







DPR(2020 EMNLP)
该论文的模型主要是一个双塔结构如下所示:

整个模型的训练数据D包含m个例子,其中每个例子由一个问题
q
i
q_i
qi、一个相关段落
p
i
+
p_i^+
pi+、n个不相关段落
p
i
,
1
−
,
⋯
,
p
i
,
n
−
p_{i,1}^-,\cdots,p_{i,n}^-
pi,1−,⋯,pi,n−
D
=
{
⟨
q
i
,
p
i
+
,
p
i
,
1
−
,
⋯
,
p
i
,
n
−
⟩
}
i
=
1
m
\mathcal{D}=\left\{\left\langle q_i, p_i^{+}, p_{i, 1}^{-}, \cdots, p_{i, n}^{-}\right\rangle\right\}_{i=1}^m
D={⟨qi,pi+,pi,1−,⋯,pi,n−⟩}i=1m
loss函数:

负样本的选择方式:
- Random:从语料库中随机抽取一个passage,基本上都是跟当前question无关的;
- BM25:使用基于BM25的文本检索方式在语料库中检索跟question最相关的文本, 但要求不包含答案;
- Gold: 在训练样本中, 其他样本中的positive passage。即对于训练样本 i i i 和 j , q i j, q_i j,qi 对应的正样本 是 p i + p_i^{+} pi+, 而这个 p i + p_i^{+} pi+可以作为 q j q_j qj 的负样本。
In-batch negatives
一个批次的大小为B,则Q和P就是一个大小 B × d B\times d B×d的矩阵, S = Q P T S=QP^T S=QPT则是一个大小为 B × B B\times B B×B的矩阵,其中第i行表示 q i q_i qi和B个段落的相似度,其中 p i p_i pi是 q i q_i qi的相关段落,因此剩下的 B − 1 B-1 B−1个段落就可以当做问题 q i q_i qi的负样本段落。
REALM(2020 ICML)

knowledge Retriever:
p
(
z
∣
x
)
=
exp
f
(
x
,
z
)
∑
z
′
exp
f
(
x
,
z
′
)
p(z \mid x)=\frac{\exp f(x, z)}{\sum_{z^{\prime}} \exp f\left(x, z^{\prime}\right)}
p(z∣x)=∑z′expf(x,z′)expf(x,z)
f ( x , z ) = Embed input ( x ) ⊤ Embed doc ( z ) f(x, z)=\text { Embed }_{\text {input }}(x)^{\top} \text { Embed }_{\text {doc }}(z) f(x,z)= Embed input (x)⊤ Embed doc (z)

然后经过一个线性层降维(作者在google ai发布的blog里面显示维度降到了128):


Knowledge-Augmented Encoder:
p
(
y
∣
z
,
x
)
∝
∑
s
∈
S
(
z
,
y
)
exp
(
MLP
(
[
h
S
T
A
R
T
(
s
)
;
h
E
N
D
(
s
)
]
)
)
h
S
T
A
R
T
(
s
)
=
BERT
S
T
A
R
T
(
s
)
(
join
B
E
R
T
(
x
,
z
b
o
d
y
)
)
h
E
N
D
(
s
)
=
BERT
E
N
D
(
s
)
(
join
B
E
R
T
(
x
,
z
b
o
d
y
)
)
\begin{aligned} p(y \mid z, x) & \propto \sum_{s \in S(z, y)} \exp \left(\operatorname{MLP}\left(\left[h_{\mathrm{START}(\mathrm{s})} ; h_{\mathrm{END}(\mathrm{s})}\right]\right)\right) \\ h_{\mathrm{START}(\mathbf{s})} &=\operatorname{BERT}_{\mathrm{START}(\mathbf{s})}\left(\text { join }_{\mathrm{BERT}}\left(x, z_{\mathrm{body}}\right)\right) \\ h_{\mathrm{END}(\mathrm{s})} &=\operatorname{BERT}_{\mathrm{END}(\mathrm{s})}\left(\text { join }_{\mathrm{BERT}}\left(x, z_{\mathrm{body}}\right)\right) \end{aligned}
p(y∣z,x)hSTART(s)hEND(s)∝s∈S(z,y)∑exp(MLP([hSTART(s);hEND(s)]))=BERTSTART(s)( join BERT(x,zbody))=BERTEND(s)( join BERT(x,zbody))
Inverse Cloze Task(ICT)
P
I
C
T
(
b
∣
q
)
=
exp
(
S
retr
(
b
,
q
)
)
∑
b
′
∈
ЄATCH
exp
(
S
retr
(
b
′
,
q
)
)
P_{\mathrm{ICT}}(b \mid q)=\frac{\exp \left(S_{\text {retr }}(b, q)\right)}{\sum_{b^{\prime} \in \text { ЄATCH }} \exp \left(S_{\text {retr }}\left(b^{\prime}, q\right)\right)}
PICT(b∣q)=∑b′∈ ЄATCH exp(Sretr (b′,q))exp(Sretr (b,q))
公式(1)两边log求导的推导过程如下:

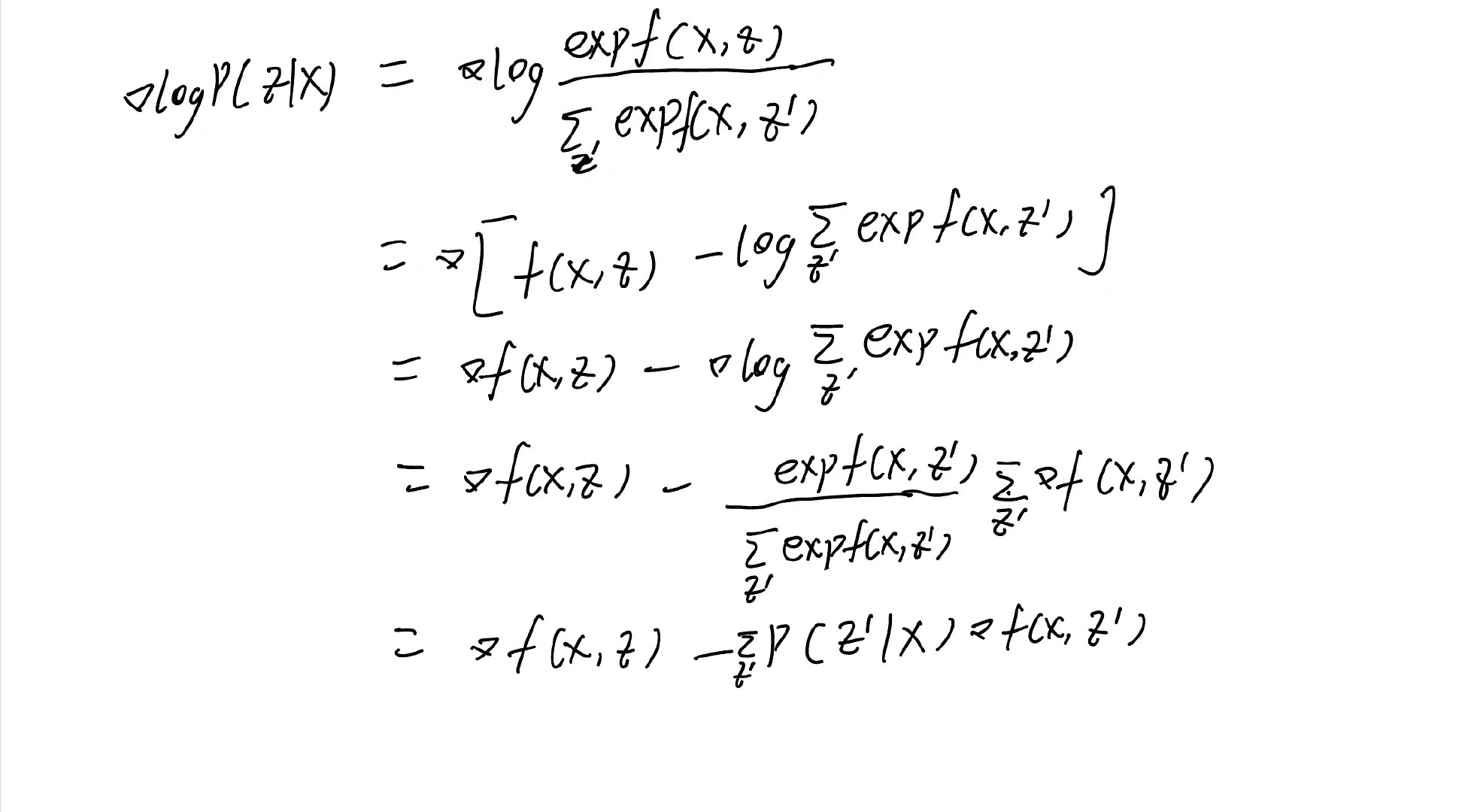














 871
871











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









