







FIN_WAIT1解析
前些天,一堆人在 TCPCopy 社区里闲扯蛋,有人提了一个问题:FIN_WAIT1 能持续多久?引发了一场讨论,期间我得到斌哥和多位朋友的点化,受益良多。
让我们热热身,通过一张旧图来回忆一下 TCP 关闭连接时的情况:
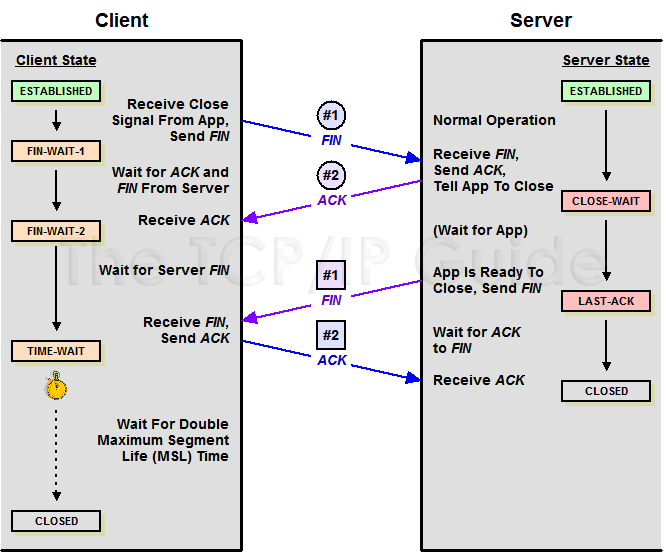
TCP Close
看图可知,主动关闭的一方发出 FIN,同时进入 FIN_WAIT1 状态,被动关闭的一方响应 ACK,从而使主动关闭的一方迁移至 FIN_WAIT2 状态,接着被动关闭的一方同样会发出 FIN,主动关闭的一方响应 ACK,同时迁移至 TIME_WAIT 状态。
回到开头的问题:FIN_WAIT1 能持续多久?一般情况下,服务器间的 ACK 确认是非常快的,以至于我们凭肉眼往往观察不到 FIN_WAIT1 的存在,不过网上也有很多案例表明在某些情况下 FIN_WAIT1 会持续很长时间,从而诱发问题。
最常见的误解是认为 tcp_fin_timeout 控制 FIN_WAIT1 的过期,从名字上看也很像,但实际上它控制的是FIN_WAIT2 的过期时间,官方文档是这样说的:
The length of time an orphaned (no longer referenced by any application)connection will remain in the FIN_WAIT_2 state before it is aborted at the local end. While a perfectly valid “receive only” state for an un-orphaned connection, an orphaned connection in FIN_WAIT_2 state could otherwise wait forever for the remote to close its end of the connection.
Cf. tcp_max_orphans
Default: 60 seconds
让我们通过一个实验来说明问题(服务端:10.16.15.107;客户端:10.16.15.109):
- 在服务端监听 1234 端口:「nc -l 1234」
- 在客户端连接服务端:「nc 10.16.15.107 1234」
此时客户端连接进入 ESTABLISHED 状态 - 在服务端拦截响应:「iptables -A OUTPUT -d 10.16.15.109 -j DROP」
- 在客户端开启抓包:「tcpdump -nn -i any port 1234」
- 在客户端通过「ctrl + c」断开连接。
此时客户端连接进入 FIN_WAIT1 状态
随时可以通过「netstat -ant | grep :1234」来观察状态,最终抓包结果如下:
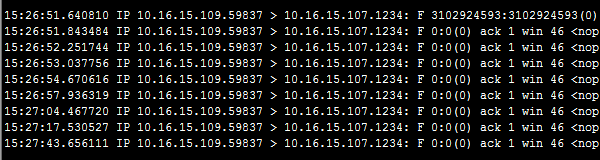
TCP Fin
第一个 FIN 是我们按「ctrl + c」断开连接时触发的,因为我们在服务端通过 iptables 拦截了发送给客户端的响应,所以对应的 ACK 被丢弃,随后客户端执行了若干次重试。
此外,通过观察时间我们还能发现,第一次重试在 200ms 左右;第二次是在 400ms 左右;第三次是在 800ms 左右;以此类推,每次的时间翻倍。
实际上,控制客户端重发FIN的关键参数是 tcp_orphan_retries(此时客户端处于FIN_WAIT1状态),官方文档是这样说的:
This value influences the timeout of a locally closed TCP connection, when RTO retransmissions remain unacknowledged. See tcp_retries2 for more details.
The default value is 8.If your machine is a loaded WEB server, you should think about lowering this value, such sockets may consume significant resources. Cf. tcp_max_orphans.
如果你用 sysctl 查询 tcp_orphan_retries 是 0,那么实际等同于 8,看代码:
/* Calculate maximal number or retries on an orphaned socket. */
static int tcp_orphan_retries(struct sock *sk, int alive)
{
int retries = sysctl_tcp_orphan_retries; /* May be zero. */
/* We know from an ICMP that something is wrong. */
if (sk->sk_err_soft && !alive)
retries = 0;
/* However, if socket sent something recently, select some safe
* number of retries. 8 corresponds to >100 seconds with
* minimal RTO of 200msec. */
if (retries == 0 && alive)
retries = 8;
return retries;
}
于是乎我们可以得出结论,如果你的系统负载较重,有很多 FIN_WAIT1,那么可以考虑通过降低 tcp_orphan_retries 来解决问题,具体设置多少视网络条件而定。
问题分析到这里原本可以完美谢幕,但是因为 TCP 有缺陷,导致 FIN_WAIT1 可能被用来发起 DoS 攻击,所以我们就再唠十块钱儿的,看看到底是怎么回事儿:
利用FIN_WAIT1的Dos攻击:
假设服务端上有一个大文件,攻击者连接服务端发起请求,但是却不接收数据,于是乎就造成一种现象:客户端接收队列满,导致服务端不得不通过「zero window probes」来循环检测客户端是否有可用空间,以至于 tcp_orphan_retries 也没有用,因为服务端活活被憋死了,发不出 FIN 来,从而永远卡在 FIN_WAIT1。演示代码如下:
#!/usr/bin/env python
import socket
import time
host = 'www.domain.com'
port = 80
path = '/a/big/file'
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((host, port))
sock.send("GET %s HTTP/1.0\r\nHost: %s\r\n\r\n" % (path, host))
time.sleep(1000)
说明:通常文件大小以 100K 为佳,具体取决于 tcp_rmem / tcp_wmem 的大小。
怎么办?病急乱投医,重启服务!可惜没用,因为 FIN_WAIT1 已经脱离的服务的管辖范围,所以重启服务是没有用的,如果一定要重启,你只能重启服务器!
好在内核已经考虑到了此类问题,它提供了 tcp_max_orphans 参数,用来控制 orphans 的最大值,需要注意的是,和用来控制 TIME_WAIT 的最大值的 tcp_max_tw_buckets 参数一样,除非你遇到了 DoS 攻击,否则最好不要降低它。
花絮:我曾经试图寻找一些工具来杀掉 FIN_WAIT1 连接,如果你要杀掉一个 TCP 连接,那么需要知道相应的 ACK 和 SEQ,然后才可以 RESET 连接。为了获取 ACK 和 SEQ,一些工具采用的是被动机制,它通过监听匹配的数据包来获取需要的数据,代表是 tcpkill;另一些工具采用的是主动机制,它通过伪造请求来获取需要的数据,代表是killcx,如果有兴趣的话不妨试试它们。
最后,再次感谢 TCPCopy 社区!如果你从本文学到些许知识,那么这份荣幸属于 TCPCopy社区,如果你在本文发现谬误之处,那么全因本人笨拙,还望不吝赐教。















 4万+
4万+












 到【灌水乐园】发言
到【灌水乐园】发言









学习了。现在这样子的dddos都有软件可以防御了。
引用:
假设服务端上有一个大文件,攻击者连接服务端发起请求,但是却不接收数据,于是乎就造成一种现象:客户端接收队列满,导致服务端不得不通过「zero window probes」来循环检测客户端是否有可用空间,以至于 tcp_orphan_retries 也没有用,因为服务端活活被憋死了,发不出 FIN 来,从而永远卡在 FIN_WAIT1
问题:
如果在这样的情况下,客户端不recv服务器的数据,服务器send会造成EAGAIN错误返回给调用层,这里只需要有逻辑处理EAGAIN等待次数。如果在一定次数下对方还是窗口为0,服务器代码可以主动清理这个socket fd。
这样的话,就不会有过多的死链的问题。
不知道我的描述是否正确,请教博主是否可以这样理解?
你的想法可以实践一下,首先每次send 是发送到本地tcp 栈里面,所以开始你是成功的。 到了最后本地队列满了,epoll 就不会主动通知你可写了。 最关键是关闭socket, 正常情况的close 没办法避免这个问题,但是可以用丢弃数据的办法来关闭socket 避免fin_wait_1 情况,这个在群里讨论的时候,我已经说过了。
有个问题:前面说“客户端连接进入 FIN_WAIT1 状态”,后面又说“如果你的服务器负载较重,有很多 FIN_WAIT1”,是不是矛盾了。
按博主实验中的情况,是客户端主动断开连接进入了 FIN_WAIT1 状态,并不是服务端。此时客户端等待服务端发送ack,由于服务端通过 iptables 拦截了发送给客户端的响应,此时会导致客户端一直停留在 FIN_WAIT1 状态吧?为何又说“服务器负载较重,有很多 FIN_WAIT1”呢?不是很明白这其中的逻辑。
我的行文好像不太一致,导致你迷惑了,FIN_WAIT1 即可能出现在服务端,也可能出现在客户端,关键看哪一端主动关闭连接。常见的如 Nginx 服务器,如果使用的是短连接,那么服务端会主动关闭连接,如果使用的是长连接,那么可能就是客户端主动关闭连接了。