







 本文探讨了机器阅读理解在自然语言处理中的重要性,特别是在文本问答领域的应用。研究了近年来的发展趋势,包括模型结构的改进、性能的提升以及面临的挑战。作者提出了一系列创新方法,如强化助记阅读器、注意力指导的答案蒸馏、阅读+验证架构、检索-阅读-重排序网络和多类型-多跨度网络,以解决模型效率、无答案问题、开放域问答和离散推理等挑战。文章最后展望了未来的研究方向,包括常识推理、模型可解释性和实时性等。
本文探讨了机器阅读理解在自然语言处理中的重要性,特别是在文本问答领域的应用。研究了近年来的发展趋势,包括模型结构的改进、性能的提升以及面临的挑战。作者提出了一系列创新方法,如强化助记阅读器、注意力指导的答案蒸馏、阅读+验证架构、检索-阅读-重排序网络和多类型-多跨度网络,以解决模型效率、无答案问题、开放域问答和离散推理等挑战。文章最后展望了未来的研究方向,包括常识推理、模型可解释性和实时性等。

作者丨胡明昊
学校丨国防科技大学博士生
研究方向丨机器阅读理解
引言
文本问答是自然语言处理中的一个重要领域,随着一系列大规模高质量数据集的发布和深度学习技术的快速发展,文本问答技术在近年来引起了学术界与工业界的广泛关注。如图 1 所示,近几年文本问答相关论文数量增长迅速,同时问答任务的种类也越来越多样化。
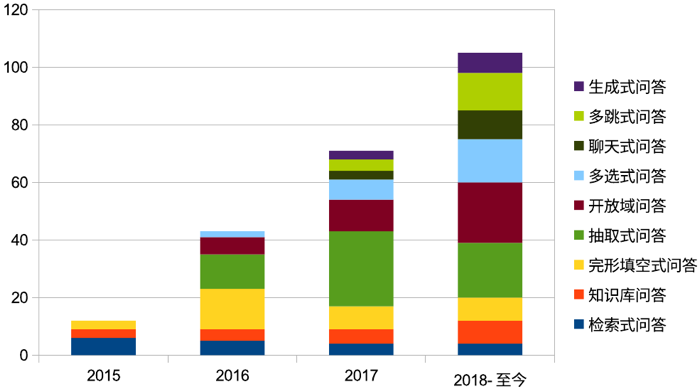
▲ 图1. 近年来基于深度学习的文本问答学术论文数量随年份变化情况统计(数据统计于ACL、EMNLP、NAACL、NIPS、AAAI等各大顶级学术会议)
机器阅读理解(Machine Reading Comprehension)是文本问答的一个子类,旨在令机器阅读并理解一段自然语言组成的文本,并回答相关问题。通过这种任务形式,我们可以对机器的自然语言理解水平进行评估,因此该任务具有重要的研究价值。
早期的阅读理解研究受限于数据集规模以及自然语言处理技术的发展,进展较为缓慢。直到 2015 年,谷歌发布首个大规模完形填空类阅读理解数据集 CNN/Daily Mail [1],引发了基于神经网络的阅读理解研究热潮。2016 年,SQuAD 数据集 [2] 被斯坦福大学发布,并迅速成为了抽取式阅读理解的基准测试集。
随后至今,机器阅读理解领域发展迅速,各类任务如开放域式、多选式、聊天式和多跳式等不断涌现。此外,阅读理解模型性能也不断刷新记录,在 SQuAD 数据集上甚至达到了超越人类的性能指标,如图 2 所示。
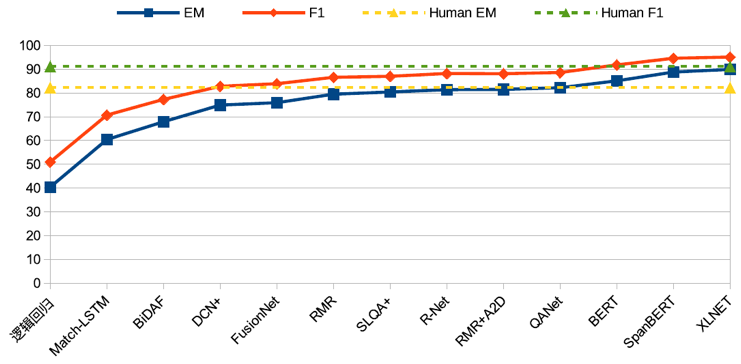
▲ 图2. SQuAD排行榜上代表性模型性能走势图
尽管取得了如此成就,机器阅读理解仍然面临着许多挑战,如:1)当前方法的模型结构和训练方法中存在着制约性能的问题;2)当前具备顶尖性能的集成模型在实际部署时效率低下;3)传统方法无法有效处理原文中找不到答案的情况;4)当前大部分模型是针对单段落场景设计的,无法有效扩展至开放域问答;5)当前大部分模型无法有效支持离散推理和多答案预测等情况。
针对上述存在的挑战,本文从以下五个方面开展研究:
强化助记阅读器(Reinforced Mnemonic Reader)
针对抽取式阅读理解任务,我们提出了强化助记阅读器,如图 3 所示。
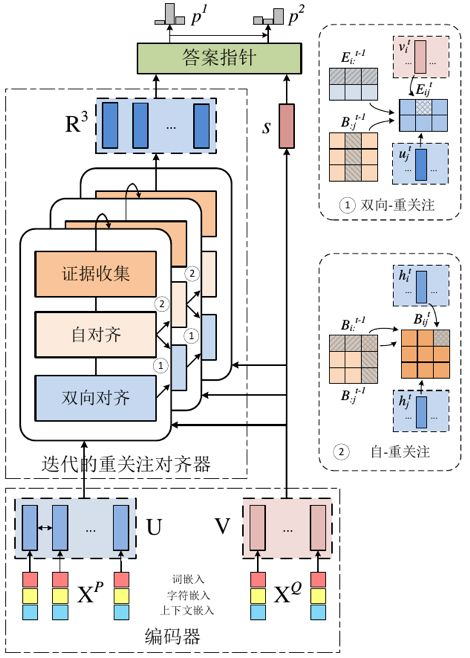
▲ 图3. 强化助记阅读器总体架构示意图
该模型主要包含两点改进。第一,我们提出一个重关注机制(re-attention),该机制通过直接访问历史注意力来精炼当前注意力的计算,以避免注意力冗余与缺乏的问题。第二,我们在训练时采用动态-评估的强化学习(dynamic-critic reinforcement learning)方法,该方法总是鼓励预测一个更被接受的答案来解决传统强化学习算法中的收敛抑制问题。在 SQuAD1.1 和两个对抗数据集上的实验显示了我们的模型取得了提交时的先进性能。
注意力指导的答案蒸馏方法(Attention-Guided Answer Distillation)
针对当前
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 231
231

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









