








©PaperWeekly 原创 · 作者 | 苏剑林
单位 | 追一科技
研究方向 | NLP、神经网络
在本系列的前面几篇文章中,我们已经从多个角度来理解了 VAE,一般来说,用 VAE 是为了得到一个生成模型,或者是做更好的编码模型,这都是 VAE 的常规用途。但除了这些常规应用外,还有一些“小众需求”,比如用来估计 的概率密度,这在做压缩的时候通常会用到。
本文就从估计概率密度的角度来了解和推导一下 VAE 模型。

两个问题
所谓估计概率密度,就是在已知样本 的情况下,用一个待定的概率密度簇 去拟合这批样本,拟合的目标一般是最小化负对数似然:
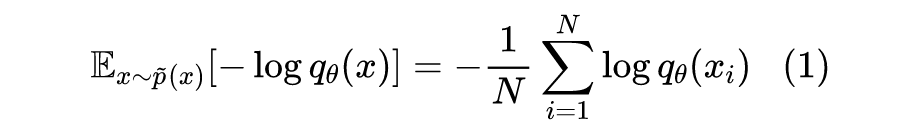
但这纯粹都只是理论形式,还有诸多问题没有解决,主要可以归为两个大问题:
1. 用什么样的 去拟合;
2. 用什么方法去求解上述目标。

混合模型
第一个问题,我们自然是希望 的拟合
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2498
2498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









