







 本文介绍了任务导向型对话系统的研究背景和最新进展,特别是对话管理模型的挑战与解决方案。文章探讨了对话状态跟踪器(DST)和对话策略在可拓展性方面的改进,如神经信度跟踪模型、增量学习对话系统,以及如何处理变化的用户意图、槽位和系统动作。此外,还讨论了标注数据少的问题,提出了机器自动标注和对话结构挖掘的方法。最后,文章提到了对话管理模型在强化学习、数据效率和实际应用中的研究方向。
本文介绍了任务导向型对话系统的研究背景和最新进展,特别是对话管理模型的挑战与解决方案。文章探讨了对话状态跟踪器(DST)和对话策略在可拓展性方面的改进,如神经信度跟踪模型、增量学习对话系统,以及如何处理变化的用户意图、槽位和系统动作。此外,还讨论了标注数据少的问题,提出了机器自动标注和对话结构挖掘的方法。最后,文章提到了对话管理模型在强化学习、数据效率和实际应用中的研究方向。

作者丨戴音培、虞晖华、蒋溢轩、唐呈光、李永彬、孙健
单位丨阿里巴巴-达摩院-小蜜Conversational AI团队,康奈尔大学
对话管理模型背景
从人工智能研究的初期开始,人们就致力于开发高度智能化的人机对话系统。艾伦·图灵(Alan Turing)在 1950 年提出图灵测试 [1],认为如果人类无法区分和他对话交谈的是机器还是人类,那么就可以说机器通过了图灵测试,拥有高度的智能。
第一代对话系统主要是基于规则的对话系统,例如 1966 年 MIT 开发的 ELIZA 系统 [2] 是一个利用模版匹配方法的心理医疗聊天机器人,再如 1970 年代开始流行的基于流程图的对话系统,采用有限状态自动机模型建模对话流中的状态转移。它们的优点是内部逻辑透明,易于分析调试,但是高度依赖专家的人工干预,灵活性和可拓展性很差。
随着大数据技术的兴起,出现了基于统计学方法的数据驱动的第二代对话系统(以下简称统计对话系统)。在这个阶段,增强学习也开始被广泛研究运用,其中最具代表性的是剑桥大学 Steve Young 教授于 2005 年提出的基于部分可见马尔可夫决策过程(Partially Observable Markov Decision Process , POMDP)的统计对话系统 [3]。该系统在鲁棒性上显著地优于基于规则的对话系统,它通过对观测到的语音识别结果进行贝叶斯推断,维护每轮对话状态,再根据对话状态进行对话策略的选择,从而生成自然语言回复。
POMDP-based 对话系统采用了增强学习的框架,通过不断和用户模拟器或者真实用户进行交互试错,得到奖励得分来优化对话策略。统计对话系统是一个模块化系统,它避免了对专家的高度依赖,但是缺点是模型难以维护,可拓展性也比较受限。
近些年,伴随着深度学习在图像、语音及文本领域的重大突破,出现了以运用深度学习为主要方法的第三代对话系统,该系统依然延续了统计对话系统的框架,但各个模块都采用了神经网络模型。
由于神经网络模型表征能力强,语言分类或生成的能力大幅提高,因此一个重要的变化趋势是自然语言理解的模型从之前的产生式模型(如贝叶斯网络)演变成为深度鉴别式模型(如 CNN、DNN、RNN)[5],对话状态的获取不再是利用贝叶斯后验判决得到,而是直接计算最大条件概率。在对话策略的优化上大家也开始采用深度增强学习模型 [6]。
另一方面,由于端到端序列到序列技术在机器翻译任务上的成功,使得设计端到端对话系统成为可能,Facebook 研究者提出了基于记忆网络的任务对话系统 [4],为研究第三代对话系统中的端到端任务导向型对话系统提出了新的方向。总的来说,第三代对话系统效果优于第二代系统,但是需要大量带标注数据才能进行有效训练,因此提升模型的跨领域的迁移拓展能力成为热门的研究方向。
常见的对话系统可分为三类:聊天型,任务导向型和问答型。聊天型对话的目标是要产生有趣且富有信息量的自然回复使得人机对话可以持续进行下去 [7]。问答型对话多指一问一答,用户提出一个问题,系统通过对问题进行解析和知识库查找以返回正确答案 [8]。任务导向型对话(以下简称任务型对话)则是指由任务驱动的多轮对话,机器需要通过理解、主动询问、澄清等方式来确定用户的目标,调用相应的 API 查询后,返回正确结果,完成用户需求。
通常,任务型对话可以被理解为一个序列决策过程,机器需要在对话过程中,通过理解用户语句更新维护内部的对话状态,再根据当前的对话状态选择下一步的最优动作(例如确认需求,询问限制条件,提供结果等等),从而完成任务。
任务型对话系统从结构上可分成两类,一类是 pipeline 系统,采用模块化结构 [5](如图 1),一般包括四个关键模块:
自然语言理解(Natural Language Understanding, NLU):对用户的文本输入进行识别解析,得到槽值和意图等计算机可理解的语义标签。
对话状态跟踪(Dialog State Tracking, DST):根据对话历史,维护当前对话状态,对话状态是对整个对话历史的累积语义表示,一般就是槽值对(slot-value pairs)。
对话策略(Dialogue Policy):根据当前对话状态输出下一步系统动作。一般对话状态跟踪模块和对话策略模块统称为对话管理模块(Dialogue manager, DM)。
自然语言生成(Natural Language Generation, NLG):将系统动作转换成自然语言输出。
这种模块化的系统结构的可解释性强,易于落地,大部分业界的实用性任务型对话系统都采用的此结构。但是其缺点是不够灵活,各个模块之间相对独立,难以联合调优,适应变化的应用场景。并且由于模块之间的误差会层层累积,单一模块的升级也可能需要整个系统一起调整。
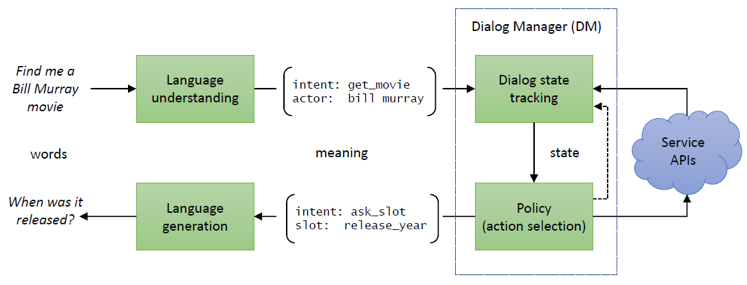
▲ 图1. 任务导向型对话系统的模块化结构 [41]
任务型对话系统的另一种实现是端到端系统,也是近年来学界比较热门的方向 [9][10][11](如图 2),这类结构希望训练一个从用户端自然语言输入到机器端自然语言输出的整体映射关系,具有灵活性强、可拓展性高的特点,减少了设计过程中的人工成本,打破了传统模块之间的隔离。然而,端到端模型对数据的数量和质量要求很高,并且对于填槽、API 调用等过程的建模不够明确,现阶段业界应用效果有限,仍处在探索中。
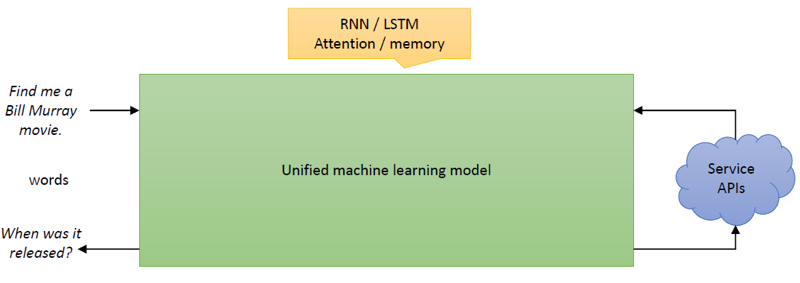
▲ 图2. 任务导向型对话系统的端到端结构 [41]
随着用户对产品体验的要求逐渐提高,实际对话场景更加复杂,对话管理模块也需要更多的改进和创新。传统的对话管理模型通常是建立在一个明确的话术体系内(即先查找再问询最后结束),一般会预定义好系统动作空间、用户意图空间和对话本体,但是实际中用户的行为变化难测,系统的应答能力十分有限,这就会导致传统对话系统可拓性差的问题(难以处理预定义之外的情况)。
另外,在很多的真实业界场景,存在大量的冷启动问题,缺少足量的标注对话数据,数据的清洗标注成本代价高昂。而在模型训练上,基于深度增强学习的对话管理模型一般都需要大量的数据,大部分论文的实验都表明,训练好一个对话模型通常需要几百个完整的对话 session,这样低下的训练效率阻碍了实际中对话系统的快速开发和迭代。
综上,针对传统对话管理模型的诸多局限,近几年学界和业界的研究者们都开始将焦点放在如何加强对话管理模型的实用性上,具体来说有三大问题:
可拓展性差
标注数据少
训练效率低
我们将按照这三个方向,为大家介绍近期最新的研究成果。
对话管理模型研究前沿介绍
对话管理模型痛点一:可拓展性差
如前文所述,对话管理器由两部分组成:对话状态跟踪器(DST)和对话策略(dialog policy)。
传统的 DST 研究中,最具代表的是剑桥大学的学者们在 2017 年提出的神经信度跟踪模型(neural belief tracker, NBT)[12],利用神经网络来解决单领域复杂对话的对话状态跟踪问题。NBT 通过表征学习(representation learning)来编码上轮系统动作、本轮用户语句和候选槽值对,在高维空间中计算语义的相似性,从而检测出本轮用户提到的槽值。因此 NBT 可以不依赖于人工构建语义词典,只需借助槽值对的词向量表示就能识别出训练集未见但语义上相似的槽值,实现槽值的可拓展。
后续地,剑桥学者们对 NBT 进一步改进 [13] [44],将输入的槽值对改成领域-槽-值三元组,每轮识别的结果采用模型学习而非人工规则的方法进行累积,所有数据采用同一个模型训练,从而实现不同领域间的知识共享,模型的总参数也不随领域数目的增加而增加。
在传统的 Dialogue Policy 研究领域中,最具代表性的是剑桥学者们 [6] [14] 提出的基于 ACER 方法的策略优化。通过结合 Experience replay 技巧,作者分别尝试了 trust region actor-critic 模型和 episodic natural actor-critic 模型,验证了 AC 系列的深度增强学习算法在样本利用效率、算法收敛性和对话成功率上都达到了当时最好的表现。
然而传统的对话管理模型在可拓展性方面仍需改进,具体在三个方面:1)如何处理变化的用户意图,2)如何变化的槽位和槽值,3)如何处理变化的系统动作。
变化的用户意图
在实际应用场景中,时常会出现由于用户意图未被考虑到,使得对话系统给出不合理回答的情况。如图 3 所示的例子,用户的“confirm”意图未被考虑,这时就需要加入新的话术来帮助系统处理这样的情况。

▲ 图3. 出现新意图的对话实例 [15]
一旦出现训练集未见的新用户意图时,传统模型由于输出的是表示旧意图类别的固定 one-hot 向量,若要包含新的意图类别,向量就需要进行改变,对应的新模型也需要进行完全的重训练,这种情况会降低模型的可维护性和可拓展性。
论文 [15] 提出了一种“老师-学生”的学习框架来缓解这一问题,他们将旧模型和针对新用户意图的逻辑规则作为“老师”,新模型作为“学生”,构成一个“老师-学生”训练架构。
该架构使用了知识蒸馏技术,具体做法是:对于旧的意图集合,旧模型的概率输出直接指导训练新模型;对于新增的意图,对应的逻辑规则作为新的标注数据来训练新模型。这样就使得在新模型不再需要与环境进行新的交互重新训练了。论文在 DSTC2 数据集上进行实验,首先选择故意去掉 confirm 这个意图,然后再将它作为新意图加入对话本体中,依次验证新模型是否具有很好的适应能力。
图 4 是实验结果,论文新模型(即 Extended System)、直接在包含所有意图的数据训练的模型(即 Contrast System)和旧模型进行比较,实验证明新模型对新意图的识别正确率在不同噪声情况下都不错的扩展识别新意图的能力。
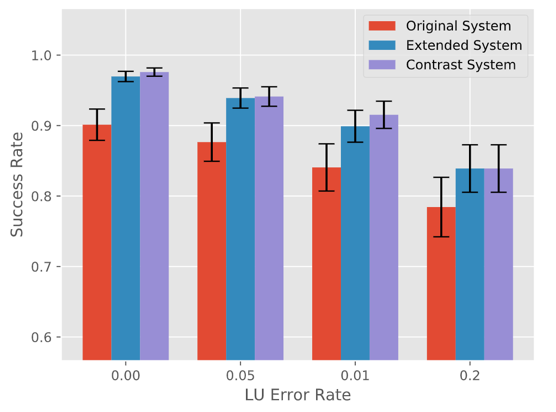
▲ 图4. 不同噪声设置下各种模型的比较
当然这种架构仍然需要对系统进行一定的训练,[16] 提出一种语义相似性匹配的模型 CDSSM 能够在不依赖于标注数据以及模型重新训练的前提下,解决用户意图拓展的问题。
CDSSM 先利用训练集数据中用户意图的自然描述直接学习出一个意图向量(intent embedding)的编码器,将任意意图的描述嵌入到一个高维语义空间中,这样在测试时模型可以直接根据新意图的自然描述生成对应的意图向量,进而再做意图识别。
在后面的内容我们可以看到,有很多提高可拓展性的模型均采用了类似的思想,将标签从模型的输出端移到输入端,利用神经网络对标签(标签命名本身或者标签的自然描述)进行语义编码得到某种语义向量再进行语义相似性的匹配。
[43] 则给出了另外一种思路,它通过人机协同的方式,将人工客服的角色引入到系统线上运行的阶段来解决训练集未见的用户意图的问题。模型利用一个额外的神经判决器根据当前模型提取出来的对话状态向量来判断是否请求人工,如果请求则将当前对话分发给线上人工客服来回答,如果不请求则由模型自身进行预测。
由于通过数据学习出的判决器有能力对当前对话是否包含新意图作一定的判断,同时人工的回复默认是正确的,这种人机协同的方式十分巧妙地解决了线上测试出现未见用户行为的问题,并可以保持比较高对话准确率。
变化的槽位和槽值
在多领域或复杂领域的对话状态跟踪问题中,如何处理槽位与槽值的变化一直是一个难题。对于有的槽位而言,槽值可能是不可枚举的(这里的不可枚举指的是槽值没有限制,或可取值过多),例如,时间、地点和人名,甚至槽值集合是动态变化的,例如航班、电影院上映的电影。在传统的对话状态跟踪问题中,通常默认槽位和槽值的集合固定不变,这样就大大降低了系统的可拓展性。
针对槽值不可枚举的问题,谷歌研究者 [17] 提出了一个候选集(candidate set)的思路。对每个槽位,都维护一个有总量上限的候选集,它包含了对话截止目前最多个可能的槽值,并赋于每个槽值一个分数以表示用户在当前对话中对该槽值的偏好程度。
系统先利用双向 RNN 模型找出本轮用户语句包含的中某个槽位的槽值,再将它和候选集中已有的槽值进行重新打分排序,这样每轮的 DST 就只需在一个有限的槽值集合上进行判决,从而解决不可枚举槽值的跟踪问题。针对未见槽值的跟踪问题,一般可以采用序列标注的模型 [18],或者选择神经信度跟踪器 [12] 这样的语义相似匹配模型。
以上是槽值不固定的情况,如果对话本体中槽位也变化呢?论文 [19] 采用了槽位描述编码器(slot description encoder),对任何槽(已见的、未见的)的自然语言描述进行编码,得到表示该槽的语义向量,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









