







 本文介绍了DETR及其变体在目标检测中的应用,包括ViT-FRCNN、TSP-FCOS、TSP-RCNN和Deformable DETR。DETR的缺点在于训练时间长和小物体检测效果不佳,文中提到的变体通过改进交叉注意力和引入可变形注意力等机制,提高了训练速度和检测准确性。Deformable DETR采用可变形注意力模块,解决了DETR的收敛速度和小物体检测问题。
本文介绍了DETR及其变体在目标检测中的应用,包括ViT-FRCNN、TSP-FCOS、TSP-RCNN和Deformable DETR。DETR的缺点在于训练时间长和小物体检测效果不佳,文中提到的变体通过改进交叉注意力和引入可变形注意力等机制,提高了训练速度和检测准确性。Deformable DETR采用可变形注意力模块,解决了DETR的收敛速度和小物体检测问题。

©PaperWeekly 原创 · 作者|张一帆
学校|华南理工大学本科生
研究方向|CV,Causality
DETR 在短短一年时间收获了 200+ 引用量,可谓是风靡一时,各种变体层出不穷,这篇文章主要总结了几篇论文来研究各种关于 DETR 的改进以及它存在的问题。

DETR

论文标题:
End-to-End Object Detection with Transformers
收录会议:
ECCV 2020
论文链接:
https://arxiv.org/abs/2005.12872
代码链接:
https://github.com/facebookresearch/detr
facebook 力作,网上类似的解读已经很多了,将 object detection 视为一个 set prediction 的问题。个人觉得他吸引人的地方在于简洁优雅的训练方式,无需任何后处理,实现非常简单。当然 DETR 的缺点也很明显,需要较长的训练时间,而且在小物体上的检测结果并不尽如人意。之后这几篇 paper 也是从不同的角度相对这个问题作出回应。
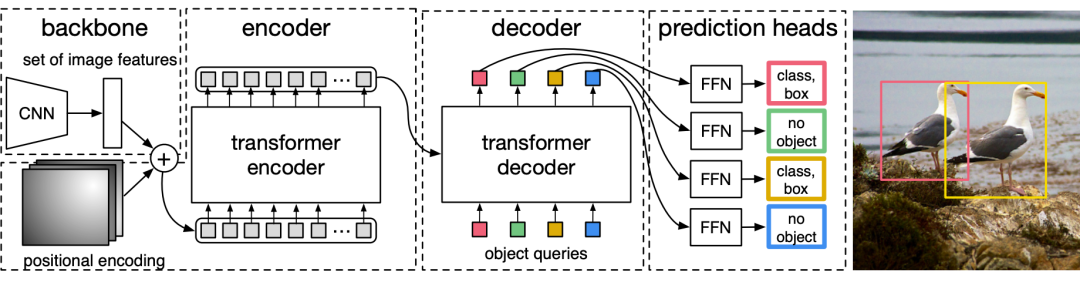

ViT-FRCNN

论文标题:
Toward Transformer-Based Object Detection
论文链接:
https://arxiv.org/abs/2012.09958
文章提出了 ViT-FRCNN 模型,听名字就知道是 ViT 与 FRCNN 的结合。我们先来看看 ViT。
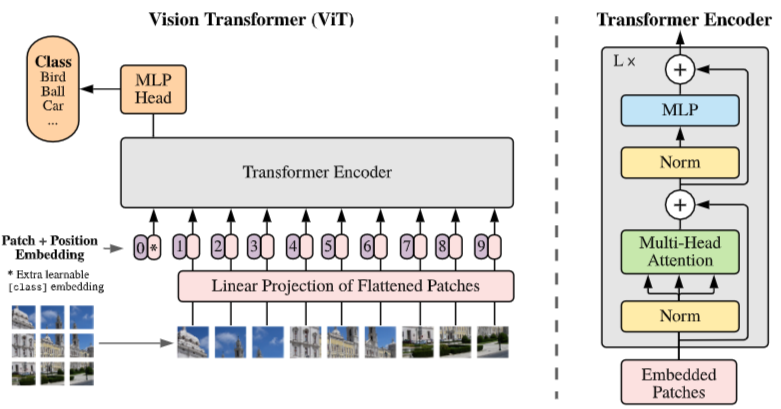
我们知道 ViT 其实只有 encoder,但是他很好地完成了分类这一任务,他只使用 cls token 做分类,其余的 image patch 生成的 token 抛弃掉了。但是这些 token 其实包含大量的局部信息,非常适合用来做目标定位。所以只要能利用好这些 token,我们是不是可以不需要 decoder 呢?答案是肯定的。
ViT-FRCNN,具体与 DETR 的不同之处主要体现在以下几个方面:
无需 CNN 提取特征,采用了 ViT 的输入方式直接将 image 切割成 patch 然后做 Linear projection 即可变为输入。
对于 encoder 产生的各个 embedding,ViT-FRCNN 将他们重新组织成为 feature map。这样我们就可以用 Faster-RCNN 的方法,先在 feature map 上做 region proposal,然后对这些 RoI 做分类和定位。
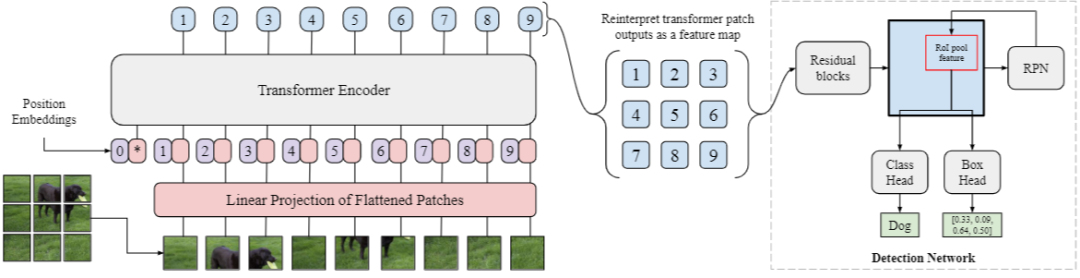
总的来看,就是将 Faster-RCNN 的 backbone 替换为了 transformer,文章也没有与 DETR 进行深入比较。

TSP-FCOS & TSP-RCNN

论文标题:
Rethinking Transformer-based Set Prediction for Object Detection
论文链接:
https://arxiv.org/abs/2011.10881
文章研究了 DETR 训练中优化困难的原因:Hungarian loss 和 Transformer cross-attention 机制等问题。为了克服这些问题,还提出了两种解决方案,即 TSP-FCOS 和 TSP-RCNN。实验结果表明所提出的方法不仅比原始 DETR 训练更快,准确性方面也明显优于 DETR。
3.1 是什么使得DETR收敛如此之慢?
作者首先猜测可能是因为使用了二分图匹配来计算两个集合的相似度,但是试验结果表明问题这里的问题其实不算严重。相反,decoder 中的 cross attention 才是罪魁祸首。我们知道 attention map 在初始化的时候是非常均匀的,但是随着他不断收敛会变得越来越稀疏。
相关研究表明,如果我们将 attention 替换为更加系数的算子比如卷积将会大大加快收敛的速度。所以这里的 cross-attention 到底影响有多大,文中给出了以下实验:
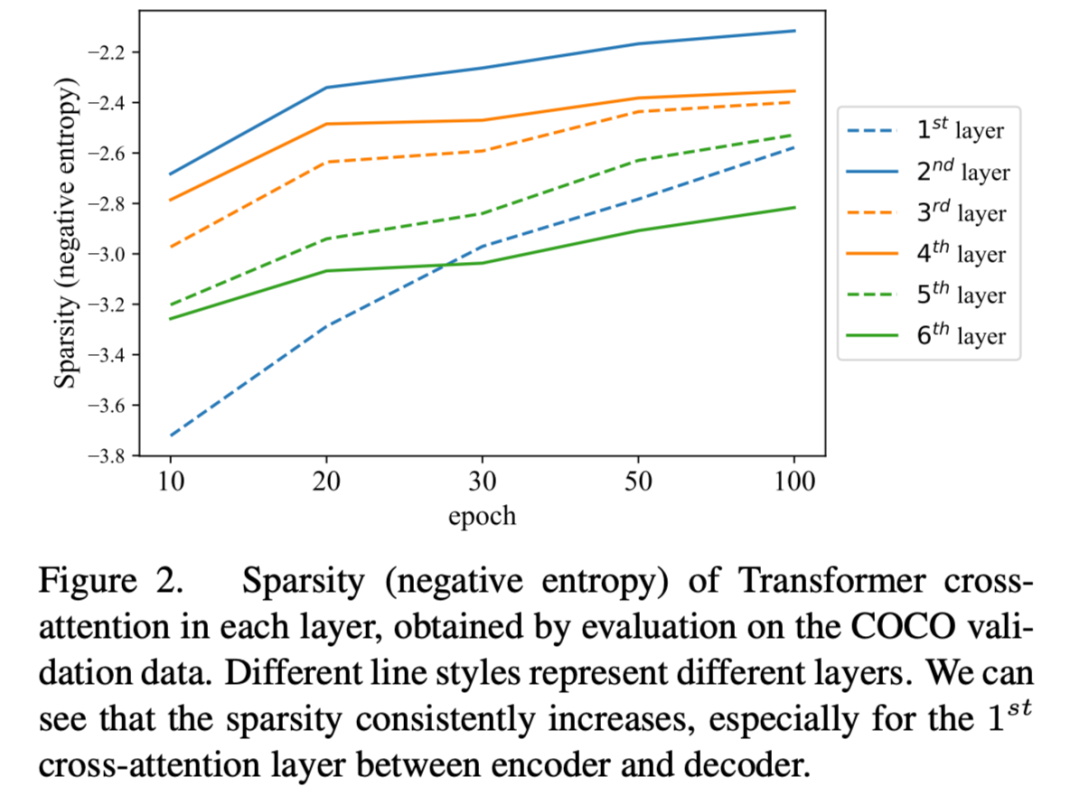
我们可以看到,cross-attention 的稀疏性持续增加,即使在 100 次训练后也没有收敛。这意味着 DETR 的交叉注意部分是一个导致收敛速度慢的主导因素。
3.2 我们一定需要交叉注意力吗?
通过设计只有 encoder 的网络,即 encode 出来的 embedding 直接用来做分类和定位(结构图如下),因为 encoder 其实就是一个自注意力的网络,所以DETR训练的方式可以照搬过来。

我们可以得到下图的结果,可以看到其实 AP 下降的并不多,相反对小物体而言我们有非常大的提升,但是对大物体而言效果有所下降。
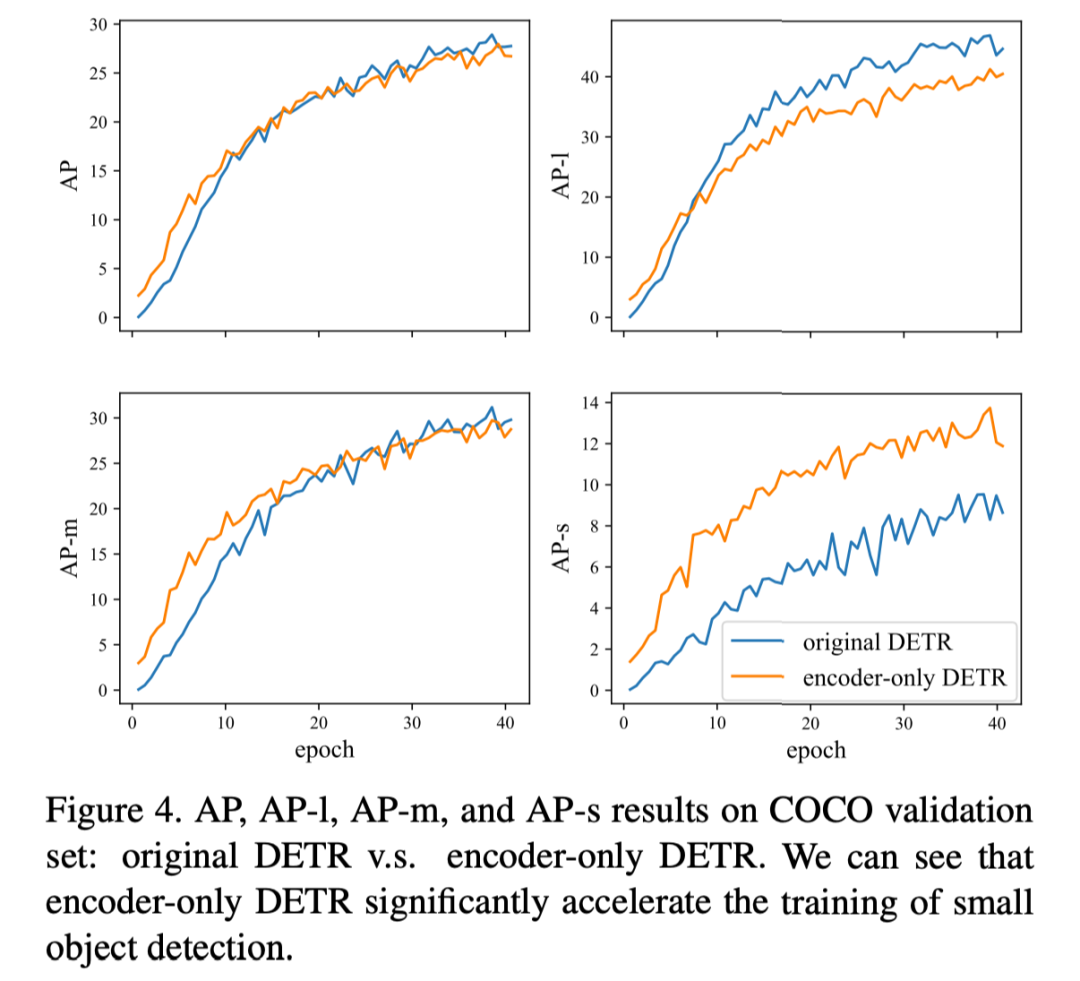
文中认为一种可能的解释是,一个大对象可能包含太多潜在的匹配特征点,这对于只使用编码器的 DETR 来说是很难处理的。另一个可能的原因是编码器处理的单一特征映射对于预测不同尺度的对象是不鲁棒的(融入 FPN 可能能解决这个问题)。
3.3 如何解决上述问题?
作者提出了两种不同的架构,这两种架构都融入了 FPN 对 CNN 提取出来的特征图进行处理来缓解 Encoder-Only DETR 对大尺度物体不敏感的缺陷。
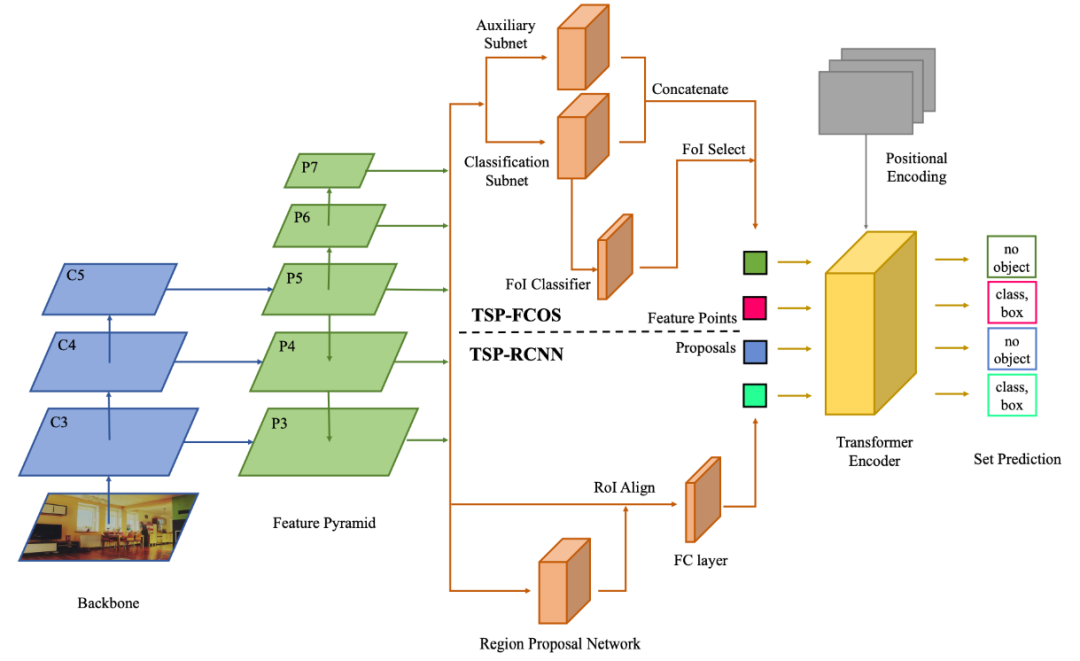
TSP-FCOS:在 backbone 和 encoder 之间加上了 head;
TSP-RCNN:在 backbone 和 encoder 之间加上了 RoIAlign;
主要与 DETR 的区别在于
在输入 encoder 之前都会从图像金字塔中抽取 RoI,FoI 作为 encoder 的输入,这一步显然会增加定位精度,但是同时模型也变得更加复杂了。
针对 RoI 采取了特殊的 position encoding (根据 box 的中心点,长宽高设计 encoding)
将传统 FCOS 和 RCNN 匹配 ground truth 和预测 box 的方法融入 DETR 中,进一步提高匹配的效果与效率。
3.4 实验
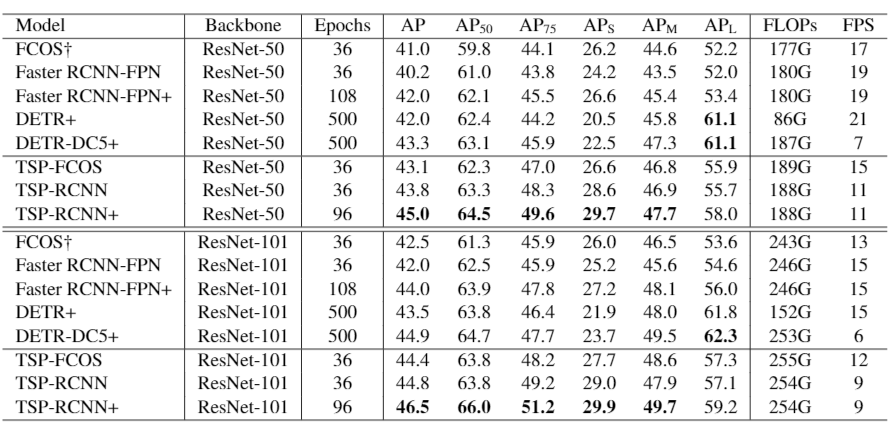
下表比较充分地说明了训练精度和速度都有所提升。
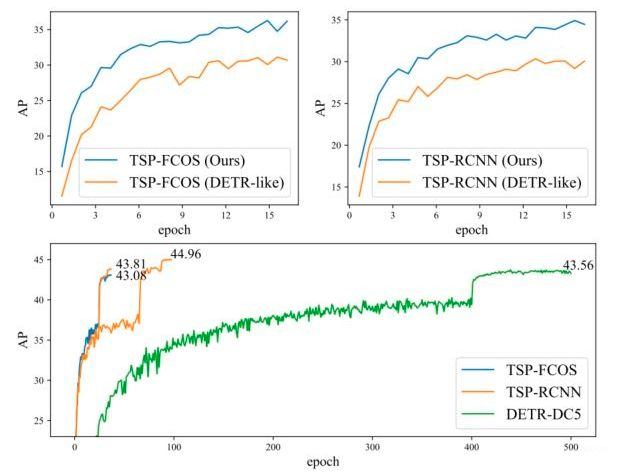
作者还贴心的画了一张图,上面两张图比较了文中提出的损失函数收敛速度的影响(DETR-Like)就是直接二分匹配。下面的图展示了文中两个model与DETR收敛速度的比较。
3.5 总结与讨论
上两篇文章的区别在哪呢?ViT-FRCNN 使用 transformer encoder 提取特征,将重组后的 feature map 扔进 RCNN 的检测网络中得到最终结果。而 TSP-RCNN 先用传统方法将特征处理好,找到 RoI 或者 FoI,然后将他们扔到 transformer encoder 中,二者可能都有提升,但还是大量依赖与传统检测的各种处理方法。Transformer 在他们之中扮演的角色仿佛也不是那么重要。

Deformable DETR

论文标题:
Deformable DETR: Deformable Transformers for End-to-End Object Detection
收录会议:
ICLR 2021
论文链接:
https://arxiv.org/abs/2010.04159
代码链接:
https://github.com/DeppMeng/Deformable-DETR
文章先 argue 了两个 DETR 面临的主要问题
训练周期长,收敛速度慢,比 Faster-RCNN 慢 20 倍。这主要是因为 attention map 要从均匀到稀疏这个训练过程确实非常耗时。
小物体检测效果差,FPN 可以减缓这个缺陷,但是由于 Transformer 的复杂度是 ,高分辨率对 DETR 来说会带来不可估量的内存和计算速度增加。
而可变形卷积 deformable convolution 就是一种有效关注稀疏空间定位的方式,可以克服以上两个缺点。
4.1 Deformer Attention
作者首先提出了 Deformer Attention 模块,attention 难就难在他是一个密集连接,但是需要学到非常稀疏的知识,Deformer 直接将需要学习的知识定义为稀疏的。与传统 attention 的最大区别在于:Attention weight 不再基于 query 和 key 的 pairwise 对比,而是只依赖于 query。
在实现上,每个 query 会被映射到 的特征空间(M 是 attention head 的数目,K 是我们预设的 key 的数目 e),前 个通道编码采样的 offset(对 个 key 值分别有一对 offset),决定每一个 query 应该找哪些 key,最后
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6266
6266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









