







Abstract
注意分布根据注意问题的重要性在图像中的对象(例如图像区域或边界框)上具有不同的权重分布,它在注意机制中起着至关重要的作用。现有的大多数工作都集中在融合图像特征和文本特征来计算注意力分布的情况下,而不需要在不同图像对象之间进行比较。作为关注的主要属性,选择性取决于不同对象之间的比较。比较提供了更多信息,可以更好地分配注意力。作者提出了一种对象差异注意(ODA),该方法通过在手头问题的指导下在图像中的不同图像对象之间实施差异算子来计算注意力的概率。
1 INTRODUCTION
注意力分布是图像中每个对象回答给定问题的标准化重要性。 当前的大多数基于注意力的VQA模型通过仅考虑问题和对象本身来计算对象的重要性,尽管重要性最终已在所有对象上标准化。但是,对象本身通常不足以提供足够的信息来为许多其他类型的问题分配适当的注意力分布。(比如图片中哪个花最高,这种问题就需要比较图片中其他的物体)。所以说比较有助于确定到底想要哪个对象。 比较有利于定位物体的位置。 比较以确定两个对象是否属于同一类是必要的,依此类推。 因此,问题在于如何在注意力分配中包括不同对象之间的比较信息。
作者提出了一种新的注意力类型,称为对象差异注意力(ODA),以解决该问题。 对于给定的图像和问题,使用来自问题以及图像中不同对象之间的比较的信息来分配对每个对象的关注。 比较是通过两个对象之间的差异运算符实现的。 与诸如Mutan之前的研究相比,ODA的计算复杂度更低。
此外,作者将ODA扩展到一般的关系注意,并使用不同的关系内核给出几种不同类型的关系注意。 实验结果表明,不同核的注意在不同类型的问题上具有优势。 其中,ODA在大多数类型的问题中都显示出优势。
2 RELATEDWORK
最初,使用一步线性融合来计算注意力分布。 例如,ABC-CNN模型将问题特征映射到视觉空间,然后通过对问题特征和图像特征进行卷积来计算图像区域的注意力分布。 CoAtt模型将图像特征和问题特征与可训练参数联系起来,以获得联系矩阵。 然后可以使用此矩阵对图像特征空间和问题特征空间进行转换,最后将其与线性函数合并以获得注意力分布。
一些工作尝试多步骤关注。 SAN模型将视觉特征映射到与问题特征尺寸相同的向量中。 图像区域上的第一步注意力分布是视觉特征和问题特征的线性组合。 通过将视觉功能与更新的问题功能融合来更新注意力分布。 SMem模型通过相关矩阵将图像特征和问题特征融合在一起,然后在文本维度上对矩阵求和,以获得图像区域的第一跳注意力分布。 与SAN相似,Smem将图像特征和问题特征的总和作为新的问题特征。 通过将这些问题特征与图像特征再次融合来计算第二跳注意力分布。 DAN模型也有很多注意事项,但是图像特征和文本特征是用tanh分别激活的,然后通过逐元素乘法融合。
最近的一些工作使用双线性模型来融合图像特征和问题特征。 MCB模型首先引入了双线性合并操作以融合图像特征和问题特征。 它具有较大的特征尺寸。 为了减小输出尺寸,MLB模型使用Hadamard产品运算将图像特征与文本特征融合在一起。 与MCB相比,MLB可以输出更紧凑的功能。 但是,它收敛缓慢并且对超参数敏感。 MFB模型结合了MCB和MLB在容量和紧凑功能方面的优势。 一维非重叠窗口用于对图像特征和问题特征的Hadamard乘积执行求和池。 Mutan模型使用Tucker分解张量并获得相似的表达式。
最近,执行多特征注意力以计算多特征注意力分布。 高阶注意力模型通过学习这些特征之间的高阶相关性,分别计算图像,问题和答案的注意力分布。 ReasonNet模型首先要通过一系列输入功能(包括表面分析,对象分类,场景分类)进行推理,然后结合结果来推断答案。 同样,DualMFA模型使用自由形式的区域和检测框作为输入特征。
3 ODA FOR VQA
的VQA模型的整体结构如下图所示。它由三个部分组成:数据嵌入,对象差异注意(ODA)和决策制定。 数据嵌入从RCNN提取图像特征,从GRU提取问题特征。 ODA通过在问题的指导下将每个图像对象与所有其他对象进行显式比较,从而计算图像中对象的注意力分布。 决策制定融合图像特征和问题特征以选择问题的答案。

3.1 Data Embedding
首先对输入的图像和问题进行嵌入,图像由Fast-RCNN来进行特征提取,问题由GRU来进行特征提取。

其中代表排名前m个boxes的视觉特征。
代表问题的嵌入。为了将
和
映射到相同的维度,使用了一个全连接层和一个一维的卷积层。
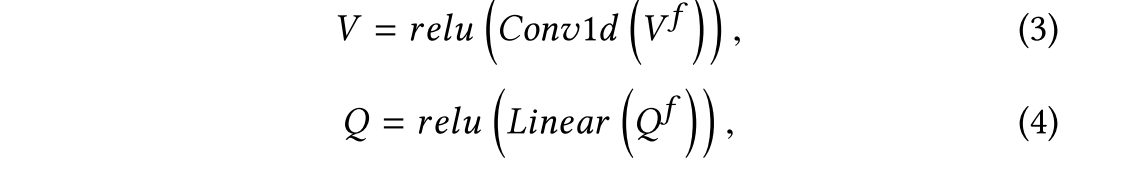
其中 可以视为m个物体,
。
是问题的特征。
3.2 Object-Difference Attention (ODA)
将ODA定义为如下公式:
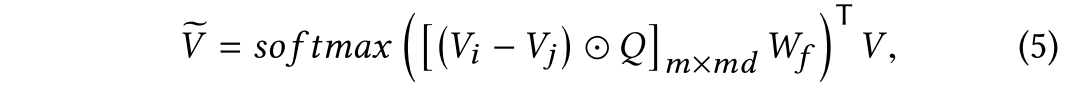
其中是图片中物体i和物体j在问题Q的指导下比较的结果。所以
为大小为m×md的矩阵,第i行表示第i个对象与所有其他对象的比较结果。
是一个可学习的参数,通过n次瞥见将比较结果转化为n个注意分布。
是注意力结果。
要注意以下部分:
首先,与以往的研究不同,ODA包含一个问题引导的显式差分算子(也就是对两个物体的特征进行相减),用于显式比较图像中不同对象。以问题为引导,将与其他其他物体进行比较能够测量
对于回答这个问题有多重要,这也是符合直觉的。作者在这里强调了比较的重要性,从认知科学来看,选择的过程就是一个比较的过程。其他的工作中,比如图片搜索通过比较也有所提高。
第二点,作者强调了作差是一个计算简便的操作,与MUTAN模型进行了对比,MUTAN的参数数量为,时间复杂度为
,作者提出的模型的参数数量为
,
,而
,
,
。所以说作者的模型在参数方面会更少。
第三,ODA可以很容易地扩大两倍。 首先,ODA是一个即插即用的模块,可以很容易地部署在其他需要注意机制的模型中。 其次,ODA是一种新型的关注方式,称为关系关注。
3.3 Decision Making
作者将公式五计算了p次,得到了p个:
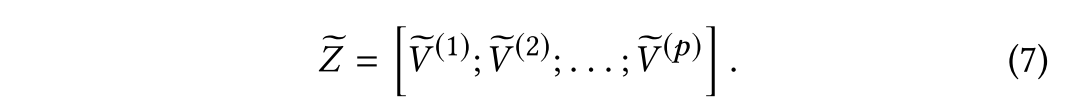
其中[;]代表连接操作,是连接后的视觉特征。使用如下公式进行视觉和文本的特征融合:
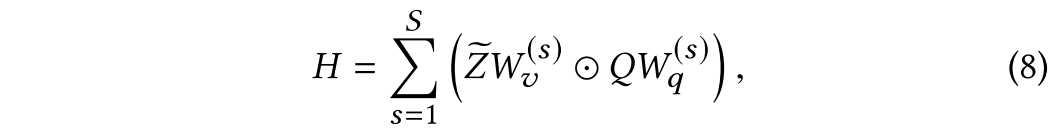
其中是超参数,
和
是可学习的参数,
是最终融合的特征。
最终使用一个线性层,激活函数使用sigmod来进行最终的预测。
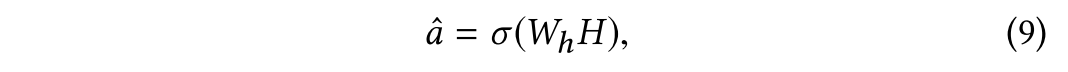
3.4 Loss Function For Model Training
首先计算地面真值答案分布:
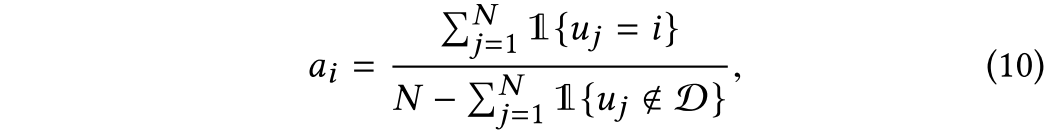
其中是由第i个注释者给出的答案。N是注释者的数量。例如,在VQA 1.0和VQA 2.0数据集中N是10,在COCO-QA数据集中N是1。
KL-divergence用作a和之间的损失函数:
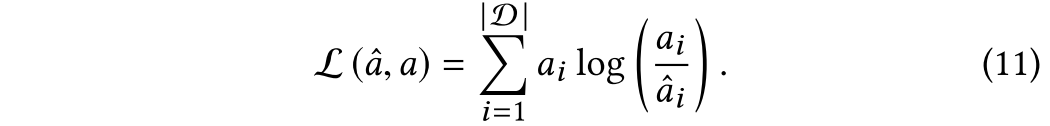
4 RELATIONAL ATTENTION
在本节中,作者介绍了关系注意的一般形式,并给出了关系注意的其他一些情况。
首先任何注意力都可以被写成如下:
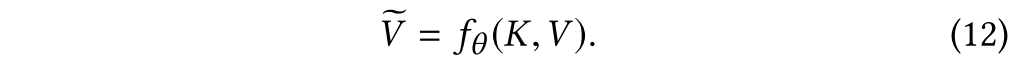
包含以下三部分:
第一部分为,它被称为注意目标,即基于注意的模型所关注的对象。
是目标中的对象数量,
是每个对象的维数。注意的目的是获得这m个对象的重要性分布。 例如,V可以是图像,一段文本或几个候选答案。
第二部分是,它被称为注意核。注意力核函数决定了如何计算注意力的分布。如果在外部引导Q下,通过对注意目标集合中两个对象
和
之间的二元关系运算R得到一个注意核,如式(13)所示,则该注意核称为关系注意核(relational attention kernel,简称关系型核)。
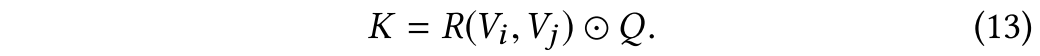
具有关系内核的注意被称为关系注意。第3节中提出的ODA是一种关系注意,在问题q的指导下,在不同的图像对象之间使用了一个差分算子。称ODA中的关系核为object-difference kernel (ODK)。在关系内核的一般定义下,很容易引入一些其他的关系内核。在表1中给出了一些。例如,OUK在不同对象之间使用union操作符。

第三部分就是,它被称为注意算子。它决定了注意力内核如何作用于注意力目标。任务本身往往提示我们应该使用什么样的
。例如,在分类任务中,我们需要综合注意结果
。作为对比,在机器翻译任务中,我们需要新的编码
。对于前者,我们可以使用
,其中
。对于后者,我们可以使用
,其中
。
5 EXPERIMENTS




















 929
929











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









