








©PaperWeekly 原创 · 作者 | 张一帆
学校 | 华南理工大学本科生
研究方向 | CV,Causality
本文针对非自回归翻译模型提出了一个新的损失函数:order-agnostic cross entropy(OAXE),这种交叉熵损失函数忽略了词与词的顺序,将 NAT 看成了一个集合预测的问题,基于模型预测和目标标签之间的最佳可能对齐计算交叉熵损失。
为了解决由于次序忽略带来的问题,文中提出了使用交叉熵损失 pretrain 模型再使用 OAXE finetune 以及对 confidence 较小的预测进行截断两种正则化的策略,极大的提高了翻译的性能。

论文标题:
Order-Agnostic Cross Entropy for Non-Autoregressive Machine Translation
论文链接:
https://arxiv.org/abs/2106.05093
代码链接:
https://github.com/tencent-ailab/ICML21_OAXE

Methodology
先来直观的看一下本文的损失函数和已有的 loss 有什么本质的区别。传统的交叉熵损失对每一个错误的词序都会引入惩罚,之前的工作AXE会对词进行单调的对齐,而本文直接找最优的对齐方式。

那么我们将传统的交叉熵损失写为:
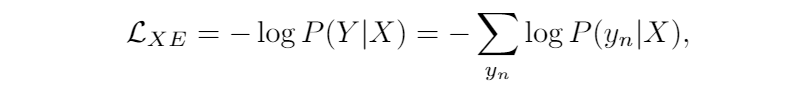
本文提出的 loss 其实很简单:
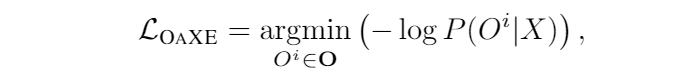
其中
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1720
1720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









