







语音识别概述
语音识别是指将语音信号转换为文字的过程。现在通行的语音识别系统框架如图: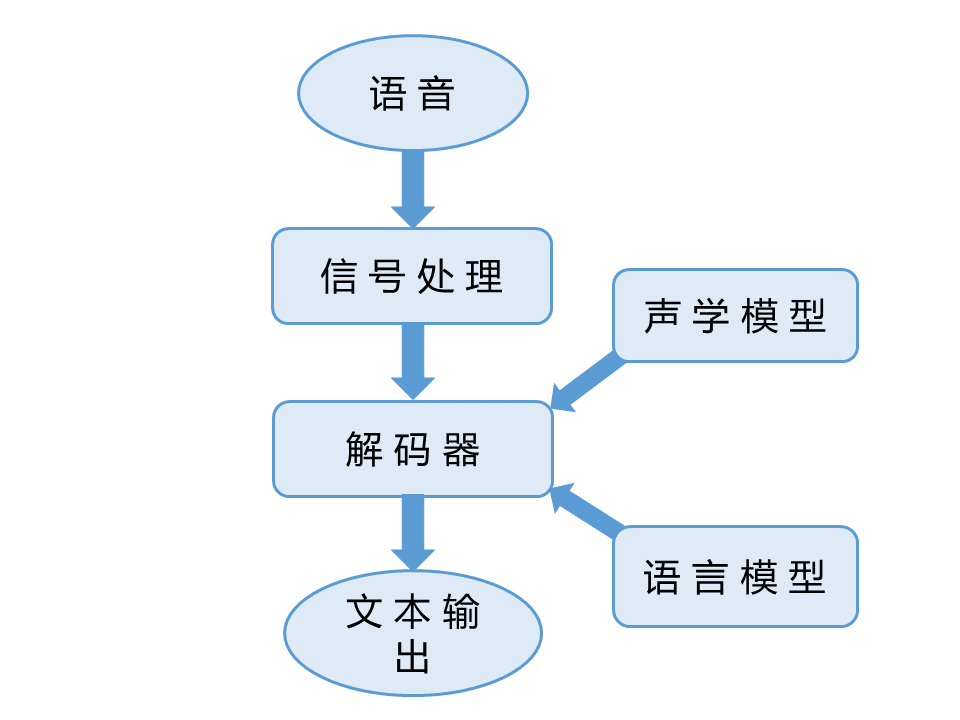
信号处理模块将根据人耳的听觉感知特点,抽取语音中最重要的特征,将语音信号转换为特征矢量序列。现行语音识别系统中常用的声学特征有线性预测编码(Linear Predictive Coding,LPC),梅尔频率倒谱系数(Mel-frequency Cepstrum Coefficients,MFCC),梅尔标度滤波器组(Mel-scale Filter Bank,FBank)等。
解码器(Decoder)根据声学模型和语言模型,将输入的语音特征矢量序列转化为字符序列。
声学模型是对声学、语音学、环境的变量,以及说话人性别、口音的差异等的知识表示。语言模型则是对一组字序列构成的知识表示。
模型的训练
现代的语音识别系统中声学模型和语言模型主要利用大量语料进行统计分析,进而建模得到。
声学模型
语音识别中的声学模型充分利用了声学、语音学、环境特性以及说话人性别口音等信息,对语音进行建模。目前的语音识别系统往往采用隐含马尔科夫模型(Hidden Markov Model,HMM)建模,表示某一语音特征矢量序列对某一状态序列的后验概率。隐含马尔科夫模型是一种概率图模型,可以用来表示序列之间的相关关系,常常被用来对时序数据建模。
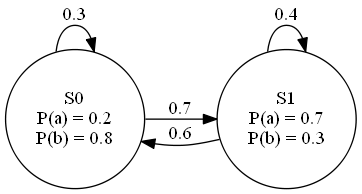
隐含马尔科夫模型是一种带权有向图,图上每一个节点称为状态。每一时刻,隐含马尔科夫模型都有一定概率从一个状态跳转到另一个状态,并有一定概率发射一个观测符号,跳转的概率用边上的权重表示,如图所示, S0 和 S1 表示状态, a 和 b 是可能发射的观测符号。
隐含马尔科夫模型假定,每一次状态的转移,只和前一个状态有关,而与之前之后的其它状态无关,即马尔科夫假设;在每一个状态下发射的符号,只与当前状态有关,与其它状态和其它符号没有关系,即独立输出假设。
隐含马尔科夫模型一般用三元组 λ=(A,B,π) 表示,其中 A 为状态转移概率矩阵,表示在某一状态下转移到另一状态的概率;B 为符号概率矩阵,表示在某一状态下发射某一符号的概率;π 为初始状态概率矢量,表示初始时处在某一状态的概率。
隐含马尔科夫模型可以产生两个随机的序列,一个是状态序列,一个是观测符号序列,所以是一个双重随机过程,但外界只能观测到观测符号序列,不能观测到状态序列。可以利用维特比算法(Viterbi Algorithm)找出在给定观测符号序列的条件下,发生概率最大的状态序列。对于某一观测符号序列的概率,可以通过前向后向算法(Forward-Backward Algorithm)高效地求得。每一个状态的转移概率和观测符号发射概率可以通过鲍姆—韦尔奇算法(Baum-Welch Algorithm)计算得到。
语音识别中一般使用隐含马尔科夫模型对声学单元和语音特征序列之间的关系建模。一般来说,声学单元级别较小,其数量就少,但对上下文的敏感性则会大。大词汇量连续语音识别系统中一般采用子词(Sub-word)作为声学单元,如在英语中采用音素,汉语中采用声韵母等。
声学模型中隐含马尔科夫模型的拓扑结构一般采用从左向右的三状态结构,每一个状态上都有一个指向自身的弧,如图所示,表示利用三状态模型对音素 / t / 的建模 。
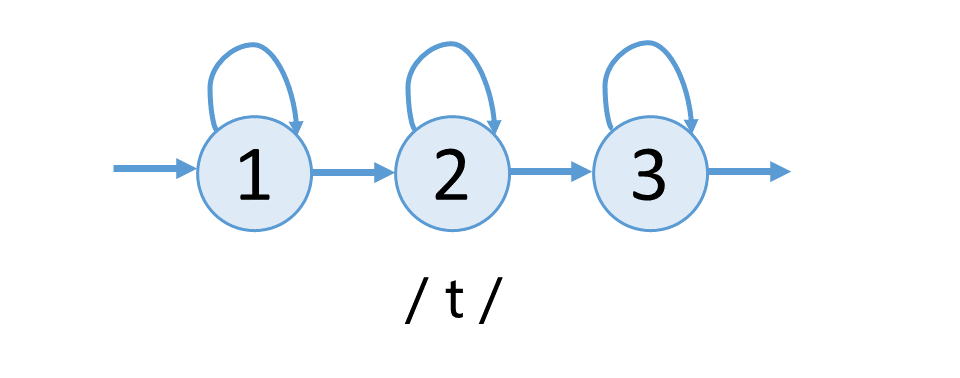
由于连续语音中具有协同发音的现象,故需要对前后三个音素共同考虑,称为三音子(Triphone)模型。引入三音子后,将引起隐含马尔科夫模型数量的急剧增加,所以一般会对状态进行聚类,聚类后的状态称为 Senone。
语音识别任务中的声学特征矢量取值是连续的,为了消除量化过程造成的误差,所以考虑使用连续概率密度函数来对特征矢量对状态的概率进行建模。混合高斯模型(Gaussian Mixture Models,GMM)可以对任意的概率密度函数进行逼近,所以成为了建模的首选。
邓力等将深度学习引入语音识别的声学建模中,用深度神经网络对声学特征矢量和状态的关系进行建模 ,极大地提升了语音识别的准确率,此后深度学习在语音识别声学建模上的应用开始蓬勃发展,如利用声学特征矢量上下文关系的循环神经网络(Recurrent Neural Networks,RNN)及其特殊情况长短时记忆网络(Long Short-term Memory,LSTM)等。
语言模型
语言模型可以表示某一字序列发生的概率。语音识别中常用的语言模型是 N 元文法(N-Gram),即统计前后 N 个字出现的概率。N 元文法假定某一个字出现的概率仅与前面 N-1 个字出现的概率有关系。
设现在有一字序列 W=(w1,w2,w3,⋯,wU) ,则其发生概率可以被分解为如下形式:
但是,这样的概率无法统计。根据马尔科夫假设,则只需考虑前 N 个字符发生条件下的概率即可。假设 N=2 则有
再根据贝叶斯公式,可以得出某一个字在另一个字的条件下发生的概率
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1155
1155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









