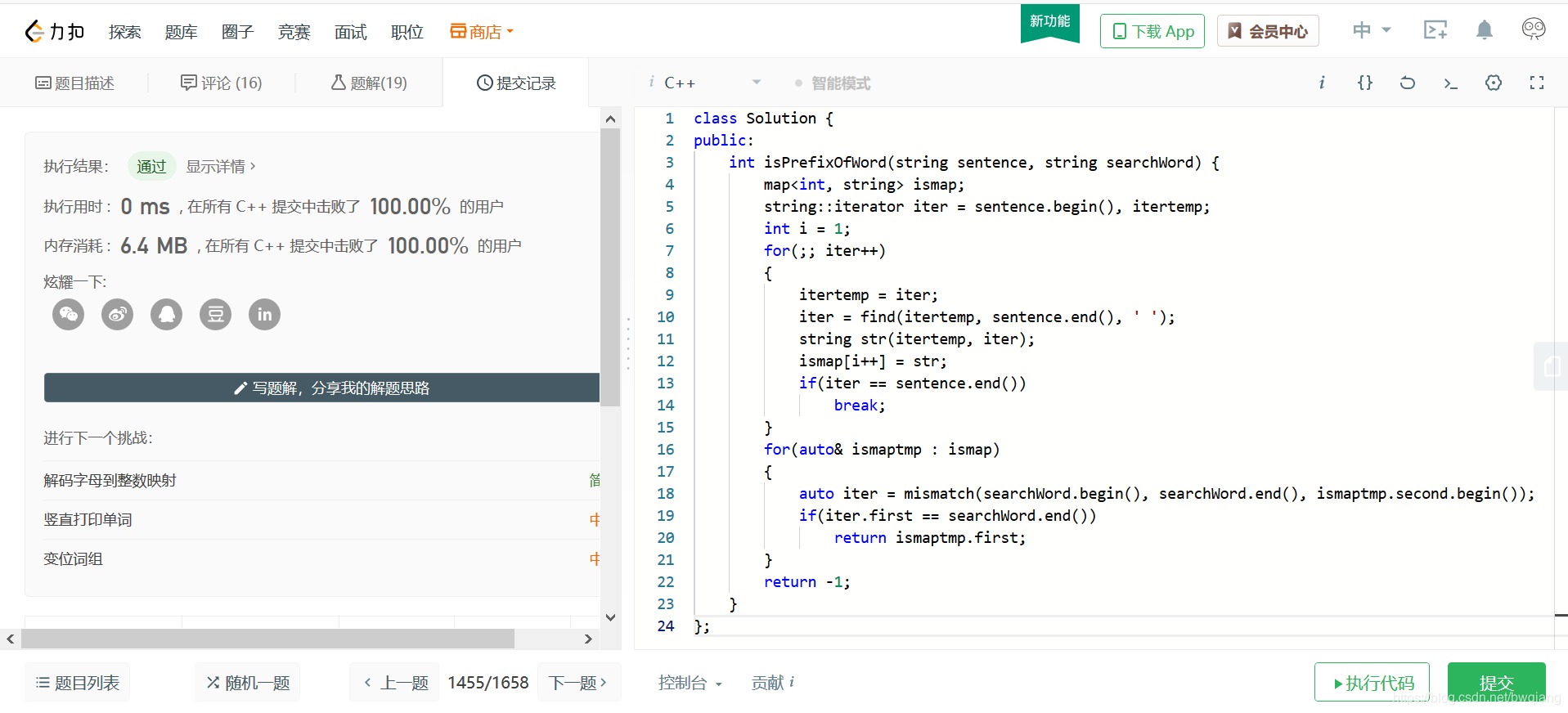
运行截图
2、定长子串中元音的最大数目(4分)
问题描述
给你字符串
s和整数k。
请返回字符串s中长度为k的单个子字符串中可能包含的最大元音字母数。
英文中的 元音字母 为(a, e, i, o, u)。
示例 1:
输入:s = “abciiidef”, k = 3
输出:3
解释:子字符串 “iii” 包含 3 个元音字母。
示例 2:
输入:s = “aeiou”, k = 2
输出:2
解释:任意长度为 2 的子字符串都包含 2 个元音字母。
示例 3:
输入:s = “leetcode”, k = 3
输出:2
解释:“lee”、“eet” 和 “ode” 都包含 2 个元音字母。
示例 4:
输入:s = “rhythms”, k = 4
输出:0
解释:字符串 s 中不含任何元音字母。
示例 5:
输入:s = “tryhard”, k = 4
输出:1
提示:
1 <= s.length <= 10^5
s 由小写英文字母组成
1 <= k <= s.length
解题思路
- 首先定义判断是否是元音的算法。
- 使用滑动窗口的方法求解滑动窗口中的最大元音个数。
- 滑动窗口要使用左边去掉一个并且右边加进一个的算法,这样就可以把时间复杂度控制在 O ( n 2 ) O(n^2) O(n2)。
代码实现
class Solution {
public:
bool isVowels(char& c)
{
if(c == 'a' or c == 'e' or c == 'i' or c == 'o' or c == 'u')
return true;
return false;
}
int maxVowels(string s, int k) {
int i = 0, count = 0, maxnum = 0, begin = 0;
for(; i < s.length(); i++)
{
if(i == k)
break;
if(isVowels(s[i]))
count++;
}
maxnum = max(maxnum, count);
for(; i < s.length(); i++)
{
if(isVowels(s[begin++]))
count--;
if(isVowels(s[i]))
count++;
maxnum = max(maxnum, count);
}
return maxnum;
}
};
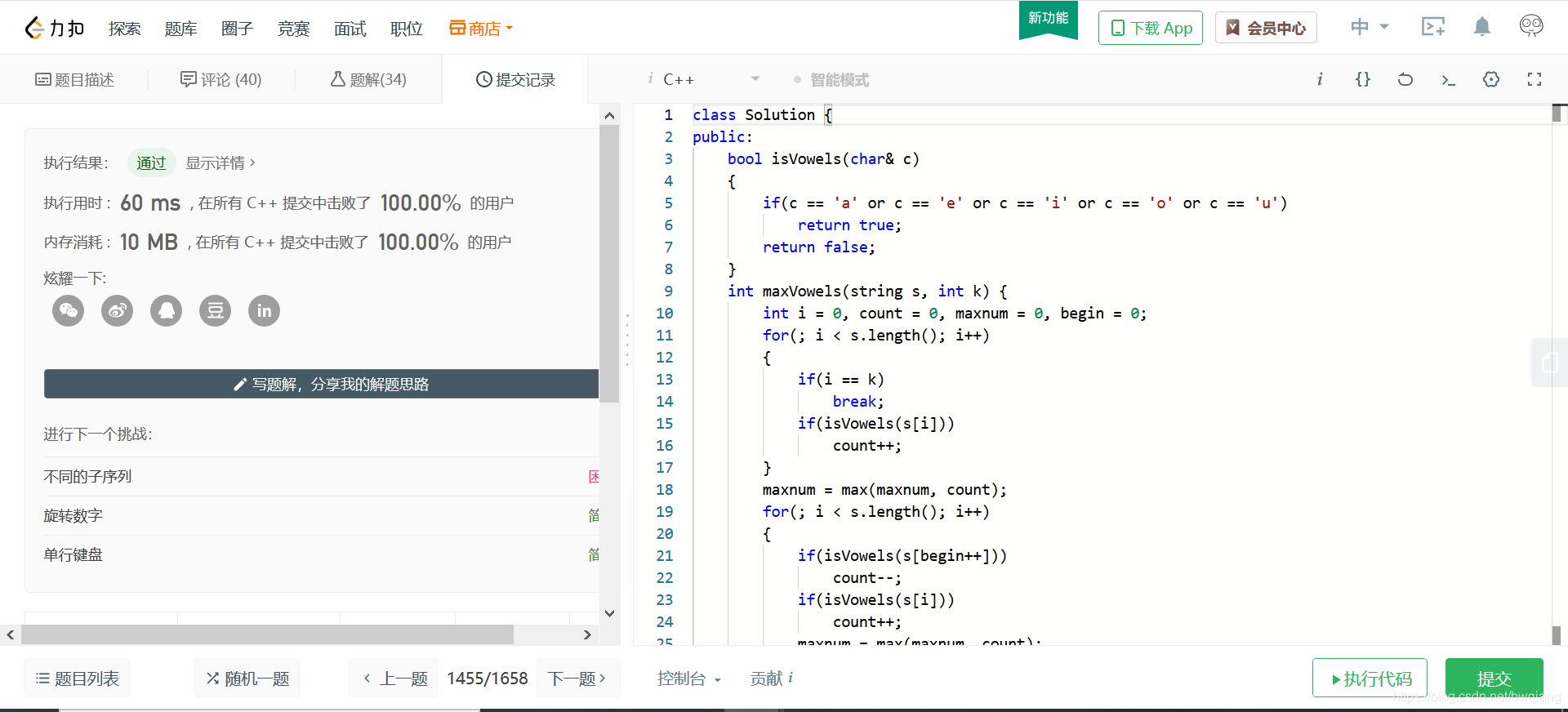
运行截图
3、二叉树中的伪回文路径(5分)
问题描述
给你一棵二叉树,每个节点的值为 1到 9。我们称二叉树中的一条路径是 伪回文的,当它满足:路径经过的所有节点值的排列中,存在一个回文序列。
请你返回从根到叶子节点的所有路径中 伪回文 路径的数目。
示例 1:

输入:root = [2,3,1,3,1,null,1]
输出:2
解释:上图为给定的二叉树。总共有 3 条从根到叶子的路径:红色路径 [2,3,3] ,绿色路径 [2,1,1] 和路径 [2,3,1] 。
在这些路径中,只有红色和绿色的路径是伪回文路径,因为红色路径 [2,3,3] 存在回文排列 [3,2,3] ,绿色路径 [2,1,1] 存在回文排列 [1,2,1] 。
示例 2:

输入:root = [2,1,1,1,3,null,null,null,null,null,1]
输出:1
解释:上图为给定二叉树。总共有 3 条从根到叶子的路径:绿色路径 [2,1,1] ,路径 [2,1,3,1] 和路径 [2,1] 。
这些路径中只有绿色路径是伪回文路径,因为 [2,1,1] 存在回文排列 [1,2,1] 。
示例 3:
输入:root = [9]
输出:1
提示:
给定二叉树的节点数目在 1 到 10^5 之间。
节点值在 1 到 9 之间。
解题思路
- 该算法自然分两部分来解答:(1)通过树的先序遍历算法(或深度优先遍历算法)记录根结点到每一个叶子结点的路径;(2)通过某种算法判断每个路径是否是伪回文数。
- 判断是伪回文的方法:根结点到某一叶子结点的路径中,只存在不多于1个结点的出现频率是奇数,其余各结点的出现频率是偶数。
- 使用
map或unordered_map记录每个结点和在一个路径中结点出现的频率。 - 如果DFS算法遍历到叶子结点时,判断此时
unordered_map中存储的路径是否是伪回文数:是,计数器加1;否,不执行。 - DFS算法在访问一个路径结束后会回溯到叶子结点的父结点,所以在回溯的时候将原来的叶子结点在
unordered_map中的频率减1。如果频率减至0,也无需将该结点从unordered_map中删除,因为0个结点不影响对伪回文数的判断。
代码实现
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int pseudoPalindromicPaths (TreeNode* root) {
dfs(root, iiumap, ans); // 深度优先 也是 树的先序遍历算法
return ans;
}
void dfs(TreeNode* root, unordered_map<int, int>& iiumap, int& ans){
if(root == nullptr)
return;
iiumap[root->val]++;
if(root->left == nullptr and root->right == nullptr)
ans += ispseudoPalindromic(iiumap);
dfs(root->left, iiumap, ans);
dfs(root->right, iiumap, ans);
iiumap[root->val]--; // 在回溯时将上一条路径中叶子结点的出现频率减1
}
bool ispseudoPalindromic(unordered_map<int, int>& iiumap){
int oddnum = 0;
for(auto& iter : iiumap){
if(iter.second % 2 == 0)
continue; // 结点值出现的频率全部为偶数 自然是伪回文数
oddnum++; // 只能允许一个数字频率是奇数个
if(oddnum > 1) // 其余结点出现的频率也是奇数个 说明不是伪回文数
return false;
}
return true;
}
private:
unordered_map<int, int> iiumap;
int ans = 0;
};
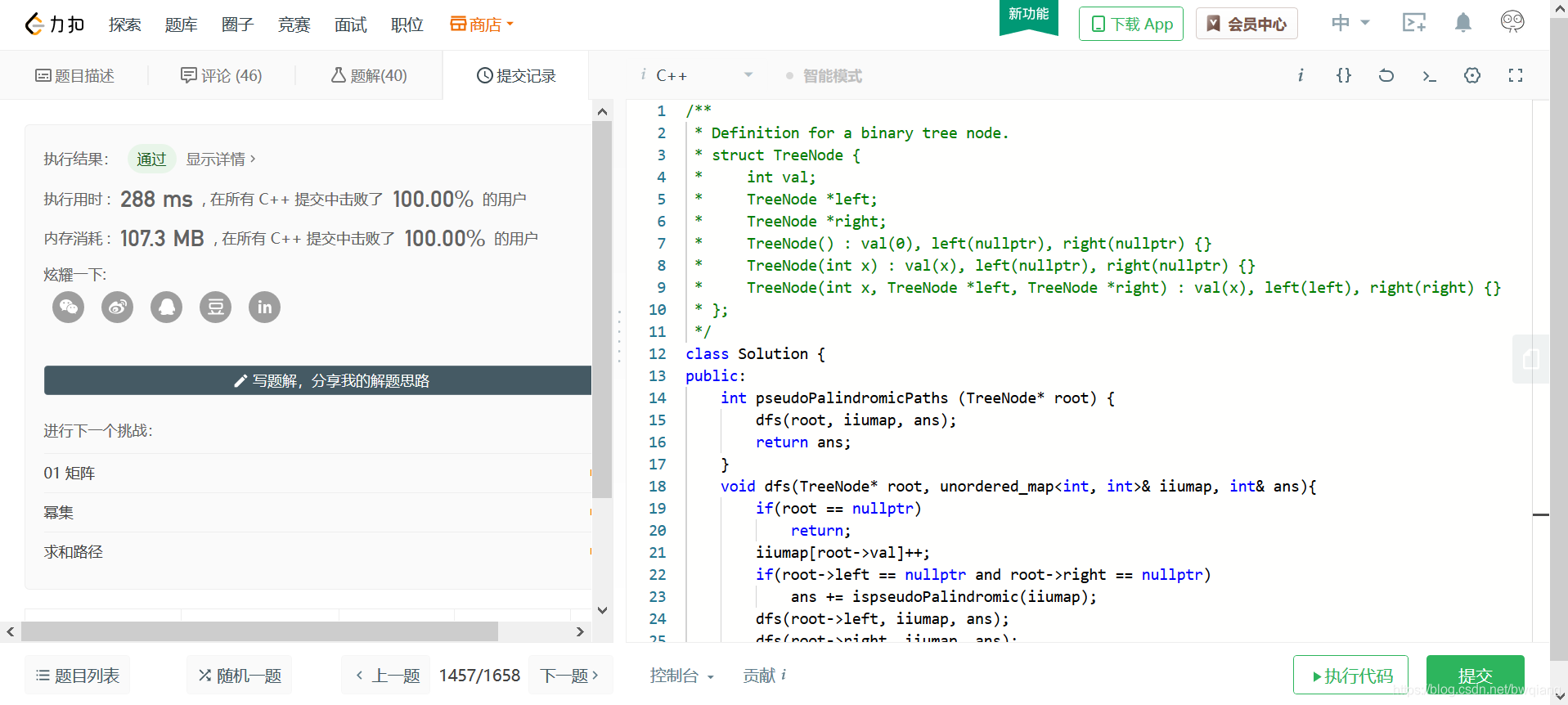
运行截图
4、两个子序列的最大点积(6分)
问题描述
给你两个数组nums1和nums2。
请你返回nums1和 nums2中两个长度相同的 非空 子序列的最大点积。
数组的非空子序列是通过删除原数组中某些元素(可能一个也不删除)后剩余数字组成的序列,但不能改变数字间相对顺序。比方说,[2,3,5]是 [1,2,3,4,5]的一个子序列而[1,5,3]不是。
示例 1:
输入:
nums1 = [2,1,-2,5], nums2 = [3,0,-6]
输出:18
解释:从nums1中得到子序列[2,-2],从nums2中得到子序列[3,-6]。
它们的点积为(2 * 3 + (-2) * (-6)) = 18。
示例 2:
输入:
nums1 = [3, -2], nums2 = [2, -6, 7]
输出:21
解释:从nums1中得到子序列[3],从nums2中得到子序列[7]。
它们的点积为(3 * 7) = 21。
示例 3:
输入:
nums1 = [-1,-1], nums2 = [1,1]
输出:-1
解释:从nums1中得到子序列[-1],从nums2中得到子序列[1]。
它们的点积为-1。
提示:
1 <= nums1.length, nums2.length <= 500
-1000 <= nums1[i], nums2[i] <= 100
点积:
定义 a = [ a 1 , a 2 , … , a n ] a = [a1, a2,…, an] a=[a1,a2,…,an] 和 b = [ b 1 , b 2 , … , b n ] b = [b1, b2,…, bn] b=[b1,b2,…,bn] 的点积为:
a ⋅ b = ∑ i = 1 n a i b i = a 1 b 1 + a 2 b 2 + ⋯ + a n b n \mathbf{a}\cdot \mathbf{b} = \sum_{i=1}^n a_ib_i = a_1b_1 + a_2b_2 + \cdots + a_nb_n a⋅b=∑i=1naibi=a1b1+a2b2+⋯+anbn
这里的 ∑ \sum ∑ 指示总和符号。
解题思路
- 一道动态规划问题。
代码实现
class Solution {
public:
int maxDotProduct(vector<int>& nums1, vector<int>& nums2) {
int n = nums1.size(), m = nums2.size();
vector<vector<int>> pre(n+1,vector<int>(m+1,INT_MIN));
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
int tmp = max(0,pre[i][j]) + nums1[i] * nums2[j];
pre[i+1][j+1]= max(tmp,max(pre[i+1][j],pre[i][j+1]));
}
}
return pre[n][m];
}
};
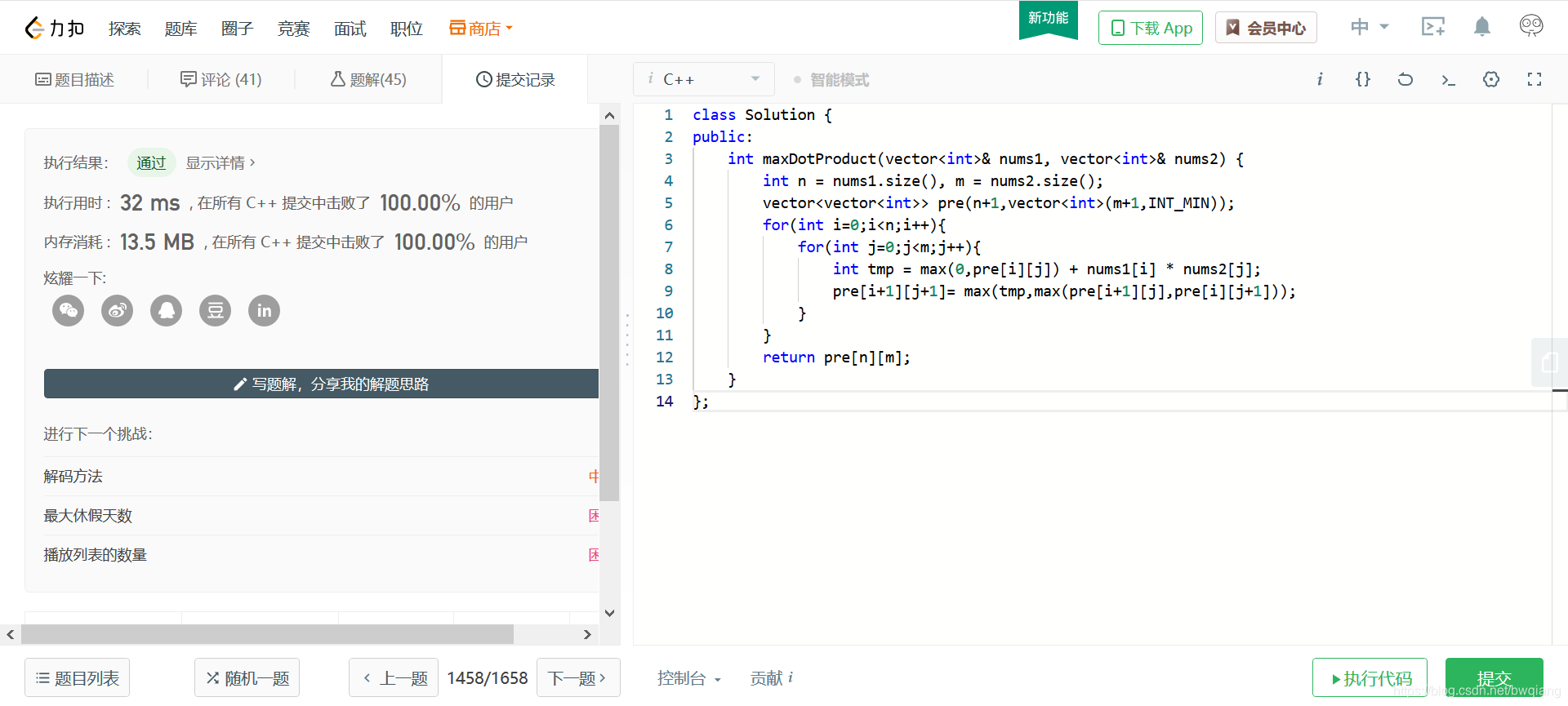
运行截图














 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









