







 本文介绍了Physics Informed Neural Networks(PINN)的概念和应用,指出PINN是一种融合物理知识与数据驱动的科学机器学习方法。PINN通过神经网络解决与偏微分方程相关的问题,利用损失函数来逼近PDE的解。文章讨论了PINN的历史、与传统数值方法的对比、优缺点以及潜在的应用,如流体力学和传染病模型。PINN的优势在于它可以融合数据与物理知识,但也面临计算效率和精度的挑战。文章还探讨了PINN与传统有限差分方法的融合以及浅层网络的应用,展示了PINN在非典型问题中的潜力。
本文介绍了Physics Informed Neural Networks(PINN)的概念和应用,指出PINN是一种融合物理知识与数据驱动的科学机器学习方法。PINN通过神经网络解决与偏微分方程相关的问题,利用损失函数来逼近PDE的解。文章讨论了PINN的历史、与传统数值方法的对比、优缺点以及潜在的应用,如流体力学和传染病模型。PINN的优势在于它可以融合数据与物理知识,但也面临计算效率和精度的挑战。文章还探讨了PINN与传统有限差分方法的融合以及浅层网络的应用,展示了PINN在非典型问题中的潜力。

©PaperWeekly 原创 · 作者 | zwqwo
单位 | 某知名券商计算机行业研究员
研究方向 | 关注国产CAD、CAE等工业软件发展

从无网格方法到内嵌物理知识的神经网络
内嵌物理知识神经网络 (Physics Informed Neural Network,简称 PINN) 是一种科学机器在传统数值领域的应用方法,特别是用于解决与偏微分方程 (PDE) 相关的各种问题,包括方程求解、参数反演、模型发现、控制与优化等。
先简单概括,PINN 的原理就是通过训练神经网络来最小化损失函数来近似 PDE 的求解,所谓的损失函数项包括初始和边界条件的残差项,以及区域中选定点(按传统应该称为“配点”)处的偏微分方程残差。训练完成后进行推断(Inference)就可以得到时空点上的值了。
这个想法也不是很新奇,通常而言,数值分析类教材中接触得更多的是有限差分法、有限元、有限体积法等的基于网格的方法。还存在与基于网格方法相对的一类方法,也就是所谓无网格方法,在其中不难发现 PINN 的原型(Prototype),比如一种最简单的基于强形式径向基函数的无网格方法 Kansa 法。下面先简单介绍这个方法的原理,考虑这样一个两点边值问题:
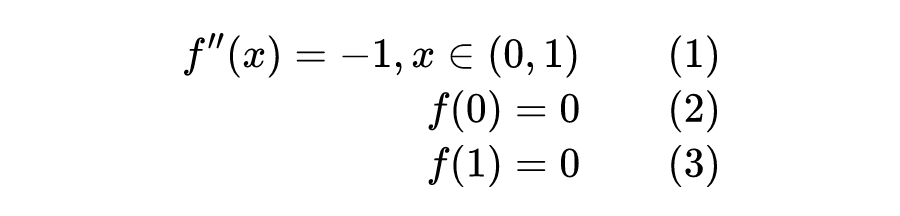
Kansa 法直接假设 有以下的形式:
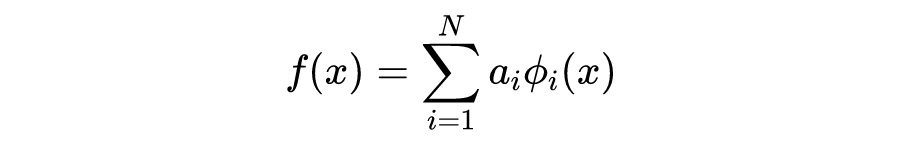
其中 是基函数,通常会选取某个径向基函数(Radial Basis Function,RBF 函数)的平移。那么在 区间上选取 个不同的配点 ,这些点并不需要处于特定位置。分别得到关于系数 的方程:
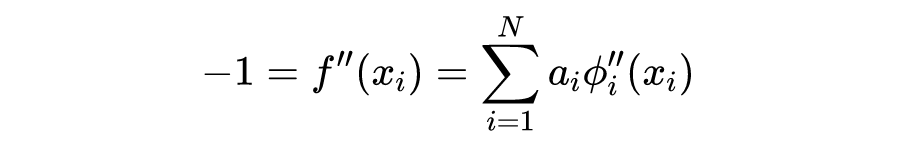
边值上的两点满足:
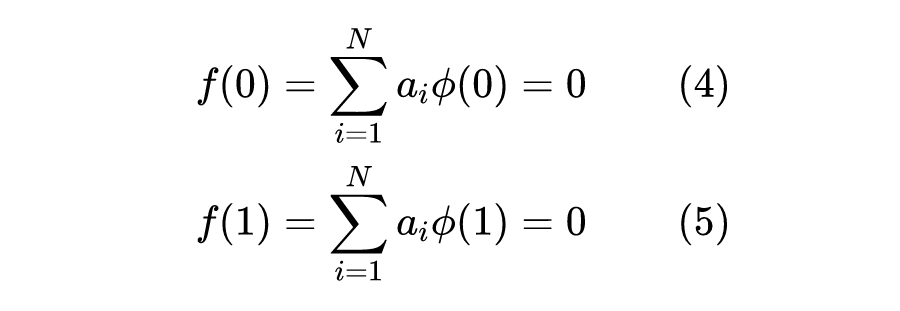
这样,一共得到了 个关于 个待定系数 的线性方程组,通过求解线性组,就可以逼近方程的逼近解了。定义 为 RBF,当选取 时,其实已经用到了一种浅层神经网络,也就是 RBF-net。
当然了,结果大家都知道,浅层神经网络在学习复杂的特征时可能会力不从心,网络宽度的增加也可能会使线性系统变得非常病态,基函数的超参选取是个问题,配点的选择当然也有讲究,无网格法有无网格法的解决方式。但如果要从神经网络,也就是 PINN 这条路子上走的话,将单层的 RBF-net 增加为多层感知机(MLP)就是件非常自然的事情了。
上面的基展开方法也可以延伸至一般伪谱方法。从数据的角度看,所谓的基就是特征,既然这种线性表征是可行的,那么利用神经网络来进行非线性表征也挺合理。
下面开始正式介绍 PINN,写得稍微正式一点,对于微分方程:
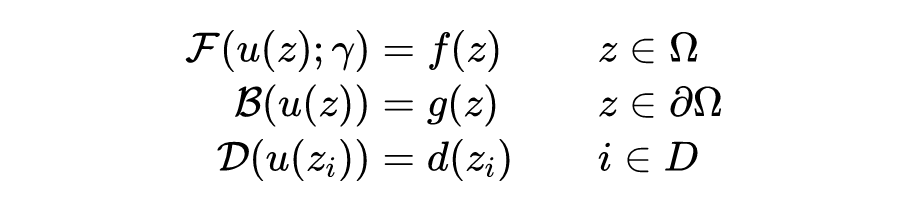
其中:
是包含了空间和时间的坐标;
表示方程的解;
是方程所在的区域;
算子描述了控制方程;
是控制方程的参数;
算子描述了初值或者边界条件;
算子描述了观测数据的方式;
是观测数据指标集。
相比传统微分方程数值求解的描述,这里多出了第三行式子,也就是对于数据的使用,这也是 PINN 的特点之一。当然,这三个条件也不一定全都出现,比如边界条件消失,从传统数值方法的角度来看甚至不能满足定解条件。
然后 PINN 要做的,就是对解 ,用神经网络进行逼近。将这个解用神经网络参数化表达为 ,那么就是要寻找这组参数 ,使得:
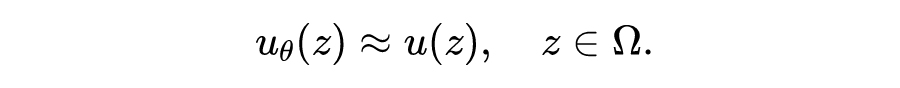
通常 具有多层感知机或者加入特殊结构的变种,这里仍然以多层感知机为例:
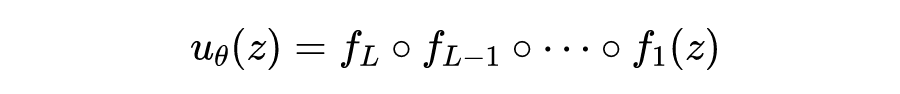
除最后一层外,其余的各层都是“线性变换+激活函数层”。这里的时空信息都被包含在 中,也就可以关于 进行自动微分运算来表达 这些微分算子。这只是个最基本的模型,也就是 Raissi 2017 年底提出的一个网络模型,目前也被使用得最多。其他加入了 Resnet、soft-attention、Echo State Network 的结构也不鲜见,总之,这类结构可以对 求自动微分。
深度学习一些其他网络结构,比如 CNN、RNN,通常并没有直接可供直接输入空间或时间 的入口,而是将空间或时间的信息直接嵌入到网络本身的结构中。CNN 类方法的图像信号天然包含空间信息,RNN 类方法的处理单元天然包含时间信息。
然后依据“内嵌物理知识”这一思想,将微分方程的三个算子 以离散(差分)的方式而不是自动微分的方式嵌入到损失函数中,有时这种内嵌物理的方式会被它们的作者称为是“弱监督”、“自监督”或者“无监督”。狭义的 PINN 并不包含这类不使用自动微分的结构,虽然“内嵌物理”的思想上并没有太大区别,比如这篇:
Wang, Nanzhe, Haibin Chang, and Dongxiao Zhang. "Theory-guided auto-encoder for surrogate construction and inverse modeling." Computer Methods in Applied Mechanics and Engineering 385 (2021): 114037.
总之,神经网络 在定义方程三个公式中的残差,就可以引出由三项损失加权得到的总损失:
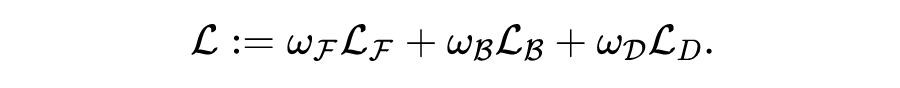
这三项其实比较笼统,还可以加入正则化项,以及其他各种先验信息,对于具体问题,细分下来有十多项也正常。最后变成了这样一个优化问题:
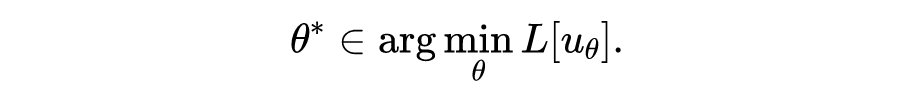
注意这跟之前提到的 Kansa 方法在计算上有了重大区别,对于线性微分方程,Kansa 方法通常也会导出线性方程组(矩阵),从而可以使用线性方程求解器对方程进行求解。但 PINN 这种神经网络不行,即使对于线性方程,也不得不使用非线性求解器(迭代优化器),比如 L-BFGS,或者神经网络训练中用得更多的 SGD、Adam 等。非线性问题的求解通常比线性问题难,这是 PINN 计算效率上一个避不开的障碍。
从这么看来,PINN 确实不是太过于新奇的东西,前人肯定想到过,这也确实如此。至少在 1994 年的文献中已经有使用 MLP 求解二维 Poisson 方程的例子:
Dissanayake, M. W. M. G., and Nhan Phan‐Thien. "Neural‐network‐based approximations for solving partial differential equations." communications in Numerical Methods in Engineering 10.3 (1994): 195-201.
当年或许还没有诸如 Pytorch、Tensorflow 或者 RTX 3090 之类的软硬工具,数值计算科学家们大概还沉迷于 Fortran 艺术中,“思维没有现在这么活络”,加上大数据的时代并没有到来,因此对这个方法并没有太大需求,导致了在后续一段时间内也一直没有太大发展。直到 2018 年开始,也就是 Raissi 他们在 Arxiv 挂出 PINN 不久,这篇文章开始迎接远超二十多年来积累到的引用量。
Raissi, Maziar, Paris Perdikaris, and George Em Karniadakis. "Physics informed deep learning (part i): Data-driven solutions of nonlinear partial differential equations." arXiv preprint arXiv:1711.10561 (2017).
上面这篇文章并没有总结早期基于神经网络的 PDE 求解器,比如忽略了前面 94 年那篇。如果想了解早期的神经网络发展,倒是可以参考 Lu 的一个综述:
Lu, Lu, et al. "DeepXDE: A deep learning library for solving differential equations." SIAM Review 63.1 (2021): 208-228.
好了,先小结一下以上内容。
大家都知道 PINN 是一种(深度)网络,在定义时空区域中给定一个输入点,在训练后在微分方程的该点中产生估计的解。
结合对控制方程的嵌入得到残差,利用残差构造损失项就是 PINN 的一项不太新奇的新奇之处了。本质原理就是将方程(也就是所谓的物理知识)集成到网络中,并使用来自控制方程的残差项来构造损失函数,由该项作为惩罚项来限制可行解的空间。
用 PINN 来求解方程并不需要有标签的数据,比如先前模拟或实验的结果。从这个角度,对 PINN 在深度学习中的地位进行定位的话,大概是处于无监督、自监督、半监督或者弱监督的地位,这几个不尽相同的说法在不同语境下都有文献提过。
PINN 算法本质上是一种无网格技术,通过将直接求解控制方程的问题转换为损失函数的优化问题来找到偏微分方程解。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3084
3084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









