











论文题目:Few-shot Learning for Multi-label Intent Detection
论文来源:AAAI 2021
论文链接:https://arxiv.org/abs/2010.05256
代码链接:https://github.com/AtmaHou/FewShotMultiLabel
关键词:少样本学习(FSL);多标签分类(MLC);用户意图检测;核回归;BERT;元学习
文章目录
1 摘要
本文研究的任务是少样本的多标签分类,以用于用户意图检测。
SOTA方法:估计标签和实例的相关性分值,并设定阈值选择多个相关的意图标签。
本文:
(1)为了使用少量的数据得到恰当的阈值,作者首先在数据丰富的领域上学习到通用的阈值经验,然后通过基于非参数学习的校准,将阈值适应到少样本的领域。
(2)为了更好地计算标签和实例间的相关性分值,作者将标签名嵌入作为表示空间中的锚点(achor point),细化不同类的表示,使其彼此分离。
2 引言

1、任务的引出
(1)意图检测与多标签分类
意图检测是任务型对话系统的基本组成部分。这一任务可以看成是MLC问题,因为一个句子通常会有多个用户意图,如图 1所示。
(2)意图检测与少样本学习
意图检测缺乏训练数据,因为对话任务/领域变化迅速,而且新的领域通常只有很少的数据样本。可使用少样本学习的方法,像人类学习的方法一样,通过利用先验经验,从几个学习样例(通常一类有1或2个样本)中概括出来。
2、SOTA的多标签意图检测方法
现有的最佳方法聚焦于基于阈值的策略,分为两步:1)计算标签和实例的相关性分值;2)选取分值高于阈值的意图标签。相关性分值的计算以及阈值的求得这两个模块的质量和相互协调,对于MLC模型的性能非常重要。
在少样本场景下,多标签的设置为阈值的估计和相关性分值的计算带来了挑战。
(1)阈值
已有工作有调节到一个固定的阈值或者从数据中学习到阈值,但这些方法仅在学习样本充足的情况下有效。
原因:
- 在少样本领域,使用非常少的样本很难调节得到恰当的阈值。
- 由于领域差异(每个实例的标签数、分值密度、规模差异),很难将预学习的阈值直接转换。
(2)标签实例相关性分值
少样本学习通常使用基于相似度的方法,从相应的支持样本中得到标签的表示,计算标签和实例之间的相似性得到分值。
但这些基于相似度的方法不适用于多标签问题。
原因:
- 当实例有多个标签时,不同标签的表示可能从相同的支持样本中得到,使得不同标签的表示之间有混淆。
3、本文提出
本文研究的是多标签意图检测的少样本学习问题,提出新框架从阈值和label-instance相关性分值两个方面解决挑战。
(1)阈值
为了解决先验知识迁移和使用有限样本的领域自适应问题,作者提出元校准阈值(MCT)机制。首先在数据丰富的领域学习到通用的阈值经验(利用先验的领域知识),然后使用基于核回归的校准,将阈值适应到某个少样本领域中(利用新领域的知识)。
(2)相关性分值
为了解决相关性分值计算中的标签表示混淆的问题,受[1]启发,作者提出锚标签表示(ALR)以得到分离得比较好的标签表示。
ALR使用标签名的嵌入作为附加的锚点,并使用支持样本和相应的锚点表示每个标签。
以往的单标签的意图检测方法使用标签嵌入作为附加的特征,本文的标签嵌入可以有效地在度量空间分开不同的标签。
(3)两者的协调
为了更好地协调阈值的求得和label-instance相关性分值的计算,作者将Logit-adapting机制引入MCT,以实现自动地将阈值适应到不同的分值密度中。
4、贡献点
- 本文研究了任务型对话领域中意图检测的少样本多标签问题,也是在少样本多标签领域的较早的尝试。
- 本文提出了带有核回归和Logits Adapting的元刻度阈值(MCT)机制,同时利用了先验的领域经验和新的领域知识以估计阈值。
- 本文引入了锚标签表示以得到分离得比较好的标签表示,以实现更好的label-instance相关性分值计算。
3 问题定义
1、多标签分类
大多数情况下,多标签模型学习到一个实值函数 f : X → Y f: \mathcal{X}\rightarrow \mathcal{Y} f:X→Y, f ( x , y ) f(x, y) f(x,y)表示label-instance相关性分值,反映了标签 y y y是实例 x x x的标签的可信度。则多标签分类器可以表示成 h ( x ) = { y ∣ f ( x , y ) > t , y ∈ Y } h(x) = {\{y | f(x,y) > t, y\in \mathcal{Y}}\} h(x)={y∣f(x,y)>t,y∈Y},其中 t t t是阈值。
2、少样本学习
少样本学习通常通过基于相似性的方法实现,模型首先在源领域上进行训练,然后不经过微调,直接用在目标领域的数据上。
每个目标域都给定一个请求集 x x x,模型通过可观察的有标签的支持集 S = { ( x i , y i ) i = 1 N S } S={\{(x_i, y_i)}^{N_S}_{i=1}\} S={(xi,yi)i=1NS},预测请求及中样本的标签 y y y。对于 N N N个标签(N-way)中的每个标签, S S S通常有 k k k个样本(K-shot)。
本文将每个请求实例定义为单词序列组成的用户发言 x = ( x 1 , x 2 , . . . , x l ) x=(x_1, x_2, ..., x_l) x=(x1,x2,...,xl)。模型使用多标签的支持集 S = { ( x i , Y i ) } i = 1 N S S = {\{(x_i, Y_i)}\}^{N_S}_{i=1} S={(xi,Yi)}i=1NS预测一组意图标签 Y = { y 1 , y 2 , . . . , y m } Y = {\{y_1, y_2, ..., y_m}\} Y={y1,y2,...,ym}。
4 方法

本文提出的框架如图 2所示,首先从支持集中聚合每个标签的表示,然后使用sentence-label相似性计算label-instance相关性分值。接着使用阈值将标签空间二分为相关的标签集和不相关的标签集。
该框架中,MCT在少样本的场景下估计出合理的阈值,ALR提供分离的标签表示。
4.1 用于少样本多标签意图检测的框架
给定一个请求句子 x x x和一个支持集 S S S,本文的框架预测出相关的标签集 Y Y Y:

其中 f f f计算label-instance相关性分值, t t t是阈值。
使用基于相似性的方法计算label-instance相关性分值:
首先,从支持集 S S S中得到每个标签的表示。假定 c i c_i ci是标签 y i y_i yi的向量表示,使用下式计算请求句 x x x和标签 y i y_i yi之间的相关性分值:
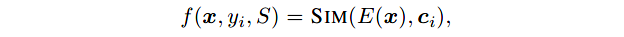
其中 E ( ⋅ ) E(\cdot) E(⋅)是嵌入函数;SIM是相似性函数,本文使用点乘相似性。
- 作者使用BERT作为嵌入函数,将句子中token的嵌入取平均得到该句的嵌入。
- 为了得到分离的比较开的标签表示,作者使用ALR得到 c i c_i ci。
阈值的计算:
然后,使用MCT,通过整合源领域的先验知识和目标领域的可观察样本的知识,估计出阈值 t t t。
4.2 元刻度阈值 MCT
在少样本的情况下,模型在不同的领域训练和测试,这些领域对阈值的选择往往有不同的偏好。
而且使用不同的阈值标志每个实例是很重要的,因为不同实例的标签数量不一样,并且不容实例的label-instance相关性分值的密度也不一样。
为了实现这些,本文的模型先是学习到领域通用的元阈值,然后对其进行校准,以适应于目标领域和特定的请求。
4.2.1 Meta Threshold with Logits-Adaptiveness
为了得到领域通用的阈值,作者提出元阈值 t m e t a t_{meta} tmeta,有自适应能力并且在多个领域联合优化。
对于自适应性:
作者提出Logit-Adaptive机制,可自动地使阈值适应于特定的请求和领域。
考虑到不同实例相关性分值的规模/密度不同,并且阈值一定是在最大值和最小值之间的,作者提出将阈值看做是最大分值和最小分值的一个插值:
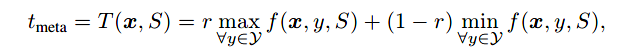
其中, r r r是从源领域中学习到的插值率。如图 3所示,基于插值的阈值可随着label-instance相似性分值的不同密度进行变化,和固定阈值相比更通用。这一机制在阈值和相似性分值之间起到了更好的调节作用。

4.2.2 Threshold Calibration with Kernel Regression
经过上述过程可学习到元阈值 t m e t a t_{meta} tmeta,该阈值对于不同的领域具有通用性,但是缺少领域特定的知识。因此,作者通过观察支持集估计出一个领域/请求特定的阈值 t e s t t_{est} test,并且使用该阈值校准元阈值。
然而,由于gloden thresholds的缺失,直接学习一个模型来估计阈值很难。因此,作者转而估计标签的数目并间接地推断出阈值。
估计标签数目:
采用核回归(KR)以利用领域特定的知识,进而估计标签数目。作为一个无参数的方法,KR可以应用于不可见的领域并且不需要微调。和其他的无参数回归方法(例如KNN回归)相比,KR可以利用所有的支持样本并且考虑到距离的影响。
给定支持集 S S S,作者将请求 x x x的标签数目 n n n估计为支持样本的加权平均标签数目,其中权重由请求样本和支持样本间的核相似性计算得到:
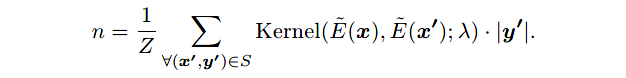
- Z Z Z是归一化参数;
- 使用高斯核: K e r n e l ( a , b ; λ ) = e x p ( − ( a − b ) 2 / λ ) Kernel(a, b; \lambda) = exp(-(a-b)^2 / \lambda) Kernel(a,b;λ)=exp(−(a−b)2/λ),其中 λ \lambda λ是带宽值;
- E ~ ( x ) \tilde{E}(x) E~(x)是特征抽取器,返回和句子 x x x的标签数目相关的特征向量。
本文中将和句子中意图数目有关的语言学特征定义为:句子长度、连词数目、谓词数目、标签符号数目、疑问代词数目,并使用一层MLP编码这些特征。
推断出阈值:
然后,作者从估计的标签数目 n n n中得到领域/请求特定的阈值 t e s t t_{est} test。
作者找到一个阈值 t e s t t_{est} test以过滤掉 x x x的 t o p − n top-n top−n个label-instance相关性分值。一个直观的想法是:直接使用第 ( n + 1 ) t h (n+1)_{th} (n+1)th个最大的分值作为阈值,这样大于该阈值的就有 n n n个分值,而 n n n正好是作者估计的该样本的标签数目。
但是这样的阈值是仅仅通过一个label-instance相关性分值得到的。因此,作者进一步改进,通过使用学习到的核权重直接估计阈值,以利用所有的相关性分值:
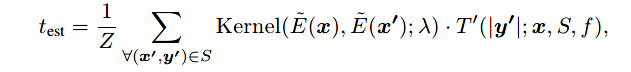
其中, T ′ ( n ; x , S , f ) T^{'}(n;x, S, f) T′(n;x,S,f)返回值是请求 x x x的第 ( n + 1 ) t h (n+1)_{th} (n+1)th个最大的label-instance相关性分值。
最终,我们使用请求特定的阈值 t e s t t_{est} test以校准领域通用的元阈值 t m e t a t_{meta} tmeta。对于请求 x x x,最终的阈值计算如下:
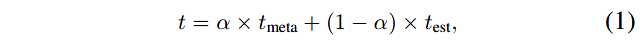
4.3 锚标签表示 ALR
为了高质量地建模label-instance相似性,标签表示应该做到:
- 互相之间可分性强;
- 能够充分表达相应类别的语义信息。
1、传统的少样本学习的标签表示
对于少样本学习,标签表示主要从支持集样本中学习得到。一个经典的想法是对所有支持样本的嵌入取平均,作为标签的表示。
**缺点:**但是在多标签的情况下,不同的标签可能有相同的支持样本,这种方法使得标签表示之间产生混淆和歧义,可分性变差。
2、使用锚表示标签
因此,作者提出使用标签特定的锚点表示标签,强化了不同类别间的差异性。
标签名称天然居然可分性并且包含特定类别的语义信息。因此,作者使用标签名的语义嵌入作为锚点,并使用锚点和支持样本两者表示每个标签。
对于标签 y i y_i yi,使用插值参数 β \beta β得到锚标签表示 c ~ i \tilde{c}_i c~i,其中 c i c_i ci是用支持样本得到的表示:
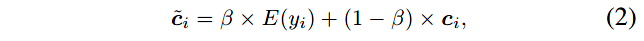
4.4 优化
使用sigmoid交叉熵损失用于MLC的训练:
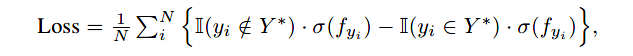
- N N N是标签数目;
- f y i = f ( x , y i , S ) f_{y_i} = f(x, y_i, S) fyi=f(x,yi,S)
- Y ∗ Y^* Y∗是真实的标签集
- I ( ⋅ ) \mathbb{I}(\cdot) I(⋅)是指示函数
- σ \sigma σ是sigmoid函数
由于使用标签数目选取阈值的过程是不可微的,作者在框架学习过程之前,使用 M L E ( n e s t , n g o l d ) MLE(n_{est}, n_{gold}) MLE(nest,ngold)的损失在源领域上预训练核的参数,例如带宽和MLP映射层。
这是个元学习过程,该过程学习了元阈值、核回归、相似性度量计算的元参数,以提升在不可见的少样本任务上的无参数学习,也就是learning to learn。
5 实验
1、数据集
使用了两个数据集,一个是公开数据集TourSG,一个是作者收集的新的多意图数据集StanfordLU。

少样本数据的构建:
为了模拟少样本的条件,作者将数据集重构成了少样本学习的形式。每个样本由一个请求句 ( x q , y q ) (x^q, y^q) (xq,yq)和相应的 K − s h o t K-shot K−shot支持集 S S S组成,实验数据如表 1所示。
和单标签分类问题不同,多标签的实例和多个标签相关联。不能保证在采样支持句子时每个标签都出现 K K K次。为了处理这个问题,作者使用Minimum-including算法近似构建了 K − s h o t K-shot K−shot支持集。围绕两个标准:
- 在支持集 S S S中,领域内的所有标签最少出现 K K K次;
- 如果任意一个 ( x , y ) (x,y) (x,y)对从 S S S中移除,至少有一个标签出现的次数少于 K K K次。
对于每个领域,作者采样 N s N_s Ns个不同的 K − s h o t K-shot K−shot支持集。对于每个支持集,采样 N q N_q Nq句子作为请求集。每个support-query-set对形成了一个few-shot episode。最终,对于每个领域,可得到 N s N_s Ns个episodes和 N s × N p N_s \times N_p Ns×Np个样本。
评估:
在不同的领域对模型进行交叉验证。每次选取一个目标领域用于测试,一个领域用于验证,其余领域当做源领域用于训练。
在每个few-shot episode使用F1分值进行评估,在讲所有episodes的F1值取平均作为最终的结果。
2、baselines
- TransferM:领域转换模型,由大型的预训练语言模型和一个多标签分类层组成。
- Multi-label Prototypical Network(MPN):基于相似性的少样本学习模型,使用原型网络计算sentence-label的相似性分值,并在验证集上使用固定的阈值进行微调。
- Multi-label Matching Network(MMN):在MPN的基础上使用了匹配网络,用于label-instance相关性分值的计算。
3、实验结果



6 总结
本文研究的是多标签意图检测的少样本学习问题。
少样本学习任务一般分为两步;1)求得阈值;2)计算label-instance相关性分值,若大于阈值则认为该实例有该标签。
针对本文的任务,作者对这两步分别进行了改进。
(1)针对阈值
从少样本学习的角度进行改进,提出元刻度阈值(MCT)。首先使用Logit-Adaptive机制,利用源领域的知识得到元阈值。然后使用KR,利用特定领域的知识,先估计出标签数目,再估计出特定领域的阈值。最后,用第二个得到的阈值对元阈值进行校准,得到最终的阈值。
(2)针对相关性分值
从多标签的角度进行改进,提出锚标签表示(ALR)。为了使得不同的标签表示具有较强的可分性,使用语义天然可分的标签名嵌入作为锚点,同时也使用支持样本表示标签。
参考文献
[1] Wang, G.; Li, C.; Wang, W.; Zhang, Y.; Shen, D.; Zhang, X.; Henao, R.; and Carin, L. 2018. Joint embedding of words and labels for text classification. In Proc. of the ACL, 2321– 2331.















 4107
4107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









