








©PaperWeekly 原创 · 作者 | Maple小七
学校 | 北京邮电大学硕士生
研究方向 | 自然语言处理
最近,以 DPR 为代表的稠密检索模型在开放域问答上取得了巨大的进展,然而,目前的稠密检索模型还无法完全替代 BM25 这类稀疏检索模型。本文作者构建了一个以实体为中心的问答数据集:EntityQuestions,并发现 DPR 模型在该数据集上的表现大幅落后于 BM25。经过分析,作者发现 DPR 只能泛化到那些具有常见实体和特定模板的问题上,并发现简单的数据增强策略无法提升模型的泛化性能,而训练一个更稳健的段落编码器和多个特定的问题编码器可以更好地缓解这个问题。

论文标题:
Simple Entity-Centric Questions Challenge Dense Retrievers
论文链接:
https://arxiv.org/abs/2109.08535
代码链接:
https://github.com/princeton-nlp/EntityQuestions

Introduction
虽然基于稠密向量检索的 DPR(dense passage retriever)模型在许多 QA 数据集上的整体表现大幅度超越了基于稀疏向量检索的 BM25,但是深度学习模型长尾泛化能力的不足一直是个业界难题。人们常常能够观察到模型在某些具有特定规律的 case 上表现不佳,并且这些 bad case 很难修复,常常只能靠一些非深度学习的算法来兜底。
本文正是构建了一个 DPR 表现很差但 BM25 表现很好的数据集:EntityQuestions,作者通过充分的实验表明 DPR 在以实体为中心的问题(entity-centric questions)上的泛化能力非常差。如下图所示,DPR 模型在 EntityQuestions 上的平均表现大幅低于 BM25(49.7% vs 71.2%),在某些问题类型上,DPR 和 BM25 的绝对差距可高达 60%(比如 Who is [E]'s child?)。
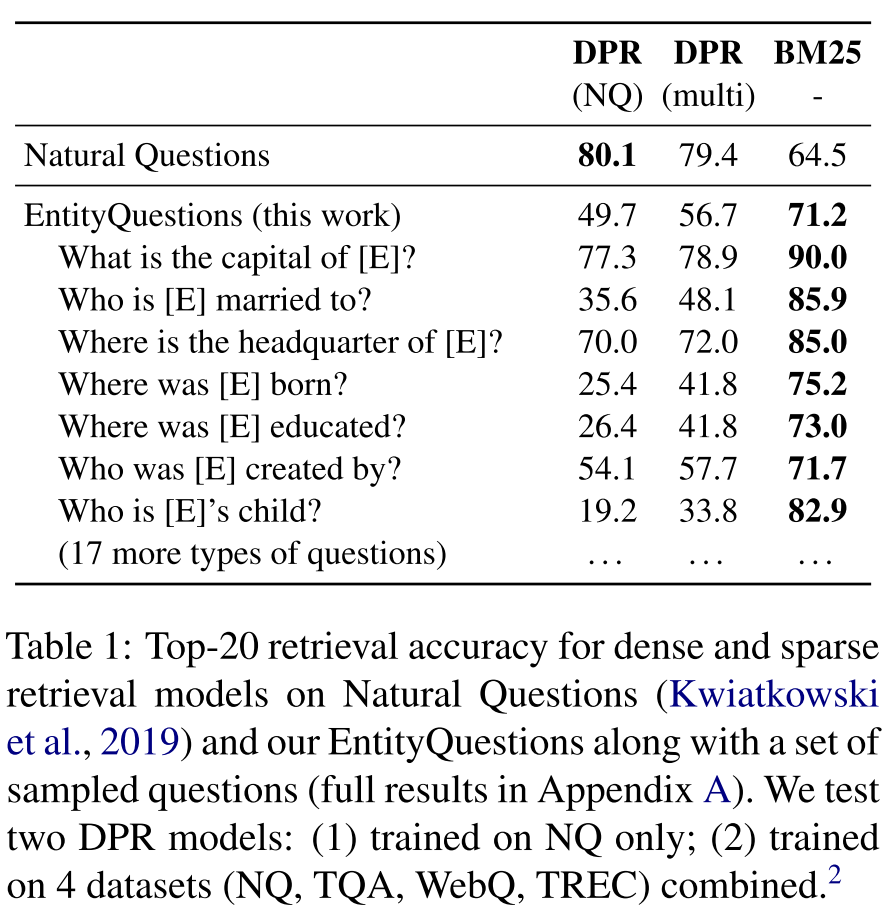

EntityQuestions
为了构建以实体为中心的问题数据集 EntityQuestions,作者从 Wikidata(基于Wikipedia 的大型知识图谱)中筛选了多个常见的关系,并通过人工设计的模板将事实三元组ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









