







Abstract
尽管视觉问答(VQA)在过去几年中已经取得了令人瞩目的进步,但是当今的VQA模型倾向于捕获训练集中的表层语言相关性,而不能推广到具有不同QA分布的测试集中。为了减少语言偏见,最近的一些工作引入了一个辅助的仅问题模型,以规范化目标VQA模型的训练,并在VQA-CP上实现主导性能。但是,由于设计的复杂性,当前的方法无法为基于集成模型的模型配备理想VQA模型的两个必不可少的特征:1)视觉可解释的:模型在做出决策时应依赖正确的视觉区域。 2)对问题敏感:该模型应对所讨论的语言变化敏感。为此,我们提出了一种与模型无关的反事实样本合成(CSS)训练方案。 CSS通过掩盖图像中的关键对象或问题中的单词并分配不同的真实答案来生成大量反事实训练样本。在使用补充样本(即原始样本和生成的样本)进行训练后,VQA模型被迫专注于所有关键对象和单词,从而显着提高了视觉可解释性和问题敏感性能力。作为回报,这些模型的性能将进一步提高。广泛的消融显示了CSS的有效性。尤其是,通过在LMH模型[14]的基础上构建,我们在VQA-CP v2上实现了创纪录的58.95%的性能,并提高了6.5%。
1. Introduction
目前的VQA模型严重依赖于表层语义相关性(语言偏见,这里也可以说是存在答案分布的偏见),因此在18年提出了新的基准数据集VQA-CP,这个数据集的训练集和测试集的答案分布是不同的,尽可能消除了偏见,很多之前准确率高的模型的准确率大幅下降。
现有解决偏见的模型是基于组合式的模型,可以分为两种类型:
- 1) adversary-based 基于对抗的
最小化VQA模型的损失,同时最大化仅问题模型的损失。 由于两个模型被设计为共享相同的问题编码器,因此基于对抗的方法旨在通过学习与偏差无关的问题表示形式来减少语言偏差。 不幸的是,对抗训练方案将明显的噪声引入了梯度,并导致了不稳定的训练过程。
基于对抗方法的文献:
Overcoming language priors in visual question answering with adversarial regularization.
Adversarial regularization for visual question answering
Don’t take the premise for granted: Mitigating artifacts in natural language inference.
- 2) fusion-based 基于融合的
在后期融合了两个模型的预测答案分布,并基于融合答案分布得出训练梯度。 基于融合的方法的设计原理是让目标VQA模型更多地关注“仅问题”模型无法正确回答的样本。
基于融合方法的文献:
Rubi: Reducing unimodal biases in visual question answering
Don’t take the easy way out: Ensemble based methods for avoiding known dataset biases.
Simple but effective techniques to reduce biases.
上述方法不能同时增加VQA的两个必要属性:
1、视觉可解释性:模型应该更加注意与问题更相关的视觉区域,也就是针对正确的区域做出决定,如下图(a)中所示,虽然两个模型都做出正确的答案,但是两个模型参考的视觉区域却是不同的,这无法解释为何得到正确答案。
2、问题敏感度:模型应该对所讨论的语言变化敏感,也就是说应该注意问题的敏感词(重要的词),当敏感词变化的时候,得到的答案应该变化,模型的处理也应该有变化。如下图中的(b),当颜色属性的主体从“行李”变到了"汽车",答案却并不变化,说明模型没有意识到“敏感词”的变化。

作者提出了与模型无关的反事实样本合成(CSS)训练方案,这个CSS方案可以合成到其他模型内,可以有效提高模型的视觉可解释性和问题敏感度,CSS由两种不同的样本合成机制组成:V-CSS和Q-CSS。对于V-CSS,它通过掩盖原始图像中的关键对象来合成反事实图像。意味着这些对象对于回答某个问题很重要(例如,“男人的领带是什么颜色”问题的对象)。然后,反事实图像和原始问题组成了一个新的图像问题(VQ)对。对于Q-CSS,它通过使用特殊标记“ [MASK]”替换原始问题中的关键单词来合成反事实问题。同样,反事实问题和原始图像构成了新的VQ对。给定一个VQ对(来自V-CSS或Q-CSS),标准的VQA训练样本三元组仍需要相应的真实答案。为避免昂贵的人工注释,设计了一种动态答案分配机制,以近似所有合成VQ对的真实答案(例如,图2中的“非绿色”)。然后,我们使用所有原始样本和合成样本训练VQA模型。经过大量补充样本训练后,VQA模型被迫专注于关键对象和单词。

实验证明该策略的有效性,并在模型LMH的基础上加上CSS达到了58.92%的准确率,这是VQA-CP目前的最高纪录。
2. Related Work
(1)Language Biases in VQA.
很多的工作已经证实语言偏见的存在,解决语言偏见的方法有两种,
- 平衡数据集减少偏见,想法如针对所有二元问题收集了具有相反答案的互补抽象场景。针对所有问题都收集相反的互补抽象场景,这一定程度上减少了偏见,但是仍然可以利用问题的统计偏差[3]。 如基准VQA-CP所示,与这些“平衡”数据集相比,许多模型的性能明显下降。 在本文中遵循相同的数据集平衡精神,并使用更多互补样本来训练VQA模型。并且不需要额外的人工标注。
- 设计模型减少偏见,目前最好的模型是基于集成的模型,CSS可以无缝地结合到基于ensembl的模型中,以进一步减少偏差。
(2)Visual-Explainable Ability in VQA Models
为了提高视觉解释能力,早期的工作直接将人的注意力作为指导来指导模型的注意力图。 但是,由于存在强烈的偏见,即使有适当的注意力图,网络的其余层仍可能会忽略视觉信号。 因此,一些最近的工作利用Grad-CAM获得每个对象的独自的贡献来纠正答案,并鼓励所有对象贡献的等级与人类注释相一致。 不幸的是,这些模型有两个缺点:1)它们需要额外的人工注释。 2)训练不是端到端的。
(3)Question-Sensitive Ability in VQA Models.
如果VQA系统确实“理解”了问题,那么它们应该对所讨论的语言变化敏感。 具体来说,设计了两个双重任务之间的周期一致损耗,并利用采样的噪声生成各种问题。 但是,仅考虑了不同问题改写的鲁棒性。 相反,我们也鼓励模型在更改一些关键词时感知问题的差异
(4)Counterfactual Training Samples for VQA.
一些并行的工作也尝试为VQA合成反样本。 与这些都依赖于GAN生成图像的工作不同,CSS仅掩盖了关键的对象或单词,这更容易且更易于采用。
3. Approach
目前将VQA任务是当做一个多类别的分类任务,不失一般性,给定一个数据集,三元组,图片
问题
和答案
,VQA任务学习映射
,对于给定的图片-问题对给出答案分布。在本节中,首先介绍基本的自底向上自顶向下模型[4],以及3.1节中基于ensembl的去偏方法。然后,我们将在第3.2节中详细介绍反事实样本综合(CSS)。
3.1. Preliminaries
Bottom-Up Top-Down (UpDn) Model. 对于一张图片,图片编码器
可以输出对象特征的集合
,其中
是第i个对象特征,对于每个问题Q,模型使用一个问题生成器
输出单词特征的集合:
,其中
是第i个单词的特征。将特征V和Q输入到模型
来预测答案分布:
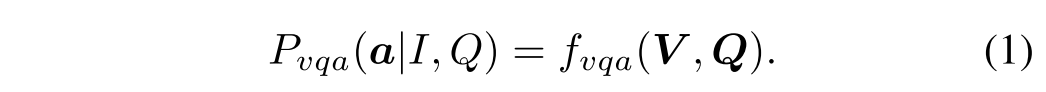
模型一般包括注意力模块,以交叉熵损失训练模型。
Ensemble-Based Models. 由于以对抗形式的集成模型不稳定,所以介绍以融合方法为基础的模型,引入一个只需要问题的模型,模型只需要输入问题就预测答案(忽略图片特征的输入):
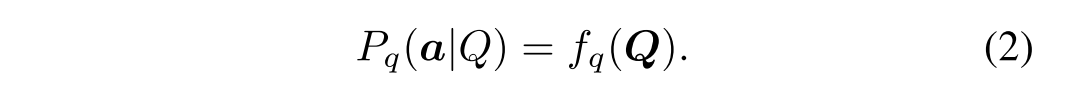
然后将 模型和正常模型的答案分布进行结合(相乘)得到一个新的答案分布
,
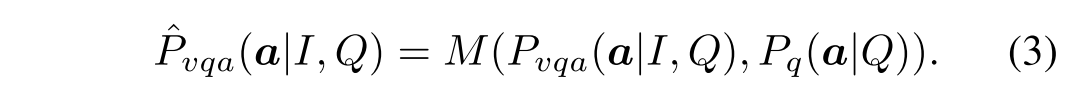
在训练阶段,损失函数是根据 来计算,训练梯度的反向传播是要通过
和
,在测试阶段只有
。

3.2. Counterfactual Samples Synthesizing (CSS)
CSS包括三个主要的步骤,
- 以初始的三元组
训练模型
- 通过V-CSS合成反事实样本
和Q-CSS反事实样本
.
- 用反事实样本训练模型

对于每个训练样本,我们只使用一个特定的合成机制(意思就是一个样本要么使用V-CSS要么使用Q-CSS),δ是权衡值。
3.2.1 V-CSS
根据算法2中显示,V-CSS包含个步骤:初始化对象的选择(),对象局部贡献的计算,重要对象的选择(CO_SEL),动态分配答案((DA_ASS),
1. Initial Objects Selection (IO_SEL).
由于图片中的对象只有一小部分跟问题是相关,所以需要选择出与图片有关系的一个小的对象集合,想法就是首先用SpaCy POS标签给问题中每个单词一个标签,从中选择出名词,计算对象类型与名词的cosine相似度,选择出其中相似度最高的作为集合
。
2. Object Local Contributions Calculation.
得到对象集合后,计算那个对象对于回答问题更有作用,利用修改的Grad-CAM来获得哪个对象的的贡献最大,
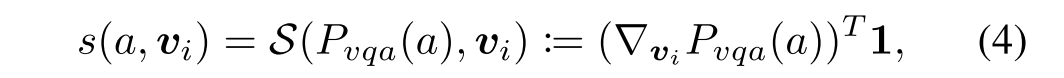
其中代表的正确答案a的预测概率,
代表第i个视觉特征,
越高则
的贡献越大。
3. Critical Objects Selection (CO_SEL).
计算完集合内所有对象的贡献后,选择其中贡献最大的K个(score最高的K个),K由以下公式决定:
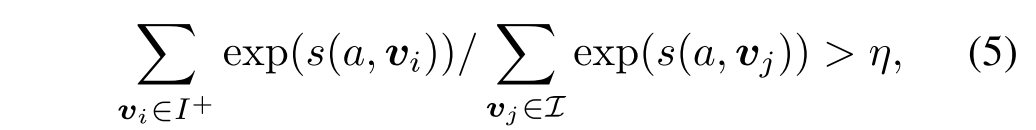
其中是一个常数,以下所有试验都将
设置为0.65。然后
是
的绝对补集,即
。

4. Dynamic Answer Assigning (DA_ASS).
对于反事实视觉输入和原始问题输入
构成新的问题视觉对,为了分配正确的答案,首先将
输入到VQA模型内,然后得到
,根据
选择概率值最高的K个答案为集合
。然后将剩余的作为
,最极端的情况就是
包含所有的正确答案,则
内不包含正确答案,相当于一个空集。这个方法的动机就是
可以正确预测答案,则
就不应该再包含原本问题中的正确答案了。

3.2.2 Q-CSS
根据算法2中,Q-CSS包含四步,计算每个单词的贡献,选择其中最重要的单词,动态地分配答案。
1. Word Local Contribution Calculation.
以下公式计算每个单词的贡献率:
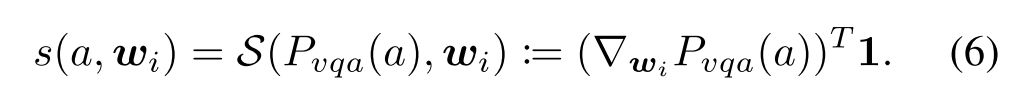
2. Critical Words Selection (CW SEL.)
首先提取能够代表每个问题类型的单词(What color is the kite?中的what color),然后选择K个除了问题类型单词的分数最高的单词当做最重要的单词,然后将重要的单词替换成'[mask]'后得到。而
就是将除了类型单词和重要单词以外的单词替换成[mask],
3. Dynamic Answer Assigning (DA_ASS.)
与V-CSS这一步骤相同,这一步骤DA_ASS的输入是.
4. Experiments
首先是消融实验,集合I的大小、关键字的个数、参数的大小。



















 700
700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









