







特征相似度计算是数据分析和机器学习中的核心任务,用于量化两个对象(如文本、图像或数值向量)之间的相似程度。以下是常用的方法分类及其原理:
一、基于距离的相似度计算
-
欧氏距离
- 原理:计算多维空间中两点间的绝对距离,距离越小相似度越高。
- 公式:
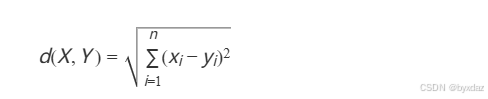
- 范围:[0,1],值越大,说明d越小,也就是距离越近,则相似度越大。
- 适用场景:适用于稠密且连续的数值型数据,需保证各维度量纲一致。
-
曼哈顿距离
- 原理:通过各维度差的绝对值之和度量距离,适合高维稀疏数据。
- 公式:
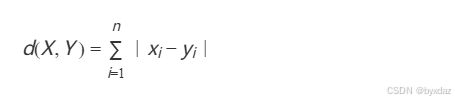
- 范围:[0,1],同欧式距离一致,值越小,说明距离值越大,相似度越大。
-
明可夫斯基距离
- 原理:欧氏距离和曼哈顿距离的推广,通过参数p调节距离计算方式(如p=2时为欧氏距离)。
- 公式:
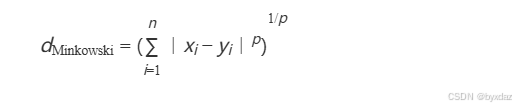
- 特点:
欧氏距离(p=2)和曼哈顿距离(p=1)的推广。
p→∞ 时退化为切比雪夫距离。
二、基于向量夹角的相似度计算
- 余弦相似度
- 原理:通过向量夹角的余弦值衡量相似性,对向量长度不敏感。
- 公式:

- 范围:[-1,1],值越大,相似度越高。
- 适用场景:适用于文本分类、推荐系统等高维稀疏数据。
三、基于统计相关性的相似度计算
- 皮尔逊相关系数
- 原理:衡量两个变量间的线性相关性,取值范围为[-1,1]。
- 公式:
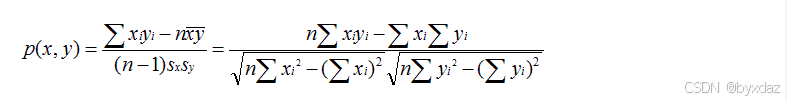
sx, sy是 x 和 y 的样品标准偏差。 - 范围:[-1,1],绝对值越大,说明相关性越强,负相关对于推荐的意义小。
- 特点:对数据中心化处理,可视为去中心化后的余弦相似度。
四、面向高维数据的优化方法
-
向量空间模型(VSM)
- 原理:将对象映射为特征向量,通过向量间距离或夹角计算相似度,常用于文本检索。
-
基于哈希的相似度计算(如MinHash)
- 原理:通过哈希函数将高维数据映射到低维空间,保留原始相似性,适用于大规模数据去重和近邻搜索。
五、方法选择建议
- 数值型数据:优先考虑欧氏距离或皮尔逊系数。
- 高维稀疏数据(如文本):使用余弦相似度或向量空间模型。
- 实时或大规模数据处理:采用哈希方法(如MinHash)降低计算复杂度。



















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











