







 本文介绍了C++中的几种容器,包括vector、deque、list和queue的特点及适用场景。重点讲解了关联容器set、multiset、map和multimap的使用,包括插入、删除、排序和查找操作,以及multimap的具体示例。同时提到了无序关联容器,如unordered_set和unordered_map,它们基于哈希表提供快速的查找和操作速度。
本文介绍了C++中的几种容器,包括vector、deque、list和queue的特点及适用场景。重点讲解了关联容器set、multiset、map和multimap的使用,包括插入、删除、排序和查找操作,以及multimap的具体示例。同时提到了无序关联容器,如unordered_set和unordered_map,它们基于哈希表提供快速的查找和操作速度。
容器:
vector
vector是数组的一种表示, 可以动态的改变vector对象的长度, 提供了对元素的随机访问, 在尾部添加和删除元素的时间是固定的, 但是在头部或中间插入和删除元素的复杂度为线性时间.
vector还是可反转容器(reversible container)概念的模型. 增加了两个类方法rbegin()和rend(), 前者返回一个指向反转序列的第一个元素的地带器, 后者返回反转序列的超尾迭代器.
deque
deque模板类(在deque头文件中声明)表示双端队列(double-ended queue), 其实现类似于vector容器, 支持随机访问, 主要区别在于, 从deque对象的开始位置插入和删除元素的时间是固定的, 而不像vector中那样是线性时间的. 所以如果多数操作发生在序列的起始和结尾处, 应考虑使用deque数据结构.
list
list模板类(在list头文件中声明)表示双向链表. 除了第一个元素和最后一个元素外, 每个元素都与前后的元素相连接, 这意味着可以双向遍历链表. list在链表中任意位置进行插入和删除的时间都是固定的. vector强调的是通过随机进行访问, list强调的是元素的快速插入和删除.
list里提供了一些列的方法, 以方便使用
unique(): 用来删除重复的元素
queue
queue模板类(在头文件queue中)是一个适配器类.
关联容器
set, multiset, map, multimap
set
首先看一下set集合的简单使用, 用到里set一些特性, set集合会默认对存入的数据进行排序, 并且set集合里的数据不能有重复的, 其中还用到了set的并集, 交集, 以及一些常用的方法:
#include <iostream>
#include <string>
#include <set>
#include <algorithm>
#include <iterator>
int main()
{
using namespace std;
const int N = 6;
string s1[N] = {"buffoon", "thinkers", "for", "heavy", "can", "for"};
string s2[N] = {"metal", "any", "food", "elegant", "deliver", "for"};
// 使用s1中的元素初始化set集合
set<string> A(s1, s1 + N);
set<string> B(s2, s2 + N);
ostream_iterator<string, char> out(cout, " ");
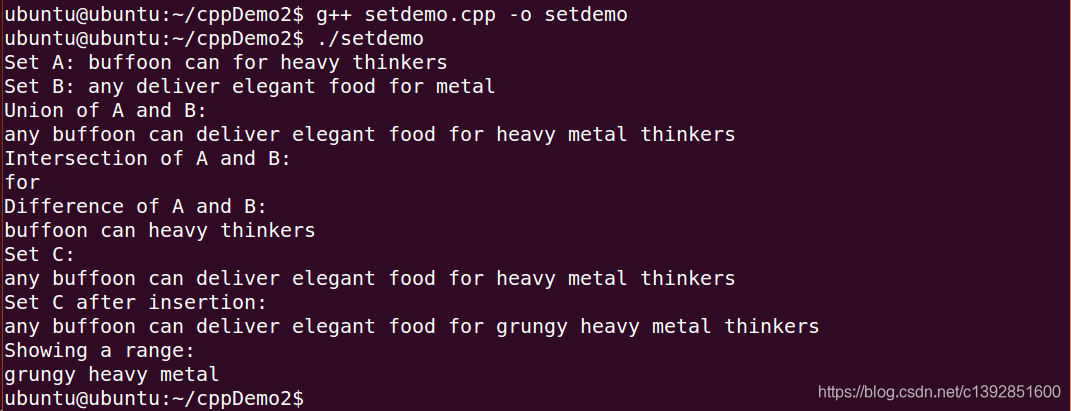
cout << "Set A: ";
copy(A.begin(), A.end(), out);
cout << endl;
cout << "Set B: ";
copy(B.begin(), B.end(), out);
cout << endl;
cout << "Union of A and B:\n";
// 取并集
set_union(A.begin(), A.end(), B.begin(), B.end(), out);
cout << endl;
cout << "Intersection of A and B:\n";
// 取交集
set_intersection(A.begin(), A.end(), B.begin(), B.end(), out);
cout << endl;
cout << "Difference of A and B: \n";
// 取A,B中不同的
set_difference(A.begin(), A.end(), B.begin(), B.end(), out);
cout << endl;
set<string> C;
cout << "Set C:\n";
// 取A, B的并集, 并复制给C, 注意set中不允许有重复的数据
set_union(A.begin(), A.end(), B.begin(), B.end(), insert_iterator<set<string> >(C, C.begin()));
copy(C.begin(), C.end(), out);
cout << endl;
string s3("grungy");
C.insert(s3);
cout << "Set C after insertion:\n";
copy(C.begin(), C.end(), out);
cout << endl;
cout << "Showing a range:\n";
// lower_bound返回第一个不小于该元素的迭代器, upper_bound返回第一个大于该元素的迭代器
copy(C.lower_bound("ghost"), C.upper_bound("spook"), out);
cout << endl;
return 0;
}程序运行结果如下:
multimap
multimap的键和值的类型不同, 且同一个键可能与多个值关联.
具体例子: 创建一个multimap对象, 其中键的类型为int, 值得类型为string:
multimap<int, string> codes;第三个模板参数是可选的, 指出用于对键进行排序的比较函数或对象. 默认情况下, 将使用模板less<>作为参数.
为将信息结合在一起, 实际的值类型将键类型和数据类型结合为一对. 为此, STL使用模板类pair<class T, class U>将这两种值存储到一个对象中. 如果keytype是键类型, 而datatype是存储的数据类型, 则值类型为pair<const keytype, datatype>. 例如: 前面声明的codes对象的值类型为pair<const int, string>.
具体实际的例子: 假设要用区号作为键来存储城市名, 则一种方法是创建一个pair, 再将其插入codes里:
pair<const int, string> item(123, "shanghai");
codes.insert(item);也可以使用一条语句创建匿名pair对象并将它插入:
codes.insert(pair<const int, string>(123, "shanghai"));因为数据项是按键排序的, 所以不需要指出插入的位置.
对于pair对象, 可以使用first和second成员来访问其两个部分:
pair<const int, string> item(123, "shanghai");
cout << item.first << " " << item.second << endl;multimap的相关函数:
1. count()接收键作为参数, 并返回具有该键的元素的数目
2. lower_bound() 和 upper_bound()将键作为参数, 前者返回集合中第一个不小于该键的元素, 后者返回集合中第一个大于该键的元素.
3. equal_range()用键作为参数, 且返回两个迭代器, 他们表示的区间与该键匹配. 为返回两个值, 该方法将它们封装在一个pair对象中, 这里pair的两个模板参数都是迭代器, 例如:
pair<multimap<KeyType, string>::iterator, multimap<KeyType, string>::iterator> range = codes.equal_range(123);
cout << "Cities with area code 123: " << endl;
std::multimap<KeyType, std::string>::iterator it;
for(it = range.first; it != range.second; ++it)
cout << (*it).second << endl;上面这段代码打印出codes对象中区号为123的所有城市.
在声明中可使用C++11自动类型推断功能, 所以上面的代码可以简化为:
auto range = codes.equal_range(123);
cout << "Cities with area code 123: " << endl;
for(auto it = range.first; it != range.second; ++it)
cout << (*it).second << endl;来看一个完整的例子:
// multmap.cpp
#include <iostream>
#include <string>
#include <map>
#include <algorithm>
typedef int KeyType;
typedef std::pair<const KeyType, std::string> Pair;
typedef std::multimap<KeyType, std::string> MapCode;
int main()
{
using namespace std;
MapCode codes;
codes.insert(Pair(415, "San Francisco"));
codes.insert(Pair(510, "Oakland"));
codes.insert(Pair(718, "Staten Island"));
codes.insert(Pair(718, "Brooklyn"));
codes.insert(Pair(415, "San Rafael"));
codes.insert(Pair(510, "Berkeley"));
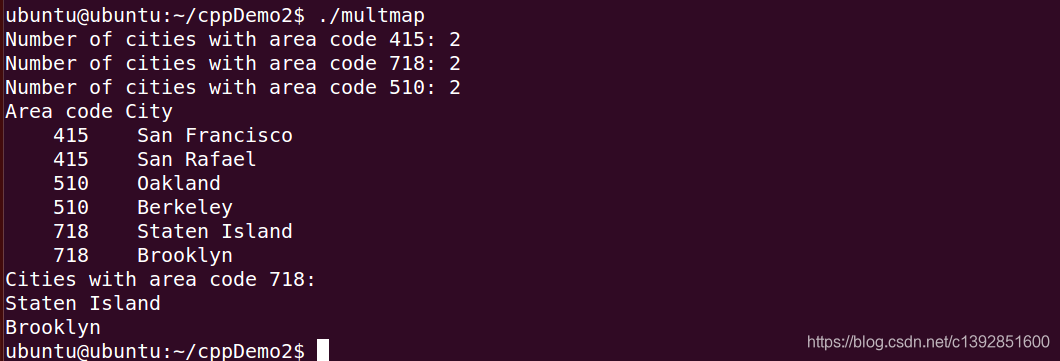
cout << "Number of cities with area code 415: " << codes.count(415) << endl;
cout << "Number of cities with area code 718: " << codes.count(718) << endl;
cout << "Number of cities with area code 510: " << codes.count(510) << endl;
cout << "Area code City\n";
MapCode::iterator it;
for(it = codes.begin(); it != codes.end(); ++it)
cout << " " << (*it).first << " " << (*it).second << endl;
pair<MapCode::iterator, MapCode::iterator> range = codes.equal_range(718);
cout << "Cities with area code 718:\n";
for(it = range.first; it!= range.second; ++it)
cout << (*it).second << endl;
return 0;
}
程序运行结果为:
无序关联容器
与关联容器一样, 无序关联容器也将值和键关联起来, 并使用键来查找值. 但底层的差别在于, 关联容器是基于树结构的, 而无序关联容器是基于数据结构哈希表的, 这旨在提高添加和删除元素的速度和提高查找算法的效率, 共有4中无序关联容器, 分别是: unordered_set, unordered_multiset, unordered_map, unordered_multimap

















 1494
1494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









