








©PaperWeekly 原创 · 作者 | 王子丰
单位 | 伊利诺伊大学香槟分校
研究方向 | AI for healthcare
EMNLP 2022 一共接收了我的三篇文章(两篇主会一篇 findings),分别是:
[1] MedCLIP: Contrastive Learning from Unpaired Medical Images and Texts
[2] PromptEHR: Conditional Electronic Healthcare Records Generation with Prompt Learning
[3] Trial2Vec: Zero-Shot Clinical Trial Document Similarity Search using Self-Supervision
今天介绍的是 [1] 这篇工作。做的内容是最近大火的图像文本联合预训练(Vision-Language pretraining)在医疗领域的应用。这篇文章的亮点主要是:
1. 探索了如何处理 False Negative 样本对预训练的影响;
2. 探索了怎么样在样本有限的情况下,最大化的扩充正负样本对来提高多模态预训练的 data efficiency。

论文标题:
MedCLIP: Contrastive Learning from Unpaired Medical Images and Text
收录会议:
EMNLP 2022
论文链接:
https://arxiv.org/abs/2210.10163
代码链接:
https://github.com/RyanWangZf/MedCLIP
代码和预训练权重见上方链接。那么接下来就是正文啦。

前情提要
CLIP [1](Contrastive Language-Image Pre-training)即图文对比预训练,是这推动这两年多模态领域大火的奠基之作。相信大家都已经比较熟悉了。
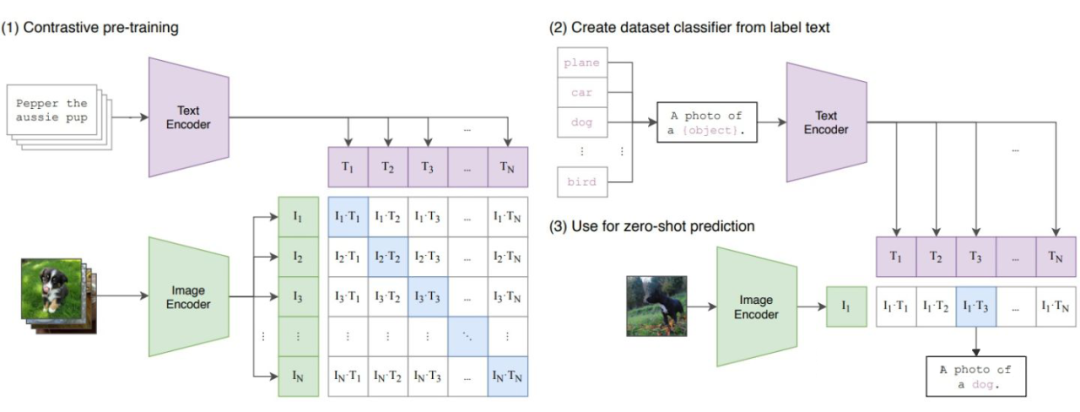
▲ CLIP 的示意图,来自原论文
在 4 亿个网络图片和对应的标题的加持下,CLIP 使用简单的 InfoNCE loss 大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









