










论文题目:Entity, Relation, and Event Extraction with Contextualized Span Representations
论文来源:EMNLP 2019 华盛顿大学, Google AI Language
论文链接:https://www.aclweb.org/anthology/D19-1585/
代码链接:https://github.com/dwadden/dygiepp
关键词:命名实体识别,关系抽取,事件抽取,BERT,图传播
这篇文章是基于[1]的,文章并没有讲太多细节,读起来不是很透彻,后续会阅读文献[1]。
文献[1]提出了DyGIE框架,论文解读见:https://blog.csdn.net/byn12345/article/details/105670780
1 摘要
本文提出了DyGIE++模型,通过对捕获了局部信息(句内)和全局信息(跨句)的text spans进行枚举、精炼、打分,可以处理命名实体识别(NER)、关系抽取(RE)和事件抽取(EE)共3种信息抽取(IE)任务。
在4个数据集上进行实验,本文的模型在3种信息抽取任务上均实现了state-of-the-art。
作者进行了实验对比了不同的构建span表示的方法,和上下文相关的方法例如BERT,捕获了同一句子或相邻句子中的实体关系,表现较好。
2 引言
整合全局的(跨句)信息或非局部的短语间的依赖信息,有助于进行信息抽取任务(NER, RE, EE, 共指消解)。例如,共指关系的知识有助于对分类困难的实体进行分类。在事件抽取(EE)任务中,句中实体的信息有助于事件触发词的预测。
为了建模全局的上下文信息,先前的工作使用pipeline模型来抽取句法特征、篇章特征和其他人为设计的特征作为预测模型的输入,并使用了神经网络作为打分函数。近期的端到端的方法通过动态地构建span组成的图(图中的边对应于特定任务的关系),实现了很好的效果。
与此同时,基于上下文的语言模型在许多自然语言处理任务中均取得了成功。这些模型有的突破了句子边界的限制,对上下文进行了建模。例如,BERT中transformer架构的注意力机制可以捕获相邻句子的tokens间的关系。
本文基于先前的span-based信息抽取(IE)方法[1],研究了多种方法,将全局的上下文信息整合成统一的处理多任务的IE框架DyGIE++。模型结构如图1所示,枚举候选的text spans并使用基于上下文的语言模型对其编码,然后在text span图上进行特定任务的消息更新。

3 任务和模型
本文的DyGIE++框架对span-based模型进行扩展,以用于实体抽取和关系抽取:(1)将EE作为附加任务,并在连接了事件触发词和其元素(arguments)的图上进行span的更新传播;(2)在多句BERT编码的顶部构建span的表示。
3.1 任务定义
输入是一个文档,表示成tokens的序列 D D D,本文的模型根据这一序列构建了spans S = { s 1 , . . . , s T } S={\{s_1, ..., s_T}\} S={s1,...,sT},是文档中所有可能短语的集合。
(1)命名实体识别
对每个span s i s_i si预测最合适的实体类型标签 e i e_i ei。
(2)关系抽取
为所有的span pairs ( s i , s j ) (s_i, s_j) (si,sj)预测最佳的关系类型 r i j r_{ij} rij。
对于本文使用的所有数据集,这里的关系针对的是在同一句子中的spans的关系。
(3)共指消解
对每个span s i s_i si预测出最合适的指称前件(coreference antecedent) c i c_i ci。
将共指消解任务作为一个辅助任务,用来提升用于3个主要任务的表示。
(4)事件抽取
涉及对命名实体、事件触发词、事件元素以及元素角色的预测。
为每个token d i d_i di分配一个标签 t i t_i ti,以进行事件触发词的预测。
对于每个触发词 d i d_i di,通过对所有的和 d i d_i di在同一句子中的spans s j s_j sj的元素角色 a i j a_{ij} aij进行预测,来为事件触发词 d i d_i di分配事件元素。
使用预测的实体作为候选的事件元素。
3.2 DyGIE++架构
图1展示DyGIE++模型架构的4个组成部分,更多细节见文献[1]。
(1)Token embedding
使用BERT和滑动窗口对token进行编码,将每个句子和该句周围距离 L L L范围内的邻居输入到BERT。
(2)Span enumeration
通过拼接表示左边和右边endpoints的tokens以及学习到的span width embedding,进行文本spans的枚举和构建。
(3)Span graph propagation
图结构是基于模型当前对于文档中spans间关系的最佳预测动态构建的。
每个span的表示 g j t g^t_j gjt是通过整合图中其邻居的span表示,并根据关系传播、事件传播和共指传播3种图传播的变型方法,进行更新的。
1)在共指传播中,span在图中的邻居是它可能的共指前件(coreference antecedents);
2)在关系传播中,邻居是在句子中和其相关的实体;
3)在事件传播中,邻居是事件触发词节点和事件元素角色节点,触发词节点向其可能的元素节点传递消息,元素节点也反过来向其可能的触发词节点传递消息。
整个过程是端到端的,模型同时学习如何识别spans间重要的连接以及如何在这些spans间共享信息。
在每次迭代过程 t t t中,模型为span s t ∈ R d s^t\in \mathbb{R}^d st∈Rd生成更新的 u x t ( i ) \mathbf{u}^t_x(i) uxt(i):
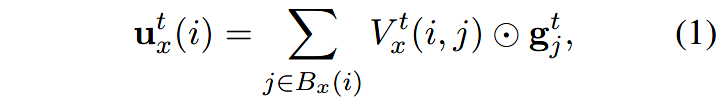
其中 ⊙ \odot ⊙表示元素级别的相乘; V x t ( i , j ) V^t_x(i, j) Vxt(i,j)是计算spans i i i和 j j j针对任务 x x x的相似度。
最终通过计算先前表示和当前更新的凸组合,并使用门函数赋予不同权重,得到更新后的span表示 g j t + 1 g^{t+1}_j gjt+1。
(4)多任务分类
将上下文的表示作为打分函数的输入,针对每个任务进行预测。使用2层的前向神经网络(FFNN)作为打分函数。
针对span g i g_i gi的触发词预测和命名实体预测,计算 F F N N t a s k ( g i ) FFNN_{task}(g_i) FFNNtask(gi)的值。
对于关系预测和元素角色预测,拼接相关的嵌入对,计算 F F N N t a s k ( [ g i , g j ] ) FFNN_{task}([g_i, g_j]) FFNNtask([gi,gj])的值。
4 实验
(1)数据集
ACE05, SciERC, GENIA, WLPC
(2)本文模型的变形
- BERT + LSTM:将预训练的BERT的嵌入输入到Bi-LSTM层中;
- BERT Finetune:针对目标任务使用有监督的微调的BERT。
针对每个变形,研究使用不同的针对特定任务的传播方法的有效性。
(3)实验结果
State-of-the-art Results:

表2展示了共指传播(CorefProp)增强了命名实体识别的性能。

表3展示了关系传播(RelProp)在预训练的BERT上增强了关系抽取的性能,但在fine-tuned的BERT上没有增强性能。这是因为所有的关系都是在一个句子内的,因此BERT可以很好地建模这些关系。

表4展示了事件抽取的结果,可以看出最佳的结果没有利用到任何的传播技术。作者认为事件传播没有起到作用是因为触发词和元素间的关系不是对称的。建模元素和触发词间高阶的交互关系作为未来的研究任务。

表6展示了两个变形的BERT模型在不同大小的上下文窗口设置下的结果。可以看出句子的窗口大小为3时,在所有关系抽取和事件抽取任务上表现效果最好。

5 总结
本文提出有效的且易于实施的IE(信息抽取)框架DyGIE++,可以用于多个IE任务。
文章研究了BERT嵌入和图传播方法针对IE任务,捕获上下文相关性的能力。研究表明,同时使用这两个方法比分别单独使用其中的一个效果要更好。BERT建模了有鲁棒性的多个句子的表示,图传播方法利用了和问题以及领域相关的结构关联。
未来工作:将这一框架扩展到其他的NLP任务中;研究其他方法,建模和EE有关的高阶的交互信息。
从表4中可以看出,对于事件抽取任务,不使用事件传播,模型的表现更好。作者认为事件传播没有起到作用是因为触发词和元素间的关系不是对称的。如何建模元素和触发词间高阶的交互关系仍需要继续研究。
参考文献
[1] Yi Luan, Dave Wadden, Luheng He, Amy Shah, Mari Ostendorf, and Hannaneh Hajishirzi. 2019. A general framework for information extraction using dynamic span graphs. In NAACL-HLT.















 402
402











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









