







Abstract
基于双线性池的模型已经被证明优于传统的VQA线性模型,但是它们的高维表示和高计算复杂度可能严重限制它们在实践中的适用性。对于多模态特征融合,作者提出了一种多模态分解双线性(MFB)汇集方法,以高效和有效地组合多模态特征,这使得VQA的性能优于其他双线性汇集方法。对于细粒度的图像和问题表示,作者提出了一种“共同关注”机制,使用端到端的深层网络架构来共同学习图像和问题关注。在一个新的网络架构中,将提议的MFB方法与共同注意学习相结合,为VQA提供了一个统一的模型。
1. Introduction
现有的VQA方法通常有三个阶段:(1)将图像表示为视觉特征,将问题表示为文本特征;(2)结合这些多模态特征以获得融合的图像问题特征;(3)使用集成的图像-问题特征来学习多类分类器并预测最佳匹配答案。深层神经网络是有效和灵活的,许多现有的方法在一个DNN模型中模拟三个阶段,并通过反向传播以端到端的方式训练模型。在这三个阶段中,特征表示和多模态特征融合尤其影响VQA性能。
简单的相乘或者相加不能表示两个模态之间的复杂关系,所以有人提出(MCB)使用张量算法进行模态特征融合,但是这导致了参数过多,无法实用。后来针对这个问题有人提出了(MLB),使用Hadamard product来进行两个模态特征的融合,但是这个方法收敛太慢并且对超参数十分敏感,所以作者针对这两个弱点提出了(MFB),具有MLB输出特性紧凑和MCB表达能力强的双重优势。
并且基于此,作者还使用了co-attention,即不光考虑根据问题找到图片中重要的区域,还要找到问题中关键的词。
2. Related Work
2.1. Visual Question Answering (VQA)
VQA 方法可分为粗联合嵌入模型、细粒度有注意联合嵌入模型和基于外部知识的模型。
2.2. Multi-modal Bilinear Models for VQA
主要还是介绍了MCB和MFB。
3. Multi-modal Factorized Bilinear Pooling
给定视觉特征,文本特征
,最简单的多模态双线性模型定义如下:
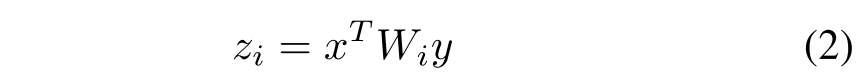
其中是一个映射矩阵,
是模型的输出,为了得到维度为o的输出,所有映射矩阵
,尽管上述模型能够很好地捕捉特征之间的交互,但是计算量过大并且可能过拟合。
受单模态数据矩阵分解技巧的启发,上述模型可以转化为:
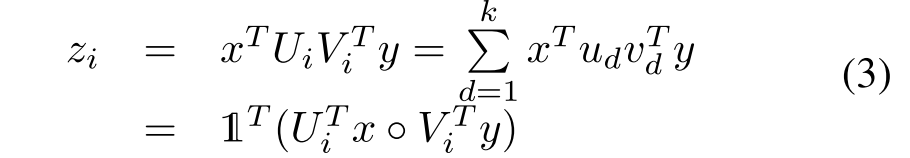
其中k是因子或因子化矩阵的潜在维数,
,
是Hadmard积或两个向量的元素方向乘法。要学习的权重为
,
,可以将U和V改写为
,
。
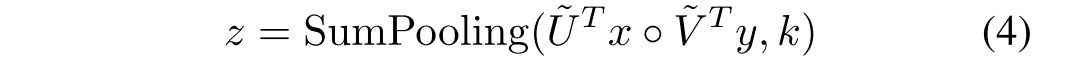
其中函数SumPooling(x,k)意味着使用大小为k的一维非重叠窗口对x执行SumPooling。该方法可以通过组合一些常用的层来容易地实现,例如完全连接层、按元素的乘法和汇集层。此外,为了防止过度拟合,在元素方向倍增层之后添加了Dropout层。由于引入了逐元素乘法,输出神经元的大小可能会有很大的变化,模型可能会收敛到一个不令人满意的局部最小值。所以引入了power归一化
和l2归一化
。如下图所示

与MLB的关系:等式(4)表明,等式(1)中的MLB是拟议的MFB的特例,其中k = 1,它对应于秩-1因式分解。 从形象上讲,MFB可以分解为两个阶段(见图1(b)):首先,将来自不同模态的特征扩展到高维空间,然后与逐元素乘法集成。 此后,执行总和池和归一化层,以将高维特征压缩为紧凑输出特征,而MLB将特征直接投影到低维输出空间并执行逐元素乘法。 因此,在输出特征尺寸相同的情况下,MFB的表示能力要比MLB强大。
4. Network Architectures for VQA
VQA任务的目标是回答一个关于图像的问题。模型的输入包含一个图像和关于该图像的相应问题。模型提取图像和问题表示,使用MFB模型集成多模态特征,将每个单独的答案视为一个类别,并执行多类别分类以预测正确答案。本节将介绍两种网络体系结构。第一个是带有一个MFB模块的MFB基线,用于执行不同超参数的消融分析,以便与其他基线方法进行比较。第二个网络引入共同注意学习,共同学习图像和问题注意,以更好地捕捉图像和问题之间的细粒度相关性,这可能导致具有更好的表示能力的模型。
4.1. MFB Baseline
使用在ImageNet数据集上预先训练的152层ResNet模型来提取图像特征。图像大小调整为448 × 448,2048-D池5特征(带l2归一化)用于图像表示。问题首先被标记成单词,然后进一步被转换成最大长度为t的one-hot特征向量。然后,one-hot通过嵌入层,并被馈送到具有1024个隐藏单元的两层LSTM网络。每个LSTM层为每个单词输出一个1024-D特征。从每个LSTM网络中提取最后一个词的输出特征,并将获得的两个LSTM网络的特征连接起来,形成用于问题表示的2048-D特征向量。为了预测答案,简单地使用前N个最频繁的答案作为N个类,因为它们遵循长尾分布。
提取的图像和问题特征被馈送到MFB模块以生成融合特征z。最后,z被馈送到具有KL散度损失的N路分类器。因此,除了ResNet的权重之外(由于内存的限制),所有的权重都以端到端的方式进行了联合优化。整个网络架构如下图所示。

4.2. MFB with Co-Attention
对于给定的图像,不同的问题会导致完全不同的答案。因此,可以预测每个空间网格与问题的相关性的图像注意力模型有利于预测准确的答案,14×14 (196)图像空间网格(ResNet中的res5c特征地图)用于表示输入图像。在此之后,问题特征与196个图像特征中的每一个使用MCB合并,随后是一些特征变换(例如,1 × 1卷积和ReLU激活)和软最大归一化以预测每个网格位置的注意力权重。基于注意图,通过空间网格向量的加权和获得注意图像特征。生成多个注意力图以增强所学习的注意力图,并且这些注意力图被连接以输出注意力图像特征。最后,使用MCB将注意力图像特征与问题特征进行融合,以确定最终的答案预测。
从[6]报告的结果可以看出,引入注意机制可以让模型有效地了解哪个区域对问题来说是重要的,这显然比没有注意的模型有更好的表现。然而,[6]中的注意模型只关注学习图像注意,而完全忽略问题注意。由于问题被解释为自然语言,每个单词的贡献是显著不同的。因此,这里我们开发了一种共同注意学习方法(见图3),来共同学习问题和图像注意。
我们的共同注意模型的网络结构与[6]中的注意模型的不同之处在于,我们在LSTM网络之后增加了一个问题注意模块,以学习问题中每个单词的注意权重。与VQA的其他共同注意模型不同,在我们的模型中,图像和问题模块是松散耦合的,因此我们在学习问题注意模块时不利用图像特征。这是因为我们假设网络可以直接推断出问题的注意力(即问题的关键词),而不用像人类那样看到图像。我们将这个网络命名为MFB联合关注(MFB+CoATT)。

5. Experiments




















 3282
3282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









