








Abstract
本文提出了一个框架DYGIE++,通过枚举、提炼和评分文本span来完成信息抽取任务,这些文本span旨在捕获局部和全局上下文。通过BERT的语境化嵌入在捕获相同或相邻句子中实体之间的关系方面表现良好,而动态span图更新建模长span的交叉句子关系。通过预测的共指链接传播span表示可以使模型能够消除具有挑战性的实体提及的歧义。
1.Instruction
共指关系的知识可以提供信息来帮助推断所提及的难以分类的实体的类型。本文的模型框架如figure 1 所示。
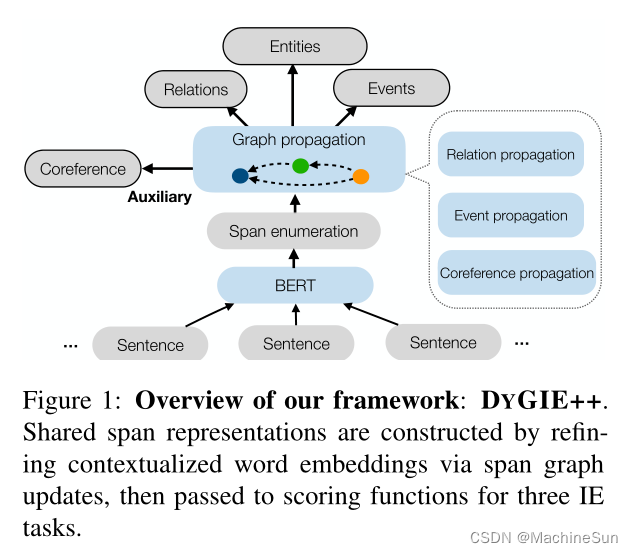
2. Model
2.1 Task definitions
输入:从序列中构造span
S
=
{
s
1
,
.
.
.
,
x
T
}
S=\{s_1,...,x_T\}
S={s1,...,xT}
NER涉及为每个span
s
i
s_i
si预测最佳实体标签类型
e
i
e_i
ei
RE任务设计所有span对
(
s
i
,
s
j
)
(s_i,s_j)
(si,sj)预测最佳关系类型
r
i
j
r_{ij}
rij本文研究的数据集,所有的关系都是同一句话中span之间的关系。
共指解析任务是预测每个span
s
i
s_i
si的最佳共指先行语
c
i
c_i
ci.
2.2 DyGIE++ Architecture
Token encoding 使用BERT作为编码器,并使用“滑动窗口”方法,将每个句子连通周围句子的大小为L的邻域一起提供给BERT。
Span Enumeration 文本span是通过串联表示其左和右的token以及学习span宽度嵌入来枚举的。
Span Graph Propagation 基于模型对文档中存在的span之间的关系的当前最佳猜测,动态地生成图结构。根据图传播的三种变型,通过在图中集成来自其邻居的span表示来更新每个span表示
g
j
t
g^t_j
gjt。在共指传播中,一个span在图中的邻居可能是它的共指先行语。在关系传播中,邻居是句子中的相关实体。
在每个迭代t处,该模型的span表示
s
t
∈
R
d
s^t\in R^d
st∈Rd:
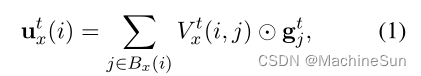
V
x
t
(
i
,
j
)
V_x^t(i,j)
Vxt(i,j)表示任务x下span i 和 j 的最相似度量。
3. Experiments
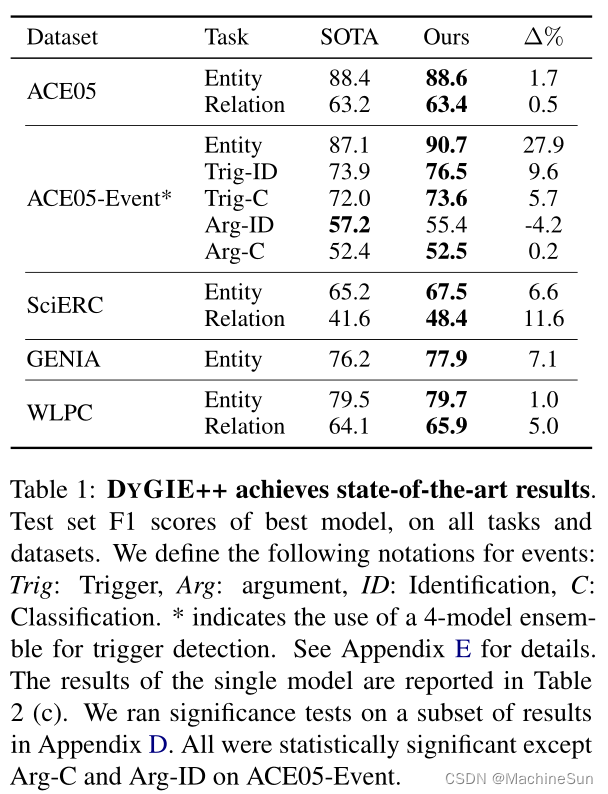
3.1 Result
3.2 Benefits of Graph Propagation
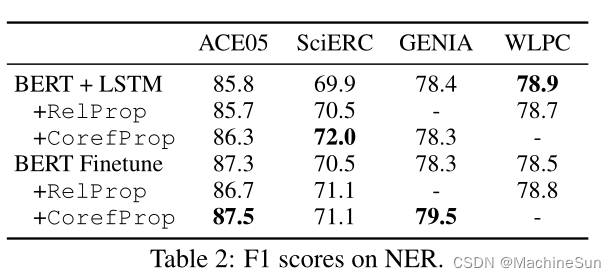
关系传播提高了BERT的关系抽取性能,但不能改善微调的BERT。作者认为,这是因为所有的关系都在一句话中,因此可以训练BERT来很好地建模这些关系。
4. 启示
- 对A general framework for information extraction using dynamic span graphs的升级操作,创新点在于运用了BERT和滑动窗口的方法获得cross-sentence表示,比起基础版的模型又多了一项事件抽取任务。
- 有必要将这两篇论文进行复现,是很好的baseline模型。

















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











